CBT: the thread to centralize your feedback
-
@flakpyro very strange issue indeed, we can’t reproduce the problem on our end. So as @olivierlambert mentioned before it has to be something specific. The new developments make it indeed more difficult to understand, but i believe there is a logical explanation to this.
-
@flakpyro How do you migrate the VM already? I mean the exact steps you do.
-
In XOA i browse to the VM inventory list, search for the VM i want to migrate, check the box beside it, and click the migrate button located at the top right of the page, the "Migrate VM" popup appears and select the second host which is in the same pool, and click "Ok"
We have 2 pools i can reproduce this on:
The "Test Environment pool" with 2 HP DL325 Gen 10 servers backed by a TrueNAS MINI R running NFS 4.1
Our Production pool running 5 HP DL320 Gen 11 servers backed by a Pure //20R4 running NFS 3.
On the networking side:
Both pools are connected to 2 Aruba CX 10G switches (VSX Stack), each host as 4 physical connections:
2x !0G Bond0: Storage/Management/Backup, MTU 1500, VLANs for VM Traffic/Managemnt/Backup
2 x 10G Bond1: Dedicated storage: MTU 9000, ONLY used for NFS storage traffic on an isolated storage VLAN.
Both the TrueNAS and Pure use MTU 9000 on their "Storage" ports as well. I know Vates steers people away from Jumbo frames as a rule, and i agree but Pure engineering was pretty adamant about using them, so they are only present on these dedicated ports for storage only.
I will soon have a 3rd pool to test on as our DR site comes online next month, it will also be backed by Pure Storage.
I see others are also experiencing this issue as well now, looking at some more recent posts on this thread.
It should be noted regular backups with "NBD and CBT" enabled but with the snapshot deletion button turned off run without issue and have for months now proven themselves reliable. It would just be nice to not have to keep that snapshot daily
")
-
Could you try to migrate with
xeand see if you have the same issue? -
For sure, i ran:
xe vm-migrate uuid=a14f0ad0-854f-b7a8-de5c-88056100b6c6 host-uuid=c354a202-3b30-486b-9645-2fd713dee85fTo move the VM from host 1 to host 2....
Doing it this way i noticed checking the CBT log file does not result in all zeros being output.
[10:00 xcpng-test-01 45e457aa-16f8-41e0-d03d-8201e69638be]# cbt-util get -c -n 087ad136-f31b-4d7c-9271-7c926fd51089.cbtlog fe6e3edd-4d63-4005-b0f3-932f5f34e036For fun i then moved the VM back from Host 2 to host 1 and again, the cbtlog file seems to be intact:
[10:02 xcpng-test-01 45e457aa-16f8-41e0-d03d-8201e69638be]# cbt-util get -c -n 087ad136-f31b-4d7c-9271-7c926fd51089.cbtlog fe6e3edd-4d63-4005-b0f3-932f5f34e036After all this migrating i then ran a job which ran fine and without any errors about not being able to do a delta.
So it seems like it works fine via xe CLI
Update:
After the backup ran properly and generated a new CBT log file i then moved it back and forth between hosts again using the CLI. And the cbtlog file seems to stay in tact again when checking using cbt-util. When i do this with XOA the result from cbtutil is all zeros. -
Okay so back to being an XO issue regarding migration, like if XCP thought it was migrating storage. Ping @julien-f or @MathieuRA
@flakpyro can you provide screenshot on how you migrate with XOA?
-
Here is a screenshot of how i am doing the migration in XOA: moving from host 2 to host 1, leaving the SR drop down empty.
