XCP-ng & XO at Vates
-
Always wanted to provide a bit of feedback on what's powering Vates IT.
You might be aware that we are relying on almost 100% self-hosted and Open Source software, see:
https://vates.tech/blog/our-self-hosting-journey-with-open-source/
And all of that is running in a colo!
Previous infrastructure
Over the past decade, we've bounced around various hosting providers - first, it was Scaleway in France, then Hetzner in Germany (and before that, OVH).
While these providers offered some killer hardware deals, it's been a real hassle when we've wanted to craft our own infrastructure or make customized storage choices. Plus, if you ever ventured beyond their "basic offers," you'd quickly watch those costs soar.
To complicate matters further, we were managing different sites across some not-so-friendly networks. This led us down the rabbit hole of using the XOA SDN controller to carve out a super-private management network for all our VMs and hosts. It did the job, but it also added an extra layer of complexity to our setup.
New Goal: Keep it Simple and Flexible
After years of cobbling together virtualized platforms, there's one piece of advice we can't stress enough: keep things simple and straightforward.
So, we set out on a mission to revamp our infrastructure, aiming for more flexibility while keeping things resilient and easy to handle. The idea was to rely on budget-friendly (but blazing-fast) off-the-shelf hardware that we could swap out without breaking a sweat.
Our Choice: Rock DC Lyon
4 years ago, we zeroed in on the Rock DC Lyon as the perfect spot for our new setup. We started by tucking our lab gear into a rack, and it's been smooth sailing since. This DC is a 2019 model and pretty darn impressive. If you want the nitty-gritty, you can check out this link, though it's in French (but has some sweet pictures!).
Hardware: EPYC at the Heart of It
Now that we had the liberty to pick our own hardware, here's what we rolled with:
Network
We went for the trusty and tested Ruckus hardware: 2x Ruckus ICX6610 units neatly stacked in an HA configuration (with 4x40G interconnects).

These babies have been rock-solid in our lab setups and now in production. With the HA pair setup, all our critical production hosts and storage platforms are linked via 10gbE to each switch, bonded. If one switch decides to ghost on us, no worries, there won't be any traffic casualties.
These units also come with some premium L3 features like VRFs, which help us keep our lab, production, and management routing tables as separate as church and state. For public production access, we're currently handling routes for 3x IPv4 blocks and one massive IPv6 block that we've divided up as we see fit. They also throw in nifty stuff like OpenFlow SDN support, which lets us play around with OpenFlow in the XCP-ng development sphere.
One sweet perk of using commodity hardware like this is its availability and price. We can stash cold spares right in our rack in case something decides to bail on us.
Storage
Staying true to the KISS principle, we designated a dedicated storage host, running TrueNAS.

Meet the host - a Dell R730, packing 128GiB RAM and 2x Xeon @ 2.4GHz CPUs, all hustling to keep TrueNAS running smoothly. One of the smartest moves we made here was opting for NFS instead of iSCSI. We've had our fair share of iSCSI-related support tickets (around 20% or more) due to misconfigurations and storage appliance hiccups. NFS, on the other hand, is a simpler protocol and gives us thin provisioning. Plus, as you can see from the numbers below, it doesn't drag down performance on modern hardware.
Our main storage repository is a mirrored pair of 2TiB Samsung 970 EVO Plus NVMe drives (for VM systems and databases), and our "slow" storage rolls with 4x 1TiB SAS HDDs (for NextCloud files and such). This whole setup connects to our backbone via a redundant pair of 10gbE connections from Intel series NICs.
It's a budget-friendly configuration (around 450USD/400EUR per NVMe drive) that delivers some serious firepower in just one VM disk:
- 140k IOPS in read and 115k in write for 4k blocks
- Chewing through 10G for read/write in 4M blocks (that's 1000 MiB/s)
And the icing on the cake? It scales even better with multiple VMs!
Compute nodes
Since we're tech enthusiasts who can't resist playing with hardware, we couldn't pass up the AMD EPYC CPUs. Let's be honest, we were also tired of constantly pushing updates to fix Intel CPU vulnerabilities.
So, we ordered 3x Dell R6515 units, each flaunting an EPYC 7302P chip with a generous 128GiB RAM. The pricing was right on the money, and this hardware packs quite a punch for our needs.
We tossed in an Intel X710-BM2 NIC (dual 10G) in each node and hooked up 2x 10G DACs per node to the Ruckus switch pair (one DAC per switch).
These nodes also came with iDRAC9 Enterprise licenses for super-easy remote management, including an HTML5-based remote KVM - no more Java woes!

XCP-ng configuration
In this straightforward setup, we lean on a redundant bond (2x10G) for all networks - management, storage, and public. Each network lives in its cozy VLAN, allowing us to logically separate them (and throw in a dedicated virtual interface in our VM for the public network). This step also plays a part in isolating our management network from our public routing.
The rest of the setup is pretty much par for the course: 2x NFS SR (one for NVMe drives, the other for HDDs).
And when it comes to our not-so-public networks, the only way in is through a jump box armed with a Wireguard VPN.
Backup
Of course, we're on the Xen Orchestra bandwagon, using it to back up all our VMs with Delta backups, all the way to another FreeNAS machine.
Note that we're cruising at some impressive speeds for these backups, thanks to our entire backbone running on 10gbE, thin provisioning, and a simplified setup.
We have 2 backup types:
- Incremental backup every 6 hours to another TrueNAS machine, hosted in a different rack & different room, in the same DC (10G speed).
- A nightly incremental replication to another DC, which is 400km away, allowing a full & fast recovery of our production in case the entire DC is destroyed.
Migration
With shiny new infrastructure in place, there's still the matter of our production humming away on our old hardware. Switching from Intel to AMD meant live migrating VMs wasn't an option. Plus, an offline migration was going to take a while, especially when we had to replicate the entire disk first.
So, how do we minimize downtime during our migration? We call it "warm data migration."

