Epyc VM to VM networking slow
-
@JamesG sure but none of those do concrete troubleshooting and digging to establish where it is and it also only seems like isolated issues and not something broad (while it is but people didnt look at it as such).
-
@olivierlambert I believe that this is costly, nevertheless it needs to be fixed, as this CPU will get more mainstream as time goes by and as such it's not only cost but a good investment. I'm sure you'll get to the bottom of this now that you're tackling it.
Looking forward to Ampere!
-
If I wouldn't be convinced to fix it, I wouldn't throw money & time to solve the problem
")
-
@manilx said in Epyc VM to VM networking slow:
@florent Hi,
Both storages are NFS, all connections 10G.
On both cases XO/XOA is running on the master.thank you for the test. At least it removed the easy fixes
-
@olivierlambert said in Epyc VM to VM networking slow:
If I wouldn't be convinced to fix it, I wouldn't throw money & time to solve the problem
I think everyone knows this. Nevertheless, it is frustrating anyone if it becomes a bottleneck.
I am curious, do we know if this happens on Xen systems, or if it happens on xcp-ng systems where Open vSwitch is not used?
-
It happens on all Xen version we tested, the issue is clearly inside the Xen Hypervisor, and related on how the netif calls are triggering something slow inside AMD EPYC CPUs (not even Ryzen ones)
-
@manilx do you use NBD for delta backups ?
in the advanced settings -
@florent Florent, yes I do use NBD for all backups. And checking the backup log of the completed jobs I see that NBD is being used.
-
@manilx said in Epyc VM to VM networking slow:
@florent Florent, yes I do use NBD for all backups. And checking the backup log of the completed jobs I see that NBD is being used.
could you test disabling NBD ?
-
This post is deleted! -
@manilx Running a test backup, one with NBD and then again without. Will report asap.
-
@florent Result of backup tests:
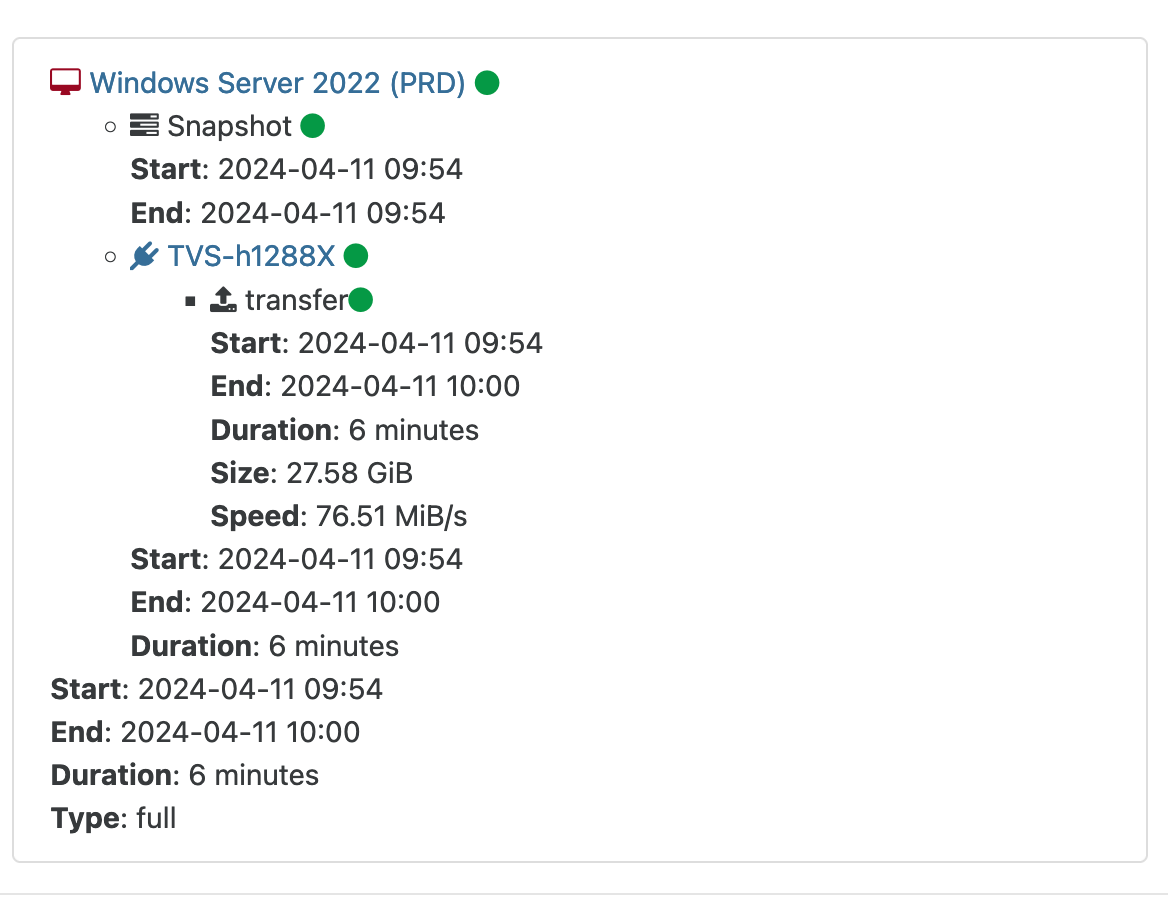
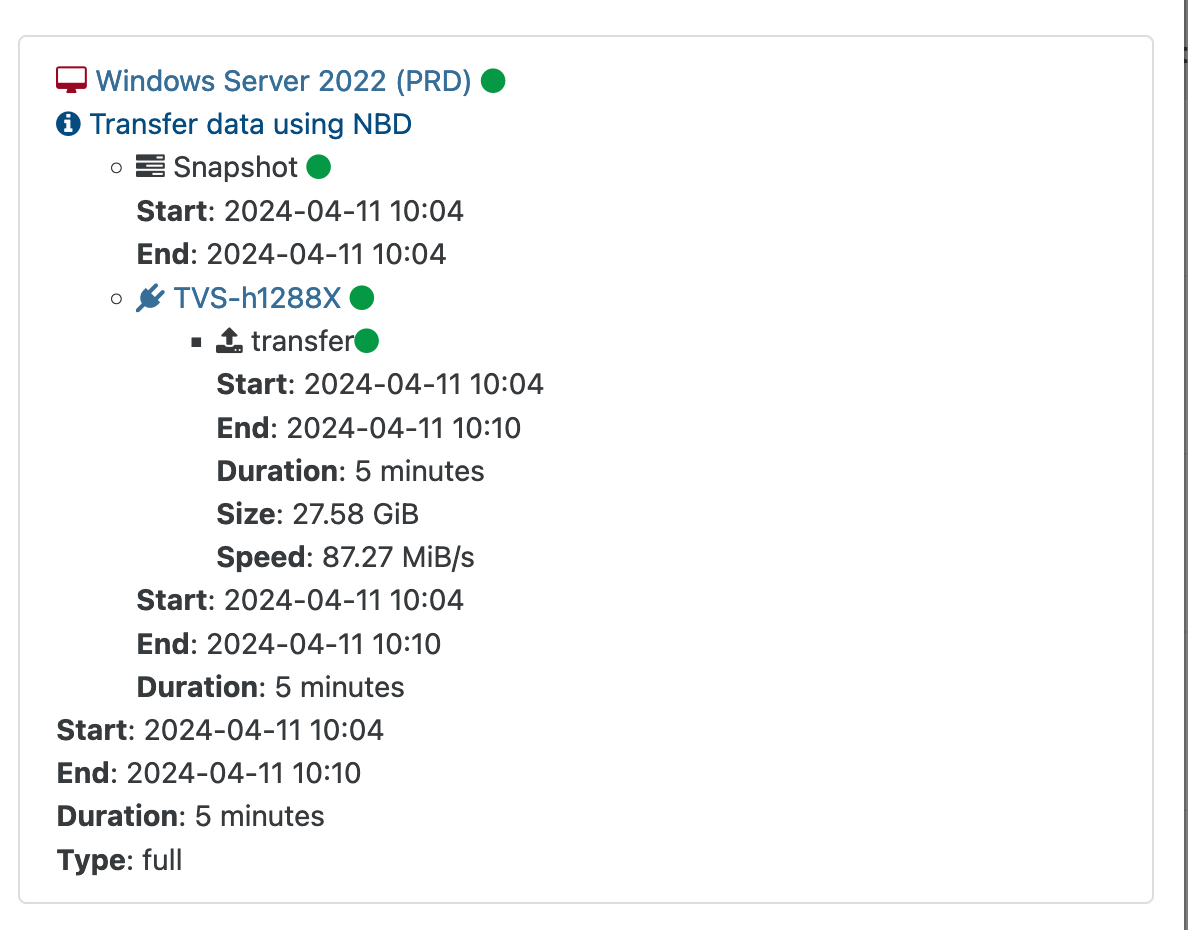
-
It may not be of any help, but wanted to add a little bit of info this anyway.
I'm seeing the same results on a set of Ubuntu 22.04 in my Threadripper based cluster. I didn't expect to see different results, since Threadripper is really just EPYC with some stuff turned off.
Specifically tested on a 16 core 1950X host and a 32 core 3970X host, both with 8 vCPUs on each VM, they topped out at 8 gigabit like most others are seeing.
Figured I'd add it in here.
-
Thanks! We didn't test on threadrippers yet, so it's useful info
")
-
This post is deleted! -