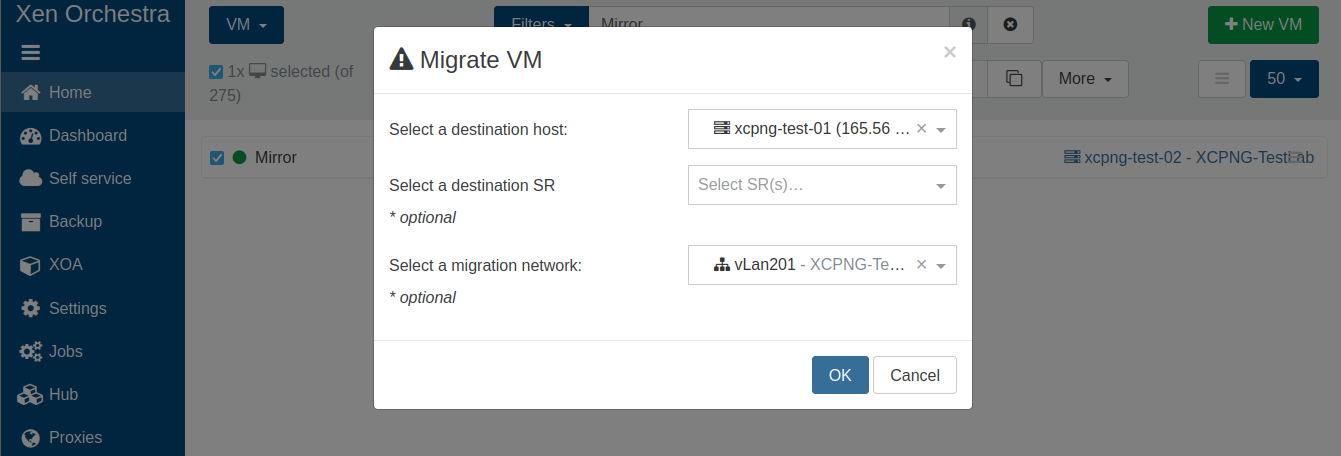
-
And when doing that, you are losing the CBT thing (like it's all 00000), right?
And if you unselect everything but the destination host, is it behaving the same?
-
@olivierlambert
We're making progress i think!Correct letting the migration run with those settings results in 0000 when running the cbt-check command.
I tried removing the migration network and ran a migration with the following settings:
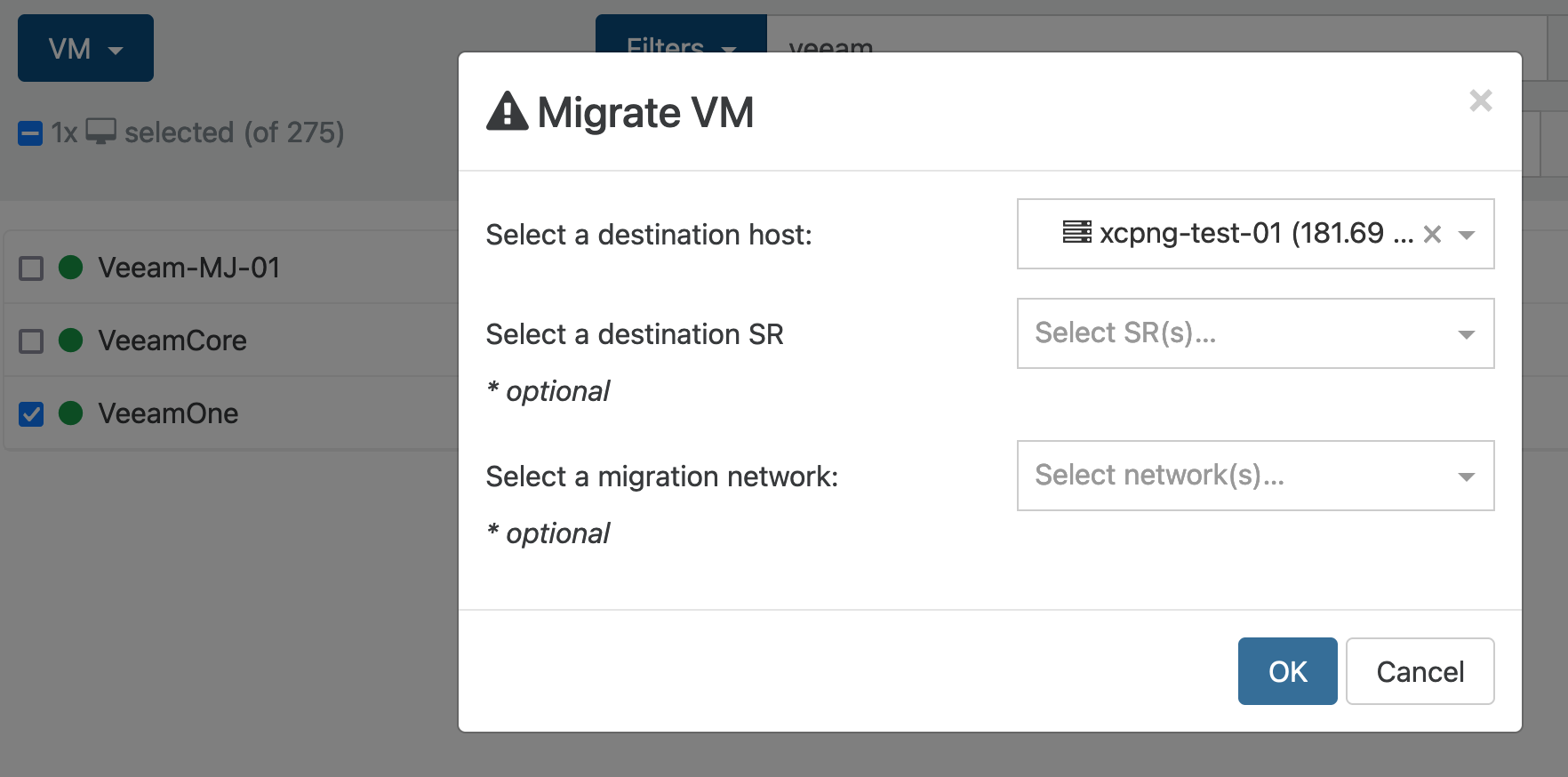
Before migration:
[14:27 xcpng-test-01 45e457aa-16f8-41e0-d03d-8201e69638be]# cbt-util get -c -n 7560326c-8b15-4c58-841f-6a8f962a7d28.cbtlog fe6e3edd-4d63-4005-b0f3-932f5f34e036And after migration:
[14:27 xcpng-test-01 45e457aa-16f8-41e0-d03d-8201e69638be]# cbt-util get -c -n 7560326c-8b15-4c58-841f-6a8f962a7d28.cbtlog fe6e3edd-4d63-4005-b0f3-932f5f34e036If i select a default migration network and run the same migration:
[14:31 xcpng-test-01 45e457aa-16f8-41e0-d03d-8201e69638be]# cbt-util get -c -n 7560326c-8b15-4c58-841f-6a8f962a7d28.cbtlog 00000000-0000-0000-0000-000000000000I think we're getting somewhere now! I have the migration network on both the test and DR pools. This used to be our "Vmotion" network back when we ran vsphere and i decided to continue using it to keep migration traffic on an isolated secure vlan.
In fact these Veeam VMs are not even being used anymore they exist in our test lab as VMs to mess around with for things like this.
-
So selecting the migration network is like triggering something in XO that makes XCP-ng moving the VDI like it was a storage migration (resetting the CBT status).
Ping @MathieuRA and/or @julien-f
-
@olivierlambert Glad we're getting to the bottom of this!
Out of curiosity is having an isolated migration network only available to the XCP-NG hosts considered best practice with XCP-NG? It was with VMware to keep VMotion traffic on its own subnet and since the VLAN was already created on our switches i decided to keep with that setup. Ideally we can get this fixed either way, I'm just curious if I'm doing something considered strange?
