Let's Test the HA
-
When I stated power failure it was a reference to a test for a small scale style action to simulate what would happen if the data centre were to lose power.
I was already in progress of pulling a sled when you posted. BUT, the chassis only has 2 power supplies. Each individual server does not. So that wouldn't work. I mean, I guess I could power a host down individually. I'll add that to the tests as well.
-
@Midget said in Let's Test the HA:
When I stated power failure it was a reference to a test for a small scale style action to simulate what would happen if the data centre were to lose power.
I was already in progress of pulling a sled when you posted. BUT, the chassis only has 2 power supplies. Each individual server does not. So that wouldn't work. I mean, I guess I could power a host down individually. I'll add that to the tests as well.
It's a reference in other words to a power black out, then recovery from a blackout of data centre (or part of one).
-
@john-c Oh you mean literally pull the power on the entire lab? I guess I could do that. Although our DC has dual 16kVA UPS', dual 600 amp DC plants, and dual generators. So it would take a lot for that building to go dark. But it's a valid test.
-
@Midget said in Let's Test the HA:
@john-c Oh you mean literally pull the power on the entire lab? I guess I could do that. Although our DC has dual 16kVA UPS', dual 600 amp DC plants, and dual generators. So it would take a lot for that building to go dark. But it's a valid test.
Also depending on results there's in the latest XOA an API interface for emergency pool shutdown and resume on power failure.
-
I let the environment calm down. And let things get back to normal. Gave it a few minutes and pulled out the Master. Which was XCP-HOST2.
It's been about 5 minutes, just checked XOA, and the cluster is gone. None of the VM's, nothing. How long should master selection take? I'll give it another 10 or so minutes before slotting the server back in place.
EDIT
I just noticed the XOSTOR no longer exists either... -
@Midget said in Let's Test the HA:
I let the environment calm down. And let things get back to normal. Gave it a few minutes and pulled out the Master. Which was XCP-HOST2.
It's been about 5 minutes, just checked XOA, and the cluster is gone. None of the VM's, nothing. How long should master selection take? I'll give it another 10 or so minutes before slotting the server back in place.
EDIT
I just noticed the XOSTOR no longer exists either...That's why when I setup my XCP-ng system, it was with a bare metal storage server which is maintained. That way VMs can recover and migrate cleanly that's a potential failure of hyper convergence based storage methodologies. Where storage is provided on the same host(s) as the hypervisor and VMs.
As the VMs can not start up if storage isn't available, but the storage is provided by a VM. In other words a chicken and egg situation to avoid.
@olivierlambert @Midget We may have discovered a potential failing of XOSTOR and hyper convergence generally during putting the lab through its paces.
-
We are not there yet, there still some issues in XOSTOR before playing with HA, even if it theory that should work, LINSTOR proved problematic in some situations. So please use it, but not with HA yet.
-
Well, it appears the SSD I was using for the hypervisor died. So now I’m reinstalling XCP onto what was the Master on a “new” SSD. Good thing we have no shortage of hardware in our lab lol.
-
@olivierlambert
I guess I could build a TrueNAS quick. Maybe after my vacation. -
Some time past and I like to pick up this old topic as I recently did some DR testing with XOSTOR as well. My pool is HA enabled and the VM configured to restart.
I started with some basic vm migration and reboot of hosts. Disk will sync and resync fine. I was not able to cause an error performing those tasks.

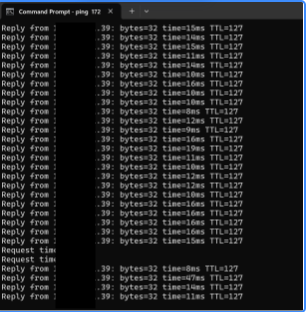
I further removed power from the active host to cause a serious outage. The VM became unavailable. XOSTOR shortly after enabled the disk on the other node and restarted my vm automatically.

I verified that no data was lost. Made some file modifications within the vm and powered up the other node again. It re-joined the pool and synced disk no problem.

