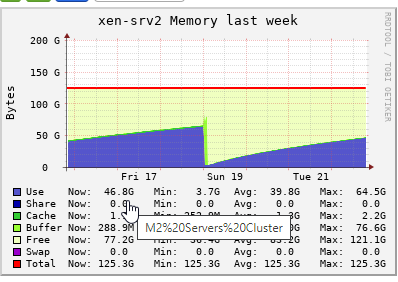
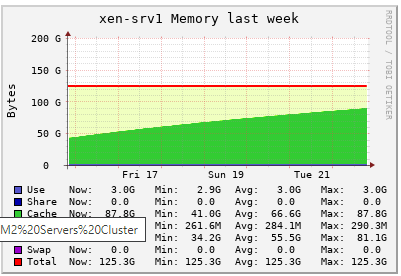
Memory Consumption goes higher day by day
-
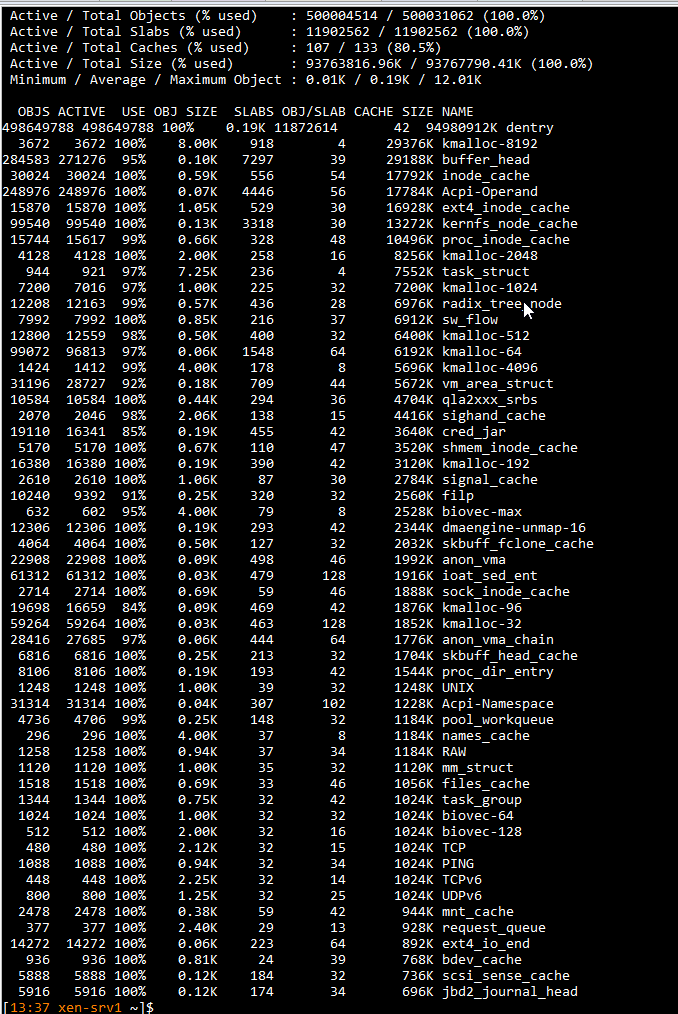
@dhiraj26683 Providing here with output of below commands
slabtop -o -s c