-
No it's not strange at all. It's not a bad practice neither
Now, I'd like to check something with
xe: migrate the VM but with the migration network selected. To see if this resets CBT or not. -
@olivierlambert
Im on it! However after searching the XCP-NG docs as well as the XenServer docs i can't see to find how to specify a migration network using xe from the cli. Are you able to provide me the flag i need to use? -
I don't remember the command but @MathieuRA should be able to tell you which call we do to the XAPI when we add a migration network.
-
@olivierlambert @MathieuRA once you are able to provide me xe migrate flag to specify a migration network i will test this ASAP. I think we're really close to getting to the bottom of this issue!
-
Hi All,
First of all best wished to you all for 2025! I have just deployed the latest build to do some testing on the one remaining issue we have with cbt backups, we were still facing full backups on some vms, this is expected to happen because cbt is not activated fast enough on some vdi’s, i will update this post once it completed some test runs to let u know if this build resolves it (there is a fix inside this build that should fix it).
Robin
-
Happy new year and thank you very much for the feedback provided in here
-
@olivierlambert my pleasure, good to be a part of it.
Good news, this bug seems to be resolved!
Hope we can fix the migration bug as well!
-
I think we have a pretty good idea of the cause now, It seems to be related to having a migration network specific at the pool level.
I think we are closer than ever to having this worked out and should help a lot of us using a dedicated migration network. (As was best practice in Vmware land) What are the next steps we need to take?
-
We need to wait for the largest part of the team to get back from vacation on Monday
")
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login