after downgrading xcp host from trail 90% of my vms are not booting..
-
Thanks Danp , it is curtainly a huge coincidence then .. my i/o issues had me rebooting constantly for weeks.. soon as i downgrade i can not reboot anymore.. Anyways how can i force it being mounted
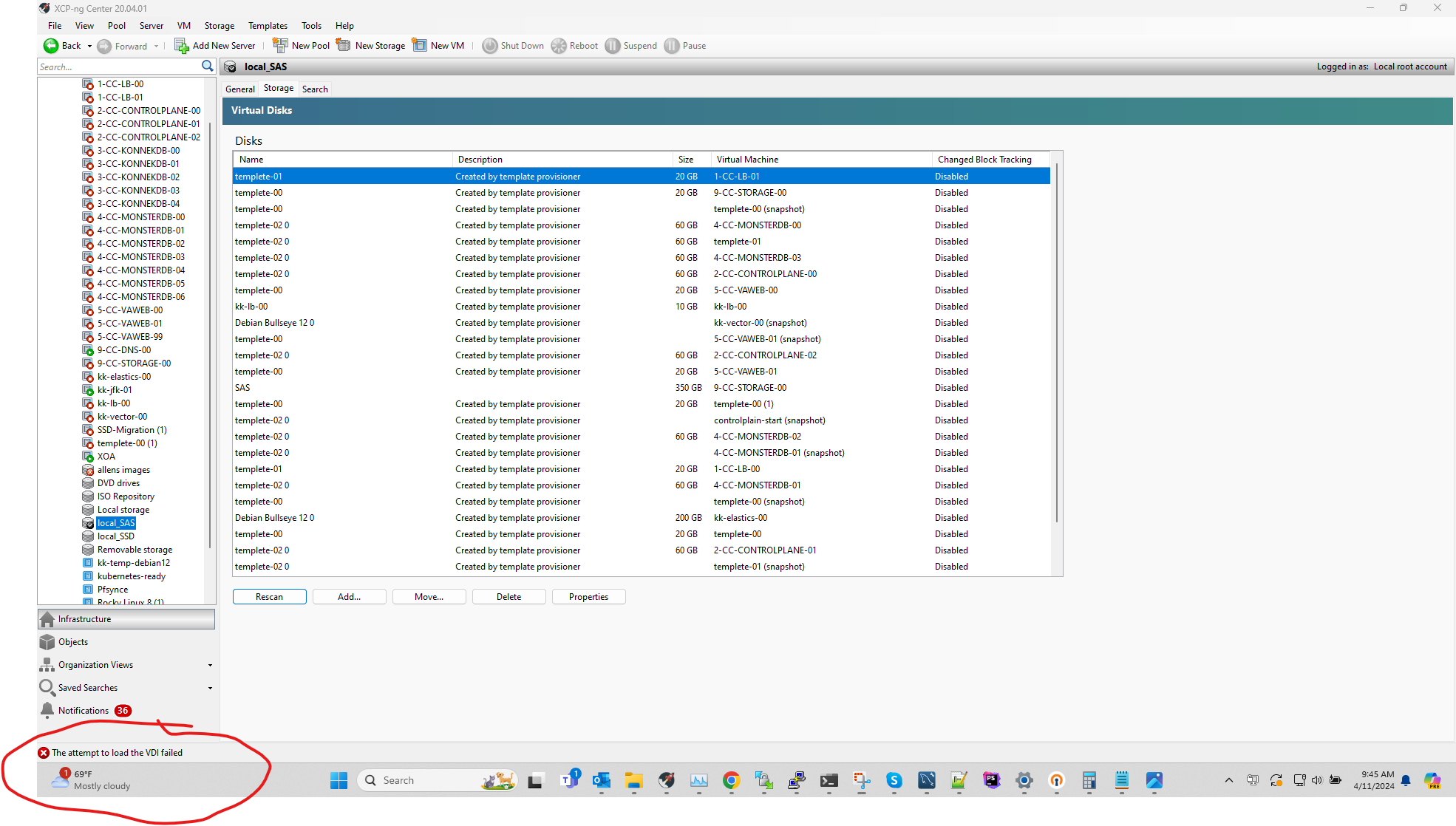
i do see a error about the vdi failed when scaning the repo..
please do not tell me i need to delete all an recreate them
-
@cyford
also when the trial expires the whole panel is useless till you downgrade.. everylink you click takes you to the downgrade.. u can not use xoa till the downgrade is complete -
@cyford How about https://forums.lawrencesystems.com/t/how-to-build-xen-orchestra-from-sources-2024/19913
Takes you 15min
-
@cyford said in after downgrading xcp host from trail 90% of my vms are not booting..:
everylink you click takes you to the downgrade.. u can not use xoa till the downgrade is complete
Yes, that is clearly by design.
my i/o issues had me rebooting constantly for weeks.. soon as i downgrade i can not reboot anymore..