See this blog post for more details: https://xen-orchestra.com/blog/warm-migration-with-xen-orchestra/
And right after that, we can boot the replicated VMs on our AMD hosts! (and change their IP configuration, because we have new public IP blocks from a different provider).
New Levels of Performance
Apart from the blazing-fast backup performance (40 minutes for daily backups? Now it's just 5 minutes!), our VMs are feeling the love with reduced load averages. It makes sense, given the speedier storage and the mighty CPUs at their disposal.
This performance boost is particularly noticeable for some VM load averages:
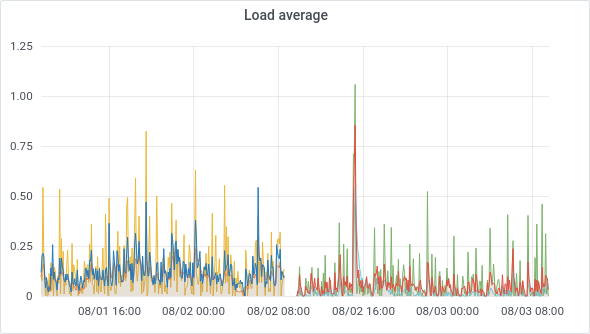
And don't even get us started on CPU usage:
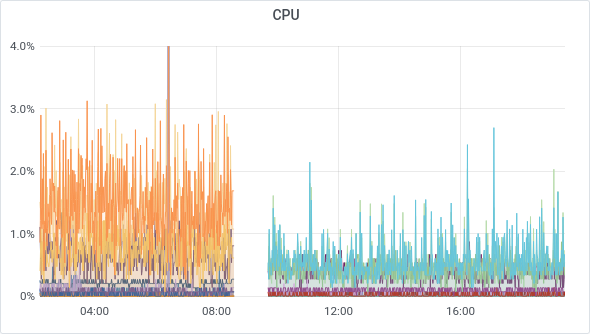
For our Koji Build system handling XCP-ng packages, kernel packaging used to take a solid hour. Now, it's clocking in at less than 20 minutes, using the same VM specs (same core count). Plus, since we had some extra cores to play with, we added 2 more, and the build time dropped even further (less than 15 minutes).
In a Nutshell
This migration project unfolded in three phases:
- Setting up the hardware in the DC (and plugging everything in)
- Installing and configuring the software on the new hardware (XCP-ng setup, storage, and more)
- The Migration
And the result? Total flexibility in our infrastructure, no outside shackles on our internal network, speedier VMs, quicker backups, and an ROI of less than a year! The actual time spent on these three phases was quite manageable, clocking in at less than three days of actual work (perhaps a tad more when you factor in planning). Most of the legwork revolved around migrating IP/DNS settings for the VMs themselves.
Oh, and one more thing: AMD EPYC CPUs are seriously impressive - great performance, both single and multi-threaded, all while sipping power responsibly. Plus, they don't break the bank!
-
@olivierlambert This is seriously impressive. and i like how you guys are sticking to the K.I.S.S principle for your infrastructure. What made you settle to a simplified structure. If i may ask ?
Thank you for also sharing this not many organizations like to say what they are running
-
After 10 years of seeing various virtualized infrastructures, we realized there's a clear relation between an infrastructure complexity and downtime. More complex means more problems, false alarms, hard debug and unknown/unpredictable behavior.
That's why, a good backup combined to a simple infrastructure gives the best result: less maintenance, less chances to have "bad automation" (eg: HA doing something weird). Yes, this requires to have some humans in the loop, but it's very low-demanding against managing complexity.
-
@olivierlambert So experience helped drove that decision home. Interesting there's always more to learn. Ive still got a long way to go.
")
-
Hmmm, I am interested as to what NVMe adapter card(s) are you using for your Dell R730 TrueNAS servers?
I also have 2 x R730's running Truenas in my XCP-ng setup where i have single NVMe drive for SLOG device, but i have an issue where the server on boot sometimes fails to recognise the NVMe adapter card (pcie link training failure) and i have been looking for a replacement that is more reliable.
So far i have tried couple cheap PCI cards from Akasa and Startech.
-
IIRC, it was Startech and it worked without any issues.
More recently, I purchased many Sabrent PCIe adapters (without any bracket) they are really convenient to work with! It's perfect to give your R730 a very fast storage device

-
 O olivierlambert referenced this topic on
O olivierlambert referenced this topic on
-
O olivierlambert pinned this topic on
-
@olivierlambert Not to mention that the ZFS filesystem on your TrueNAS gives you protection against "bit rot". Which is a nasty creeping file corruption issue where bits get flipped unexpectedly on the device.
However the XCP-ng instances are possibly a different story, as they may not have protection against this.
-
G gr85z referenced this topic on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login