cat /proc/meminfo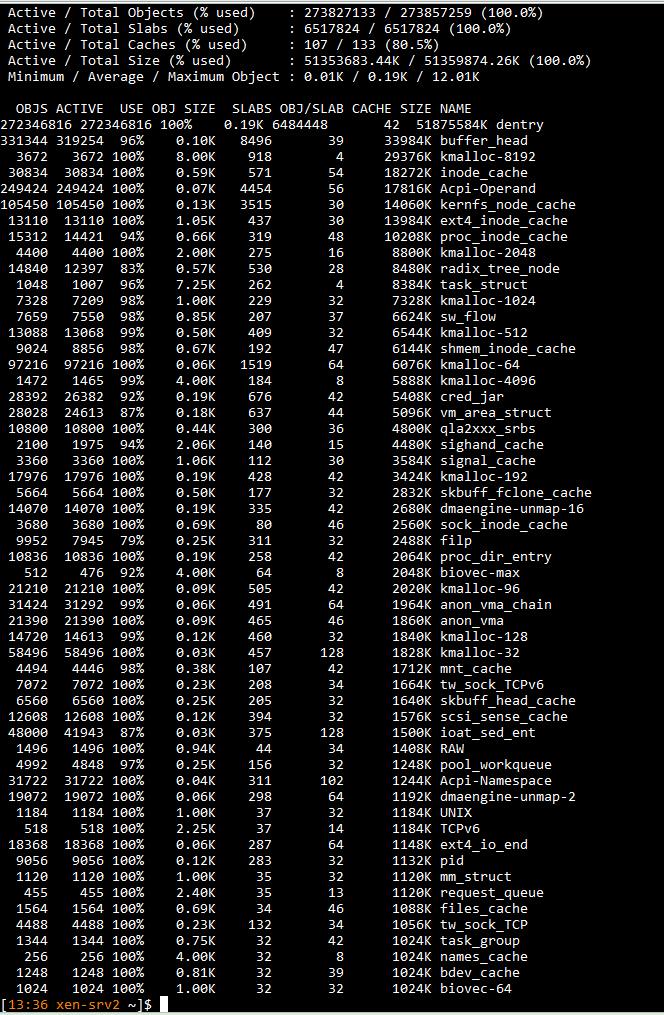
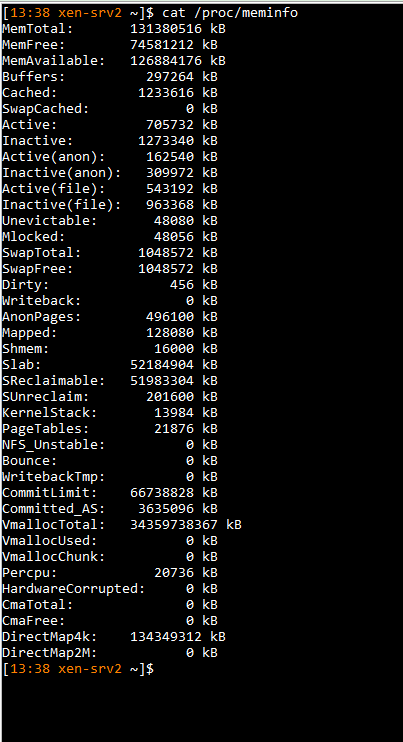
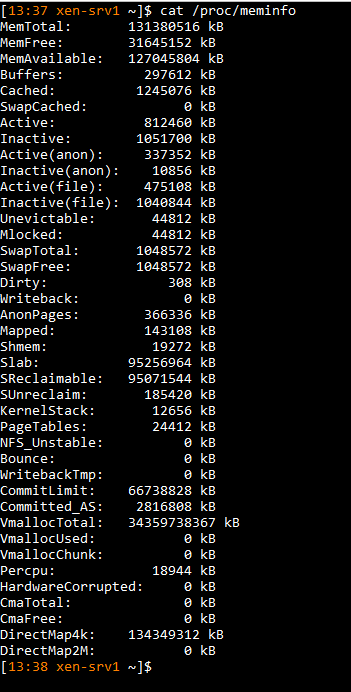
-
@dhiraj26683 Providing both servers ixgbe module info and rpm info, it's stock driver came along.
