leaf-coalesce: EXCEPTION. " Unexpected bump in size"
-
I use xcp-ng 8.2.0 and I have several unhealthy VDIs after removimg snapshots.
In /var/log/SMlog I see the next:Aug 161 14:23:04 xcp-sr121-u0112-s1 SM: [13443] lock: released /var/lock/sm/lvm-e8b61db5-e776-9b83-c051-01823799be22/91026479-cc7d-4ed2-9062-1a53e54c748c
Aug 16 14:23:04 xcp-sr121-u0112-s1 SM: [13443] ['/usr/bin/vhd-util', 'query', '--debug', '-s', '-n', '/dev/VG_XenStorage-e8b61db5-e776-9b83-c051-01823799be22/VHD-91026479-cc7d-4ed2-9062-1a53e54c748c']
Aug 16 14:23:04 xcp-sr121-u0112-s1 SM: [13443] pread SUCCESS
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] No progress, attempt: 3
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Aborted coalesce
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Iteration: 1 -- Initial size 50564555264 --> Final size 42630242816
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Iteration: 2 -- Initial size 42630242816 --> Final size 46032163328
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Iteration: 3 -- Initial size 46032163328 --> Final size 47671136768
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Iteration: 4 -- Initial size 47671136768 --> Final size 53155394048
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Unexpected bump in size, compared to minimum acheived
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Starting size was 50564555264
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Final size was 53155394048
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Minimum size acheived was 42630242816
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Removed leaf-coalesce from 91026479VHD
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] ~~~~~~~~~~~~~~~~~~~~*
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] ***********************
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] * E X C E P T I O N *
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] ***********************
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] leaf-coalesce: EXCEPTION <class 'util.SMException'>, VDI 91026479-cc7d-4ed2-9062-1a53e54c748c could not be coalesced
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] File "/opt/xensource/sm/cleanup.py", line 1774, in coalesceLeaf
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] self._coalesceLeaf(vdi)
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] File "/opt/xensource/sm/cleanup.py", line 2049, in _coalesceLeaf
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] .format(uuid=vdi.uuid))
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443]
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] ~~~~~~~~~~~~~~~~~~~~*
Aug 16 14:23:04 xcp-sr121-u0112-s1 SMGC: [13443] Leaf-coalesce failed on 91026479VHD, skippingI changed in /opt/xensource/sm/cleanup.py:
LIVE_LEAF_COALESCE_MAX_SIZE from "20 * 1024 * 1024 " up to "16384 * 1024 * 1024 "
LIVE_LEAF_COALESCE_TIMEOUT from 10 to 400
MAX_ITERATIONS_NO_PROGRESS from 3 to 6
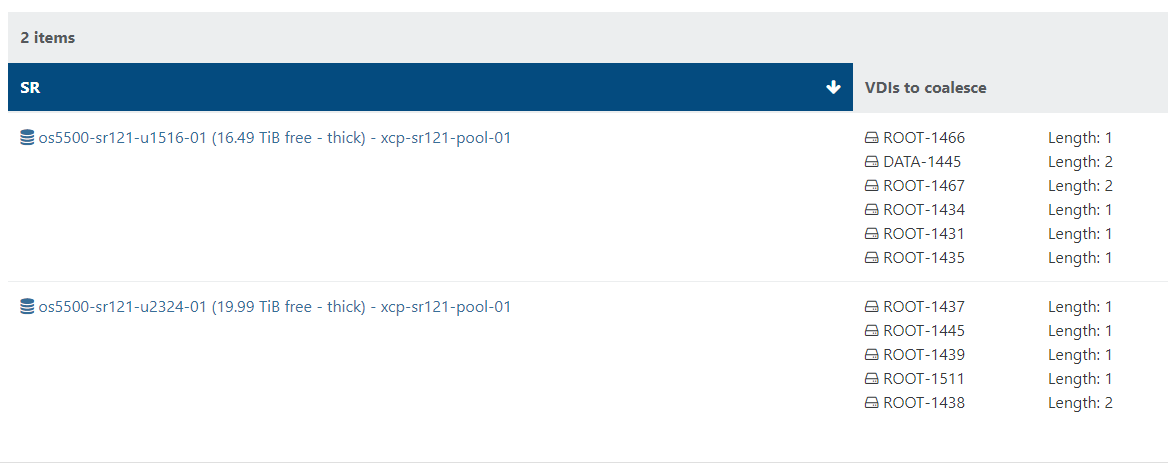
MAX_ITERATIONS from 10 to 20And I still can't get rid of "VDIs to coalesce"
Thanks!
-
Does it ring any bell @ronan-a ?
-
@olivierlambert Of course. It's a new time related to this issue: https://xcp-ng.org/forum/topic/6732/vdi-could-not-be-coalesced/7?_=1692200431466
@topsecret What's your host configuration? CPU and drive please? An overused CPU can be the cause of the problem, a slow disk, too many writes in VMs... Many factors can play a role.
-
@ronan-a This cluster based on Huawei CH121 V5 servers with Intel(R) Xeon(R) Gold 5120T CPU @ 2.20GHz, 320 Gb RAM and Intel(R) Xeon(R) Gold 6138T CPU @ 2.00GHz, 512 Gb RAM. We have more than a half free RAM and CPU on each server according to Xen Orchestra. SAS storage free capacity is about 45% (17Tb).
Problem disks capacity are about 2Tb
We can't stop virtual machines, it affects productive service -
I powered off one VM with two 2Tb disks, overall coalesce time was about 3-4 hours.
Running VM still has VDI to coalesce. I found proccess "/usr/bin/vhd-util coalesce --debug -n /dev/VG_XenStorage-de024eb7-ce14-5487-e229-7ca321b103a2/VHD-b5d6ab41-50dc-4116-a23c-e453b93ce161"
Can I run it again to parallel coalesce process? -
Hello!
Same error " Unexpected bump in size" on different servers with xcp-ng 8.2.0.
Hardware RAID5 and RAID10 used, with 8 SDD DC500M-DC600M. Only power off VM, Rescan, and wait about 8-10 minutes helps. Any solution or any updates can solve the problem?Thank you!
-
Hi,
Your SR is probably coalescing slower than you are adding data to your disk in live, and can't catch up.
You might try to use CBT-enabled backup with XO to reduce the snapshot size.
-
Thank you!
But, disk IO operations is very low during coalescing. All users are logged off from the server.
-
So I can only suppose it's a Windows guest? Those guest are always writing a non-negligible quantity, and if your coalesce speed is slower than this, then, the coalesce process will detect data has grown faster than it merged, and it will fail.
There's another possibility, to modify some coalesce timing to be more aggressive, that might solve it on your end.
Following an old feedback on Github, you can try those values: https://github.com/xcp-ng/xcp/issues/298#issuecomment-557805054
-
Thank you!
Yes, Windows VMs with guest tools installed.
-
Keep us posted on the result
")
-
Dependig on hardware, any xcp-ng 8.2.0 host must be modified, if it running Windows VMs? My xcp-ng 8.2.0 host servers has powerful disk system, based on SSD and hardware RAID controller with onboard cache.
Thank you!
-
No, it really depends on many factors. There's no universal tuning.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login