Sounds like you were having storage problems before the XOA downgrade.
i do see a error about the vdi failed when scaning the repo..
please do not tell me i need to delete all an recreate themYou could check
/var/log/SMlogto see if it provides further details related to this VDI. -
thats not correct . only in these vm's there is issues, test proves fine in the host or any other os performance issues and errors is only in the vm's themselves
also in the host it shows as there mounted and all drives test fine and have great speed an performance in the host
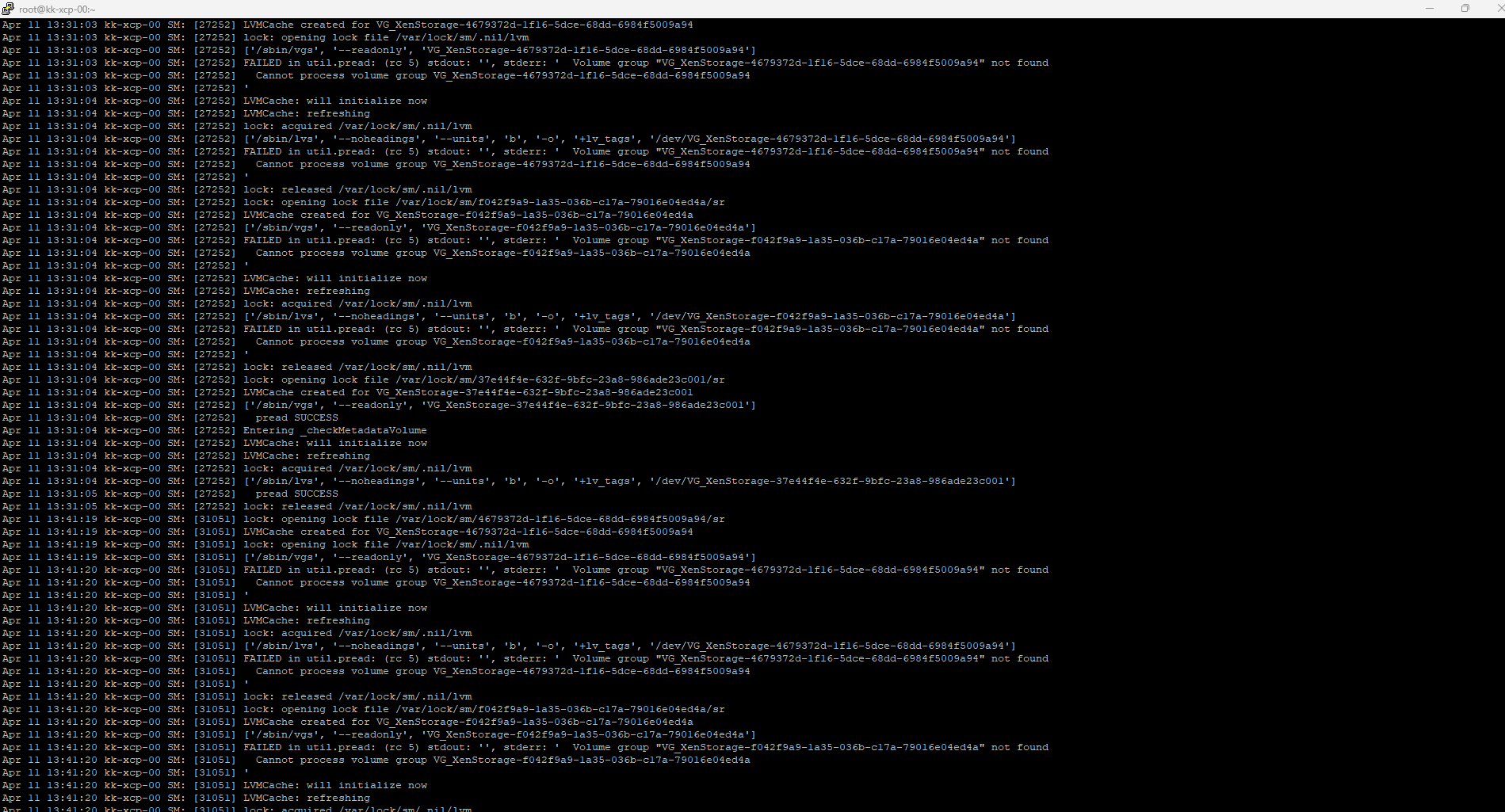
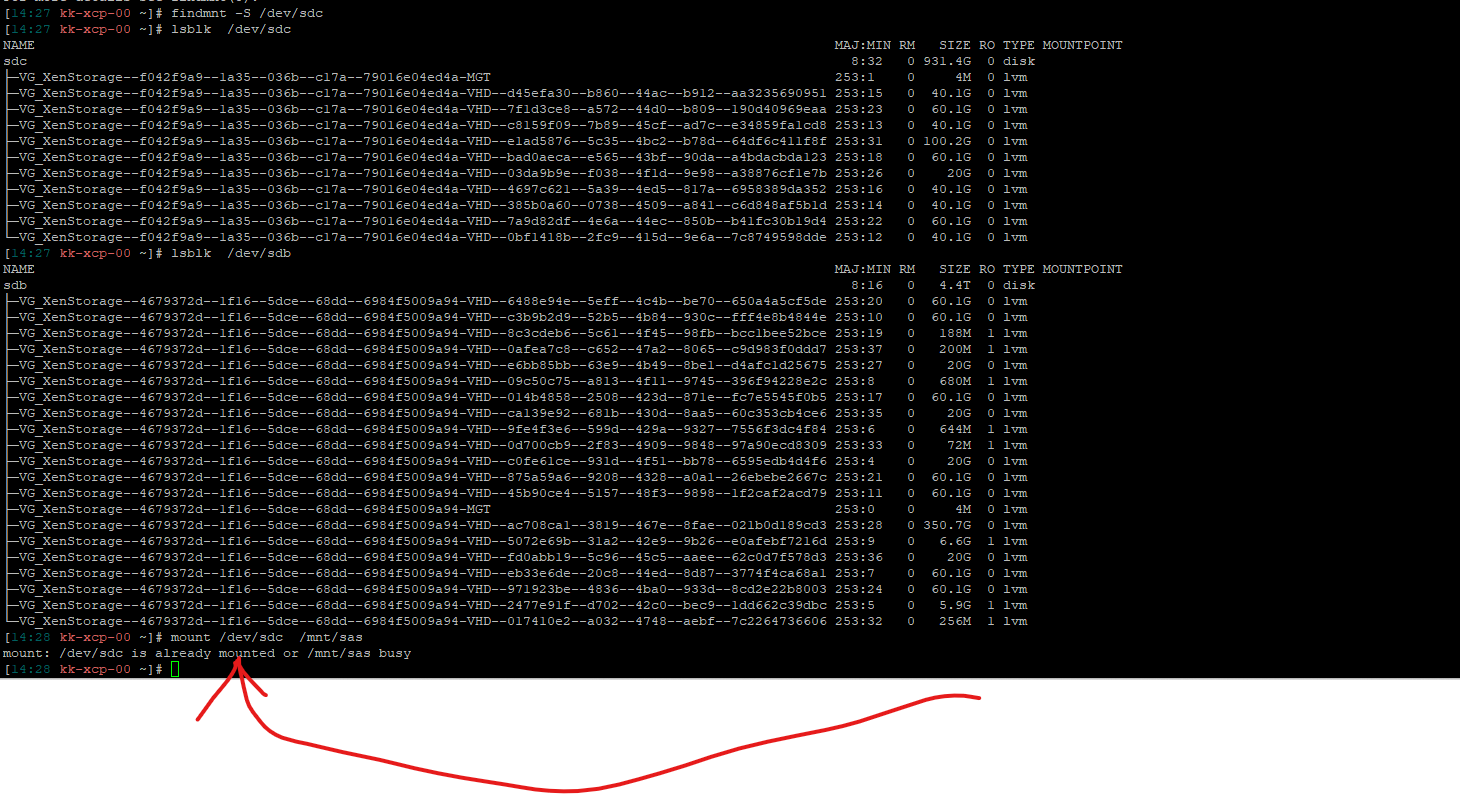
-
here is the complete logs for smlog
-
@Danp said in after downgrading xcp host from trail 90% of my vms are not booting..:
I haven't used the Windows client in forever, so I can't tell if the toolstack restart was successful or failed. Can you try restarting the toolstack using XOA? Also, can you show us a screenshot of the host's Storage tab in XOA?