[13:59 xen-srv2 Dell-Drivers]$ modinfo ixgbe
filename: /lib/modules/4.19.0+1/updates/ixgbe.ko
version: 5.9.4
license: GPL
description: Intel(R) 10GbE PCI Express Linux Network Driver
author: Intel Corporation, linux.nics@intel.com
srcversion: AA8061C6A752528BD6CFE19[13:45 xen-srv1 ~]$ modinfo ixgbe
filename: /lib/modules/4.19.0+1/updates/ixgbe.ko
version: 5.9.4
license: GPL
description: Intel(R) 10GbE PCI Express Linux Network Driver
author: Intel Corporation, linux.nics@intel.com
srcversion: AA8061C6A752528BD6CFE19We tried below version update of ice modules as well,
ice-1.10.1.2.2
ice-1.12.7It's the same behaviour, hence we downloaded ice drivers from Dell and installed available version which is as given below. But it's still the same.
ice-1.11.14 -
@dhiraj26683
[14:26 xen-srv2 Dell-Drivers]$ rpm -qf /lib/modules/4.19.0+1/updates/ixgbe.ko
intel-ixgbe-5.9.4-1.xcpng8.2.x86_64 -
@dhiraj26683 tried to find out the process. But nothing to be identified as such. There are only three guests are running on this server and it is almost there to reach the limit. After all the memory goes into cache, we will start getting notifications/alerts about Control Domain Load reached 100% and there may be a service degradation.
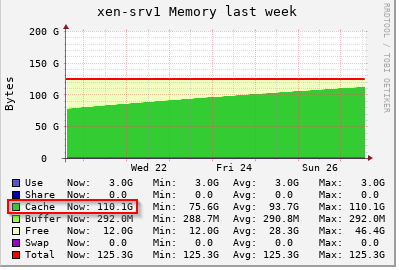
-
Do you have any extra stuff installed in your Dom0? It's very important to know it.
-
@dhiraj26683 Thanks for replying back @olivierlambert
Nothing as such other than Ice drivers.But for now, we are not running any virtual GPU workstation from last 3-4 months, so that kind of load is not there on any of our XCP hosts.
But as i could say, this memory issue started resently and and the only changes that we do is to push the patches via xoa.
Considering this kind of issue, where memory gets fullly utilized (get into cache) and notifications start about Control Domain Load reached 100%, we didn't pushed any patches for now.
-
Let me ping @psafont in case he got an idea on what could cause this
edit: also @gduperrey if he got an idea how to see what's eating all the memory
-
@dhiraj26683 the cached memory is not used by any particular process, it is used to keep eg. recently-accessed in memory to avoid reading them again from disk if the need arises. The OS is trying to make good use of otherwise-unused memory in hope of better performance, instead of letting unused memory just sitting idle.
If you launch a new process that would require more memory than what's currently free, the OS should happily free old cached pages for immediate reuse.
Did you observe anything specifically wrong, that turned you to observing memory consumption?
-
@olivierlambert i believe it's something related to nic drivers as we are running network intensive guests on both the servers.
We have a third Server, which is runing standalone. Below is it's config and only one guests runs on this host, which is XOA
CPU - AMD Tyzen Threadripper PRO 3975WX 32-Cores 3500 MHz
Memory - 320G
Ethernet - 1G Ethernet
10G Fiber

intel-ixgbe-5.9.4-1.xcpng8.2.x86_64As XOA does uses 10G ethernet for backup/migration operations. It seems to be caching not that much memory, but it is caching though. But not ending up utilizing all memory in cache because less operations happens here.
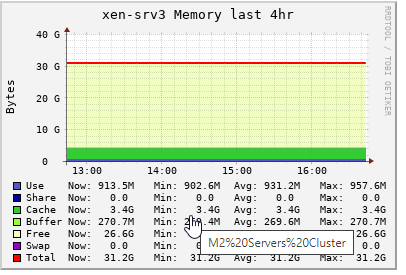
-
@yann Hello @yann I am well aware about the caching. But the question is which process is utilizing that memory which gets accumulated into cache and ends up reaching 120G
-
@dhiraj26683 Would you like to try a newer
ixgbe? We've got 5.18.6 available in our repositories. -
@dhiraj26683 if it was used by a process it would be counted in
usednot inbuff/cache. Those are used by the kernel's Virtual Filesystem subsystem.Now if your problem is that a given process fails to allocate memory while there is so much of the memory in buff/cache, then there may be something to dig in that direction, but we'll need specific symptoms to be able to help.