Is there any hope for a solution to this issue? How much do I understand this affects all generations?
-
We're still actively working on it, we're still not a 100% sure what the root cause is unfortunately.
It does seem to affect all Zen generations, from what we could gather, sligthly differently: it seems to be a bit better on zen3 and 4, but still always leading to underwhelming network performance for such machines.
To provide some status/context to you guys: I worked on this internally for a while, then as I had to attend other tasks we hired external help, which gave us some insight but no solution, and now we have @andSmv working on it (but not this week as he's at the Xen Summit).
From the contractors we had, we found that grant table and event channels have more occurences than on an intel xeon, looking like we're having more packet processed at first, but then they took way more time.
What Andrei found most recently is that PV & PVH (which we do not support officially), are getting about twice the performance of HVM and PVHVM. Also, having both dom0 and a guest pinned to a single physical core is also having better results. It seems to indicate it may come from the handling of cache coherency and could be related to guest memory settings that differs between intel and amd. That's what is under investigation right now, but we're unsure there will be any possibilty to change that.
I hope this helps make things a bit clearer to you guys, and shows we do invest a lot of time and money digging into this.
-
@bleader said in Epyc VM to VM networking slow:
We're still actively working on it, we're still not a 100% sure what the root cause is unfortunately.
I can also vouch for that they are taking it seriously and working on it. I have an ticket with them since the start of this essentially and work is definitely being done in said ticket to solve this once and for all.
-
Do I understand correctly that the problem also occurs when exchanging a server with a shared NFS storage, where the VHDs are located, and not just between the VMs themselves? That is, the exchange of a virtual machine with disks attached to it on shared storage will be slowed down?
-
@alex821982 no, we have seen no such indication... With that said we have not tested for that either and it is "possible" the main issue at hand is that all epycs processors hit an upper limit with network traffic going in and out of a VM. And it is a per physical host limit so if you have both VMs on same machine the limit is halved.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login