Reply
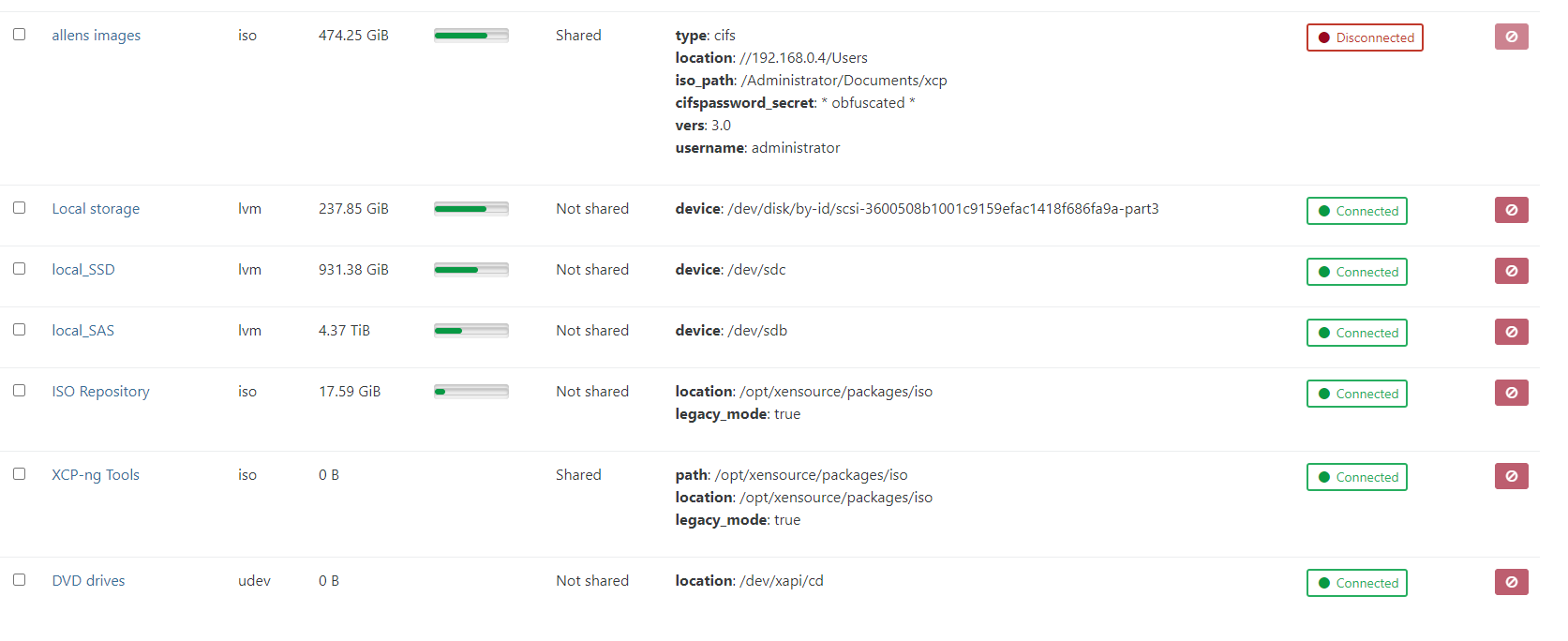
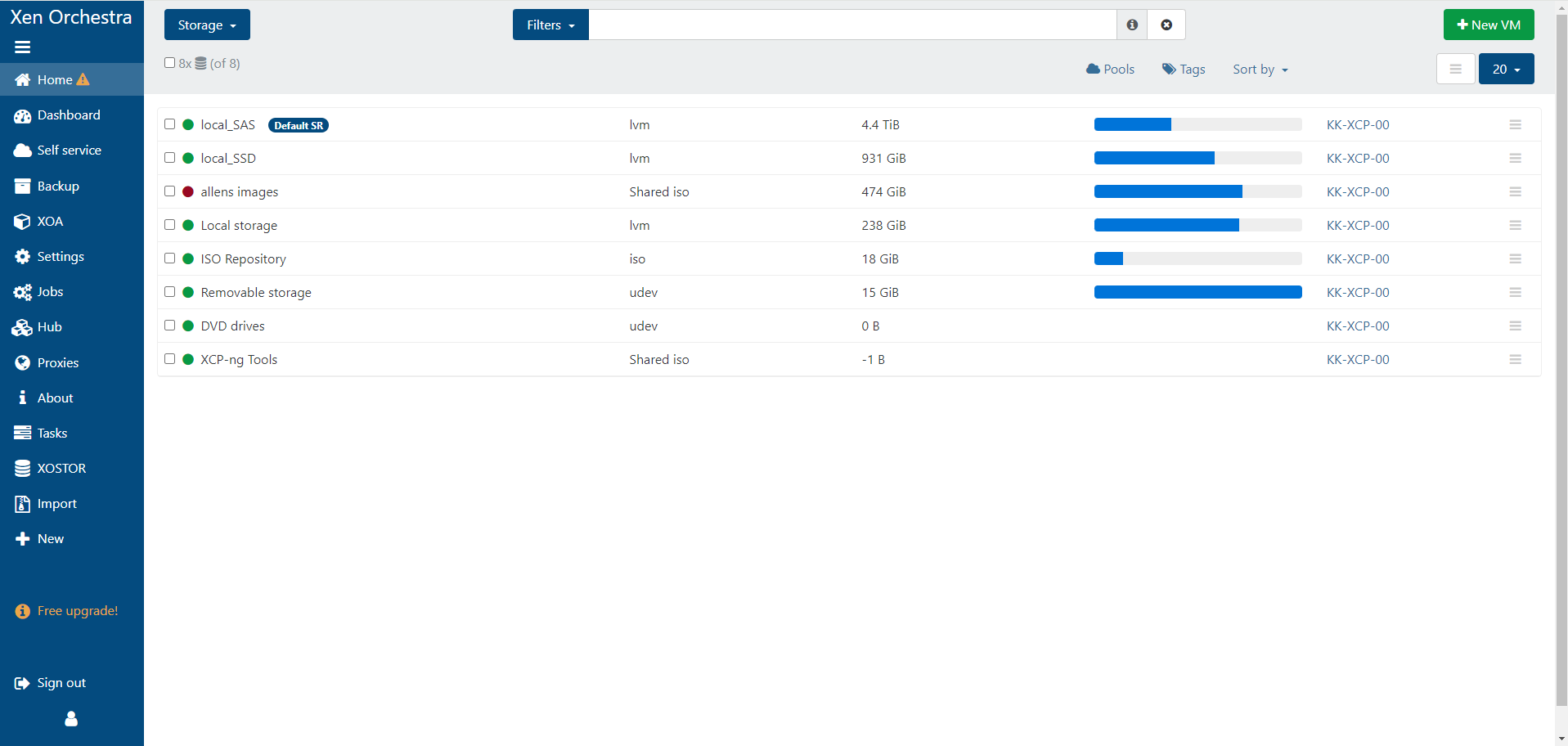
i restarted it in xoa aswell it doesnt workwhen i start a vm this is what i see in the logs:
Apr 11 14:59:33 kk-xcp-00 SM: [31761] lock: opening lock file /var/lock/sm/4679372d-1f16-5dce-68dd-6984f5009a94/sr Apr 11 14:59:33 kk-xcp-00 SM: [31761] LVMCache created for VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94 Apr 11 14:59:33 kk-xcp-00 SM: [31761] lock: opening lock file /var/lock/sm/.nil/lvm Apr 11 14:59:33 kk-xcp-00 SM: [31761] ['/sbin/vgs', '--readonly', 'VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94'] Apr 11 14:59:34 kk-xcp-00 SM: [31761] FAILED in util.pread: (rc 5) stdout: '', stderr: ' Volume group "VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94" not found Apr 11 14:59:34 kk-xcp-00 SM: [31761] Cannot process volume group VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94 Apr 11 14:59:34 kk-xcp-00 SM: [31761] ' Apr 11 14:59:34 kk-xcp-00 SM: [31761] LVMCache: will initialize now Apr 11 14:59:34 kk-xcp-00 SM: [31761] LVMCache: refreshing Apr 11 14:59:34 kk-xcp-00 SM: [31761] lock: acquired /var/lock/sm/.nil/lvm Apr 11 14:59:34 kk-xcp-00 SM: [31761] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94'] Apr 11 14:59:34 kk-xcp-00 SM: [31761] FAILED in util.pread: (rc 5) stdout: '', stderr: ' Volume group "VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94" not found Apr 11 14:59:34 kk-xcp-00 SM: [31761] Cannot process volume group VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94 Apr 11 14:59:34 kk-xcp-00 SM: [31761] ' Apr 11 14:59:34 kk-xcp-00 SM: [31761] lock: released /var/lock/sm/.nil/lvm Apr 11 14:59:34 kk-xcp-00 SM: [31761] vdi_epoch_begin {'sr_uuid': '4679372d-1f16-5dce-68dd-6984f5009a94', 'subtask_of': 'DummyRef:|a036458a-6043-476f-bce5-21a6ca72d1dc|VDI.epoch_begin', 'vdi_ref': 'OpaqueRef:3a903002-b13c-48b7-990e-f466fe0b6037', 'vdi_on_boot': 'persist', 'args': [], 'vdi_location': 'c0fe61ce-931d-4f51-bb78-6595edb4d4f6', 'host_ref': 'OpaqueRef:e40ba20c-5291-43e3-8a40-bcc6332ad750', 'session_ref': 'OpaqueRef:68bc589a-0524-4ced-81e6-b789e0592581', 'device_config': {'device': '/dev/sdb', 'SRmaster': 'true'}, 'command': 'vdi_epoch_begin', 'vdi_allow_caching': 'false', 'sr_ref': 'OpaqueRef:f2bc7092-9ba7-40ac-b3a1-f01228ee2079', 'vdi_uuid': 'c0fe61ce-931d-4f51-bb78-6595edb4d4f6'} -
I haven't checked your pastebin yet, but those definitely appear to be storage issues to me based on the logs shown in your screen shots. You should post the output of
pvdisplay,lvdisplay, andvgdisplayfor the affected storage. -
reboote the server and it did not come up lol dude these drives are good, hardware is good.. something to do with this hypervisor.. think i may need to reinstall the os tommorow..
if there is a repair option in this iso i will try it..
most is kubernetes so deploying is easy .. but my git was not updated in weeks so im scared i will loose data from one of the vms. i wish i could mount it somehow externally is that possible?
ill run your commands tommorow though
-
@cyford said in after downgrading xcp host from trail 90% of my vms are not booting..:
2 Sr's are local.. 1 is SAS drives raid 0 , and the other is SSD SAS raid 0
the only one that works is raid 1 local drive
I'm confused by the above. Are there 2 local SRs or 3? How were these created?
Which SRs are working correctly and which SRs are giving you problems?
