CBT: the thread to centralize your feedback
-
It depends on the SR you are using. If it's XOSTOR or not. On XOSTOR, NBD is causing some challenges. But if it's a regular SR, the issue should be fixed since we are enforcing removal of VDI attached to the control domain.
-
@olivierlambert no xostor, sr is on fiber channel san (two san with some volumes, HDD or SSD)
may i try the reactivation of both? -
Without more context, I would say "yes"
") CBT will reduce the amount to coalesce. Try to keep NBD "Number of NBD connection per disk" at 1 to be on the safe side.
CBT will reduce the amount to coalesce. Try to keep NBD "Number of NBD connection per disk" at 1 to be on the safe side. -
@olivierlambert @florent regarding the error
error {"code":"VDI_IN_USE","params":["OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885","data_destroy"],"call":{"method":"VDI.data_destroy","params":["OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885"]}} vdiRef "OpaqueRef:fbd3bedd-ea60-4984-afca-9b2ec1b7b885"As a test i did the command on this snapshot manually over ssh
xe vdi-data-destroy uuid=This seems to purge the snapshot data correct, so i believe this issue is temporary and maybe a retry itself during the backupjob does resolve it. We see it not so ofter but enough to investigate it more deeper.
Inside the Knowledgebase from xenserver i found this
VDI_IN_USE: The VDI snapshot is currently in use by another operation. Check that the VDI snapshot is not being accessed by another client or operation. Check that the VDI is not attached to a VM. If the VDI snapshot is connected to a VM snapshot by a VBD, you receive this error. Before you can run VDI.data_destroy on this VDI snapshot, you must remove the VM snapshot. Use VM.destroy to remove the VM snapshot.I believe the vdi.destroy is not yet finished complete before the data-destroy is issued, resulting in the vdi in use error.
-
Hi, why this difference?
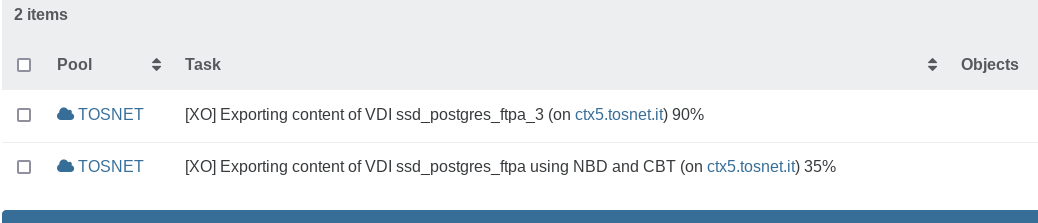
The backup joband the VM are the same -
While my backups (NBD, Delta) have been running now fine and garbage collection fnishes I just noticed that I have multiple snapshots referring to the backup on all VM's:
Deleted all but the last and will see how it goes. -
@manilx Have you enabled CBT+data removal? Otherwise you'll continue to see snapshots (but yeah, the old ones should be removed at some point)
-
@olivierlambert No, I haven't. Will do now.
-
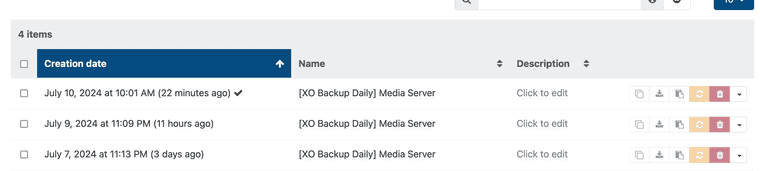
@manilx P.S. It wasn't clear to me that I had to turn this on. I just left everything as it was after updating XO..... (Was always using NBT before):
-
@olivierlambert The next backup has run and now there a no snapshots at all (even the last one I left was removed). Is this how this is supposed to be? Totally confused.
I get this:
 .
.
OK. But if I want the "old" way to have the snapshots, they accumulate as we have seen...... ?? -
- That's thanks to CBT
- The old way can be used again, just disable the data removal toggle. And yes, it shouldn't accumulate more than 1 snap per schedule.
-
@olivierlambert Understood. Then it's up to @florent to fix this snapshot accumulation.
Thx -
If we can reproduce the issue, because for now I do not have the problem here. Double check you are on the latest commit (or XOA latest fully up to date)
-
@olivierlambert Positive. Will disable it again and see if it happens again.
-
Seeing a nice decrease in space used.

I'm keeping the snapshot around in case I need it, thought I doubt that I would.
-
@olivierlambert Disabled the data removal option again.
1st backup run: snapshot created
2nd one: still just the one snapshot.Seems like enabling, backing up, disabling the option cleared this up.
Will monitor.
-
We have this error "stream has ended with not enough data (actual: 446, expected: 512)" on multiple vms in the last few days anyone seeing this issue?
-
Is this VM also using NBD-enabled network? In our prod, I also have this issue each 2 backups for one specific VM not hosted in the same pool than the rest, without any NBD configured network.
-
@olivierlambert yes both NBD, we have them in the same pool and NBD network is enabled.
-
@olivierlambert, we haven't encountered this error very often, but it seems to occur mainly when the backup load is higher. With it being Windows Update week, some jobs are taking longer than usual, leading to overlaps. The issues seem to arise particularly during these overlaps. I've opened a GitHub issue for this problem as well as for the VDI in-use issue. Hopefully, Florent will have time today to look into it more deeply.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login