Its pretty much the exact same behavior we are used to have with vSAN. I'm very happy with this result !!
I hope this helps someone that is looking for this kind of setup.
Stefan
-
-
@olivierlambert I can imagine that it was not easy. But the hard work seems to pay off at the right time. @ronan-a thank you as well !!
Please keep up the good work. It's those days not given to find a good product with a team behind that is so responsive and willing to help and innovate at the same time.
-
@456Q said in Let's Test the HA:
Some time past and I like to pick up this old topic as I recently did some DR testing with XOSTOR as well. My pool is HA enabled and the VM configured to restart.
I started with some basic vm migration and reboot of hosts. Disk will sync and resync fine. I was not able to cause an error performing those tasks.
I further removed power from the active host to cause a serious outage. The VM became unavailable. XOSTOR shortly after enabled the disk on the other node and restarted my vm automatically.
I verified that no data was lost. Made some file modifications within the vm and powered up the other node again. It re-joined the pool and synced disk no problem.
Its pretty much the exact same behavior we are used to have with vSAN. I'm very happy with this result !!
I hope this helps someone that is looking for this kind of setup.
Stefan
Very impressive, we have about the same experience with vSAN.
The only thing stopping us from migrating from vSAN is that vSAN has native support for Microsoft SQL Server Failover Cluster which is a huge deal for many of our customers.Maybe one day we'll use something else which enables us to migrate, untill then we're stuck with VMWare at work.
From a private side its XCP all the way! -
@nikade said in Let's Test the HA:
The only thing stopping us from migrating from vSAN is that vSAN has native support for Microsoft SQL Server Failover Cluster which is a huge deal for many of our customers.
Thats interesting and might be good for a new topic. The HA SQL Cluster was pretty much the first thing that we migrated over to XCP-NG. We would have stayed with VMware if this would not work.
I assume you have set up a SQL Server Cluster on WSFC where IP and DISKs failover from node1 to node2?
We have moved on many years ago (before XCP time) from this configuration to an Always On availability group for SQL. Its still a windows cluster that will failover the IP for legacy applications but does not have the disk requirement. It comes with many advantages such as:
-
You can setup the SQL HA cluster cross vSAN cluster or XCP pools. You can even mix.
-
Each SQL has independent disks and don't share "just" one. You could loos all disks in one cluster without causing downtime for SQL.
-
Always on group allow to fail over individual databases. So you can split the load between two server if you have many databases.
There might be something that i dont know. But i know for sure that our SQL cluster is working fine on XCP-ng
")
-
-
@456Q said in Let's Test the HA:
@nikade said in Let's Test the HA:
The only thing stopping us from migrating from vSAN is that vSAN has native support for Microsoft SQL Server Failover Cluster which is a huge deal for many of our customers.
Thats interesting and might be good for a new topic. The HA SQL Cluster was pretty much the first thing that we migrated over to XCP-NG. We would have stayed with VMware if this would not work.
I assume you have set up a SQL Server Cluster on WSFC where IP and DISKs failover from node1 to node2?
We have moved on many years ago (before XCP time) from this configuration to an Always On availability group for SQL. Its still a windows cluster that will failover the IP for legacy applications but does not have the disk requirement. It comes with many advantages such as:
-
You can setup the SQL HA cluster cross vSAN cluster or XCP pools. You can even mix.
-
Each SQL has independent disks and don't share "just" one. You could loos all disks in one cluster without causing downtime for SQL.
-
Always on group allow to fail over individual databases. So you can split the load between two server if you have many databases.
There might be something that i dont know. But i know for sure that our SQL cluster is working fine on XCP-ng
Our setup is rather legacy, what SQL license are you using and do you have to license "passive" nodes with AlwaysOn?
When we started our "best practice" AlwaysOn wasnt available in the SQL Standard license and last time I research it I think there was a limitation on how many databases you were allowed to run in the SQL Standard AlwaysOn edition. Maybe that has changed now?We're using the "legacy" setup with a shared disk for SQL Witness and a shared disk for the SQL Server Data, which vSAN supports natively without having to setup iSCSI.
-
-
@nikade I believe this feature is available since SQL 2016. We are using two regular standard licenses for this.
The limitation in standard is that you can have only one availability group. The availability group is linked to the windows cluster and the IP that can failover between the nodes.
However you can have as many databases as you want and you can fail them over independet.
We are not using the failover IP at all. The limitation to one group is therefore not relevant for us. We have definied both sql server within the sql connections string
server=sql1;Failover Partner=sql2;uid=username;pwd=password;database=dbnameThis will make the application aware of the failover cluster and allow to connect to the primary node.
This works very well in our case. You can also use some clever scripts if you deal with legacy apllication that cannot use the connection string above.
https://www.linkedin.com/pulse/adding-enterprise-wing-sql-server-basic-availability-group-zheng-xu
Its something we have done before. But its currently not needed anymore.
-
@456Q That's neat, we'll look into that for sure.
Another good thing with the failover cluster and shared disks is that you may run services in "HA" mode and fail over between nodes as you failover the SQL server.
Is that something that works as well? I dont see how you could achieve it without shared storage. -
@nikade it's fully HA and the failover is even faster as sql server ist already started. It's too long ago. But I believe that sql service In your configuration was only stated when it actually fails over.
Each server will have local disks and sql server will keep them in sync syncronos with log shipping. It requires fast network like vsan does as well.
You can failover the server or individual databases at any time.
We currently have the server1 on xcp-ng and server2 on a vsan cluster that was not migrated yet.
We failover all the time during maintenance windows for patching etc. Its very robust.
Stefan
-
@456Q Yea in failover-cluster the secondary SQL service is not started, it starts when the failover is initiated.
How do you handle your applications? For example we have multiple customers where we have the following setup:2 VM's running Windows Server, identical CPU/RAM/Disk and they have 1 shared disk for WSFC Witness and 1 shared disk for WSFC SQL Server Data.
On this WSFC we have the following "roles" or whatever to call them:- SQL Server: The clients databases are in this SQL Server.
- File server: The clients files are on this file server.
- Applications and Services: The clients applications and services runs here, many using the databases hosted in the same SQL Server.
When we have maintenance on VM1 we just failover the whole WSFC and the SQL Server, File Server and Applications and Services running on that VM1 is failed over to VM2 and everything is done within 1-2 minutes.
I dont think AlwaysOn supports this kind of scenario because it does not hare any shared storage. Am I correct in my assumption?
-
@nikade we have dedicated VMs for each role. So sql is only sql.
You would have to check if your application has some build in HA that would work without a shared disk.
We are setup in a way where mutilple application server run behind a load balancer (haproxy) with load balancing enabled.
file services are provided by truenas which is behind a load balancer as well in an active /backup configuration.
The app and file services files are synced by syncthing.
We are coming from a configuration similar to yours. But had to change to scale it more and increase the redundancy. We also considered the shared disks as single point of failure.
Just take your time in look into each component. I'm sure you will find a way.

Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login