@cyford said in after downgrading xcp host from trail 90% of my vms are not booting..:
when i start a vm this is what i see in the logs:
Apr 11 14:59:34 kk-xcp-00 SM: [31761] FAILED in util.pread: (rc 5) stdout: '', stderr: ' Volume group "VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94" not found
Apr 11 14:59:34 kk-xcp-00 SM: [31761] Cannot process volume group VG_XenStorage-4679372d-1f16-5dce-68dd-6984f5009a94When you create an SR, it builds a file system on the target device. In the above, it is trying to access a volume group that no longer appears to exist. This is a storage problem.
@cyford said in after downgrading xcp host from trail 90% of my vms are not booting..:
reboote the server and it did not come up lol dude these drives are good, hardware is good.. something to do with this hypervisor
I said that you appear to have a storage problem, which doesn't necessarily imply a hardware problem.
i wish i could mount it somehow externally is that possible?
I imagine so, but it depends on many factors that are unknown at this time.
-
just want to say after reinstalling all and recreating the all repositories i do have any disk errors or IO issues
-
@cyford said in after downgrading xcp host from trail 90% of my vms are not booting..:
just want to say after reinstalling all and recreating the all repositories i do have any disk errors or IO issues
I assume that you meant to Include a
notin there.
-
yes your correct .. however my source issues started again..
there is some issue using kubernetes, longhorn with mariadb operator in xcpng
having a hard time tracking down the root cause
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login