Some VMs Booting to EFI Shell in Air-gapped XOA Instance
-
Good-day Folks,
I have a small lab environment, running a proof-of-concept using XOA + XCP-ng, to see if this can be a viable solution for air-gapped networks within my organization. The testing has been going smoothly until last night, when I took a snapshot of a VM - something I've done many times in this environment. I generally power down the VM before I grab the snapshot, then power the VM back up. However, this time upon powering the VM up, it booted into the EFI Shell.
Here's what my environment looks like:
- XOA (version not shown - this is an air-gapped instance built for my POC)
- XCP-ng v8.3.0 (VMH01 and VMH02)
Last night I observed the following:
-
In XOA, the Pool was connected to both hosts (VMH01 and VMH02) but I couldn’t disable the connection. Each time I tried, I got the following error: “MISCONF Redis is configured to save RDB snapshots, but it’s currently unable to persist to disk. Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option). Please check the Redis logs for details about the RDB error.”
Strangely enough, this error message does not appear in the XOA logs.
-
VMH01 (which is the pool master) is online, responds to pings but refusing all SSH access, so I was not able to check the Redis logs (as directed in the error message). A physical console access needs to be established with VMH01 to further troubleshoot. Given that we’re testing viability of this solution, I didn’t just want to reboot the system without first working through to identify the root cause.
I came in today and attempted to make a physical console connection with the problematic host (VMH01), but I got no video and no keyboard functionality. So, I had no choice but to do a hard reboot. It came back up, rejoined the pool, and assumed the Master role (I assume it was never relinquished).
XOA is up (running on VMH01) and all the VMs are up, but a couple are still booting to the EFI Shell, so need your help figuring out why. The other VMs that are booting fine are using the same SR.
As this is a Proof-of-Concept, I don't want to push the easy button and simply revert the VM to the previous snapshot. I want to identify the root cause and document the resolution. Any guidance is greatly appreciated, thanks.
-
@kagbasi-ngc What OS is on VM that boot to the EFI Shell?
-
@Andrew they are all running Windows Server 2016 (v1607 Build 14393.7428).
-
You XOA had a disk full or a problem of storage, causing the Redis DB problem you've seen. I bet on a disk full (at least read only disk).
If XOA was on a same storage than your Windows VM, then your storage is having a problem, making it probably read only for Windows VM and causing all the visible results you've seen.
-
@olivierlambert So XOA is running on local storage of host #1 (VMH01) and all the VMs run off an NFS datastore which I've checked and is not in read-only mode or full (has about 60% free space).
What I haven't checked is whether the partition being used as the Local SR on VMH01 is perhaps the culprit. I ran
xe checkyesterday and the only three things it complained about were NTP, Updates, and not having Internet connectivity.I should be in the office in about an hour, so I'll inspect and report back.
-
@olivierlambert I checked the storage space on XOA, and looks fine to me ( see below ).
xoa:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 957M 0 957M 0% /dev tmpfs 197M 524K 196M 1% /run /dev/xvda2 19G 3.7G 14G 21% / tmpfs 982M 156K 982M 1% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock //TESTSVR01.LabNET.local/DataShare/Backups 944G 358G 587G 38% /run/xo-server/mounts/0e61c795-5704-4e8b-b299-b18732edfdb3 //TESTSVR01.LabNET.local/VMDatastore1/ 944G 358G 587G 38% /run/xo-server/mounts/def1b387-4b80-4bee-906f-e445694d3230 tmpfsI also checked the folder that I'm sharing out as an NFS share - which I'm using as the target for the SR in XOA, and it too looked okay to me ( see below
:")
$folderPath = "C:\VM_NFS_Datastore1" if ((Get-Item $folderPath).Attributes -band [System.IO.FileAttributes]::ReadOnly) { Write-Host "The folder is read-only." } else { Write-Host "The folder is NOT read-only." } The folder is NOT read-only.So I launched xoconsole from VMH01 and checked the status of both the NSF SR and the Local Storage SR, and they both look okay ( see below
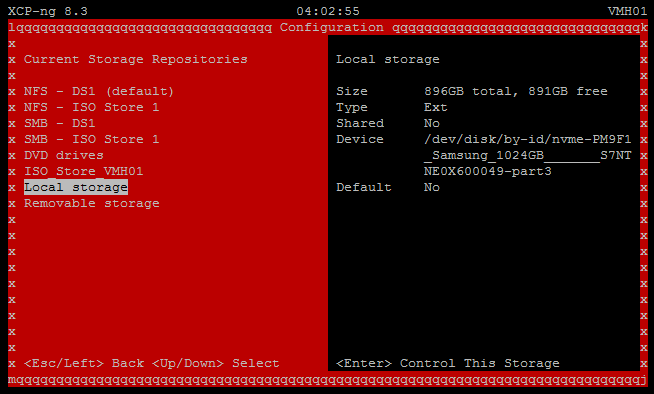
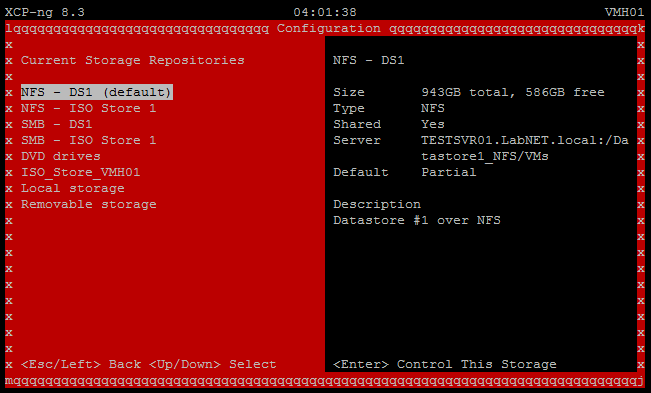
Is there a command I can run at the XOA CLI that will show me the state of the SR? Perhaps there's a read-only flag that's set within XOA that can be toggled off?