-
@stormi Sure, we can try that. Thank you
-
@dhiraj26683 It's available as the
intel-ixgbe-altRPM, that you can install withyum install.However, I second Yann's comment: growing cache usage is not an issue, as long as it's reclaimed when another process needs more than what's available, and this is what should happen whenever such a need arises. Unless you have evidence of actual issues caused by this cache usage.
-
@yann I can understand the buff/cache part but on this server which is with 1TB physical memory and only three VM's running with 8G, 32G and 64G as their alloted memory, eating up and alloting all memory in cache is not understandable. It's getting cache means something is using it. Not sure if that makes sence though.
Initially both our XCP hosts were with 16G Control domain memory. We started to face issue and alerts, we increased to 32G, then 64G, and then 128G, and it's like that for a while now.
Now we are not using vGPU, so it's not getting full within 2 days where alerts starts saying Control domain memory reached it's limit
-
-
@dhiraj26683 Could you detail these alerts and what they are based on? A linux system with most memory allocated to cache is exactly what is expected, after a few hours, days or weeks of use. On my computer, right now, I only use 6 GB out of 16 GB, but 9 GB are used by cache and buffers, and only 1 GB is free. However, I don't have any performance issues because, should I open a demanding process, cache will be reclaimed. Cache is just free memory which happens to contain stuff that might be useful again before it is thrown away due to more prioritary uses of memory.
-
I think he's talking about XAPI alerts, done via the message object (see https://xapi-project.github.io/xen-api/classes/message.html). That's what we display in XO in the Dashboard/Health view (we call them "Alerts")
-
@dhiraj26683 let me try to rephrase - I hear 2 things:
- "buff/cache" has to come from somewhere: right. Pages used as read cache ought to be traceable to data read from a disk, and some (intrusive) monitoring could be put in place to find out what data and who pulls them into RAM. But checking this would only make sense if you can observe the cached memory not being released when another process allocates memory. Also note in "buff/cache" we don't only have read cache (
Cachefrom/proc/meminfo) but also write buffers (Buffersinmeminfo) - you had memory issues when you used vGPU, and now you don't (or you still have but less?): this could look like a memory leak in the vGPU driver?
- "buff/cache" has to come from somewhere: right. Pages used as read cache ought to be traceable to data read from a disk, and some (intrusive) monitoring could be put in place to find out what data and who pulls them into RAM. But checking this would only make sense if you can observe the cached memory not being released when another process allocates memory. Also note in "buff/cache" we don't only have read cache (
-
@yann @stormi We have used vGPU for about 8-9 months. Initially we never faced any issue. When we were about to stop the vGPU workflow, it started and even after stoping that workflow, it is. We need to restart the servers to release the memory. We use to migrate all VM's to one server and restart individual host. And this issue started resently, before we never faced such thing.
Providing below is a year graph of both servers.
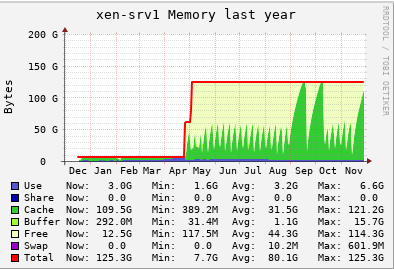
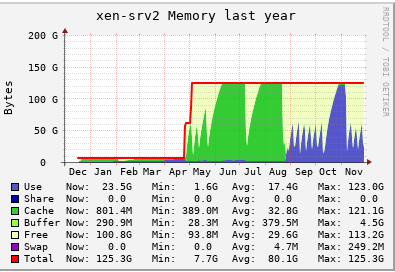
But i will surely try the new drivers and see if that helps. Thanks for your inputs guys. Much appreciated.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login