-
Good-day Folks,
While troubleshooting this issue with my sales rep, I shared a screenshot of one of my VMs and he noted that it was odd that the boot disk was connected as device
xvdbinstead ofxvda. So he asked me to go through and check if the VMs that were having problems booting, looked similar. I went through and confirmed that all the VMs that were failing to boot did not have an “xvda” device. I went through the Storage menu and found a few disks that did not have a name or description, which was quite odd (to say the least). I mounted each disk, one at a time, to one of the VMs and booted until I identified and renamed each of them. As it stands now, I’ve been able to get all the VMs back up and running again.However, that leaves some unanswered questions:
-
How does taking a snapshot of a the MAIL01 VM (which was built with two disks – Disk1 for OS and Disk2 for Data), cause the VM to have its
xvdadevice detached, and snowball that to other VMs? -
How is it that VDIs that I name myself during VM creation, all of a sudden become detached from their VMs and lose their name and description?
-
How does a VM Template lose its disk? Because I was able to identify the disk that’s supposed to be attached to the template, but now it’s orphaned, and I don’t know how to re-attach it to the template.
In any case, I’m glad this happened in this lab environment, so I'm willing to work with you all at Vates to see if we can do a root cause analysis to prevent this in the future. All I did was take a snapshot, and this is certainly not the experience I should have had (nor is what I'm used to seeing).
Some screenshots to illustrate what I saw:
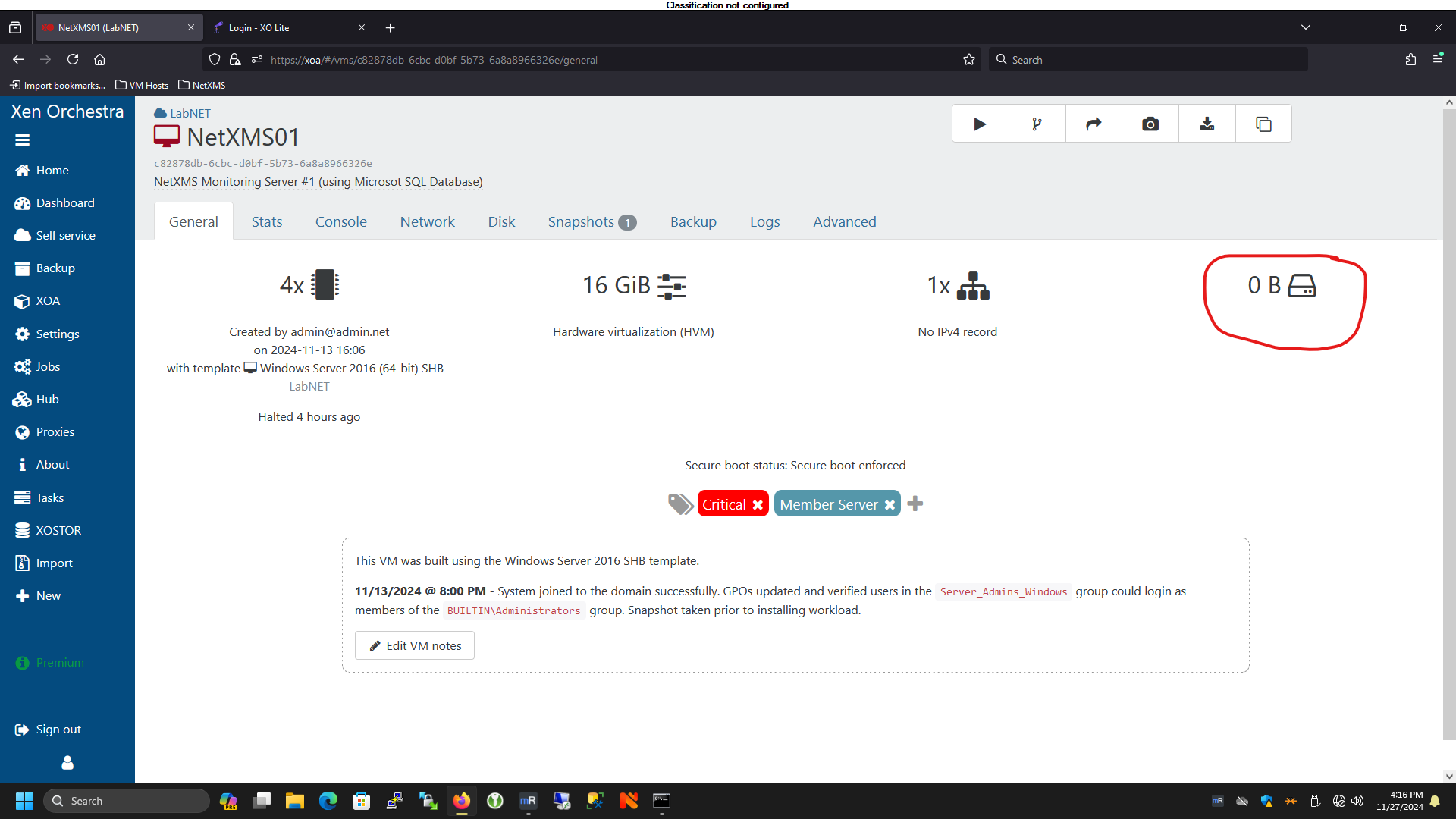
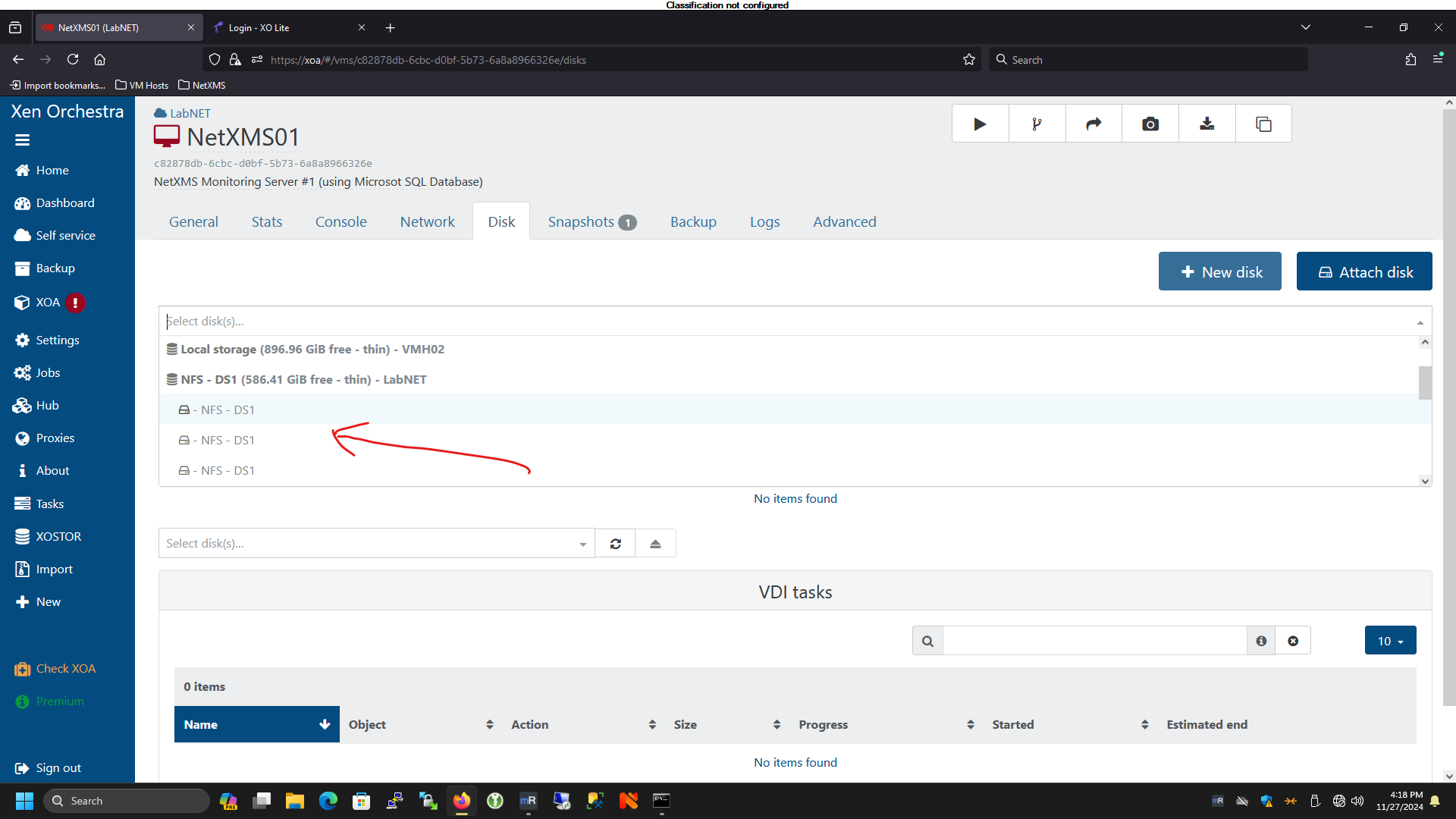
-
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login