Backup fail whereas xostor cluster is "healthy"
-
Hello,
My post title may be missleading.
I built a pool with 3 nodes and 3 replicas.
- node1
- node2
- node3
When i remove node 3 ( linstor forget + xo forget node ).
The snapshot of disks are not possible anymore.
SR_BACKEND_FAILURE_1200(, local variable 'e' referenced before assignment, )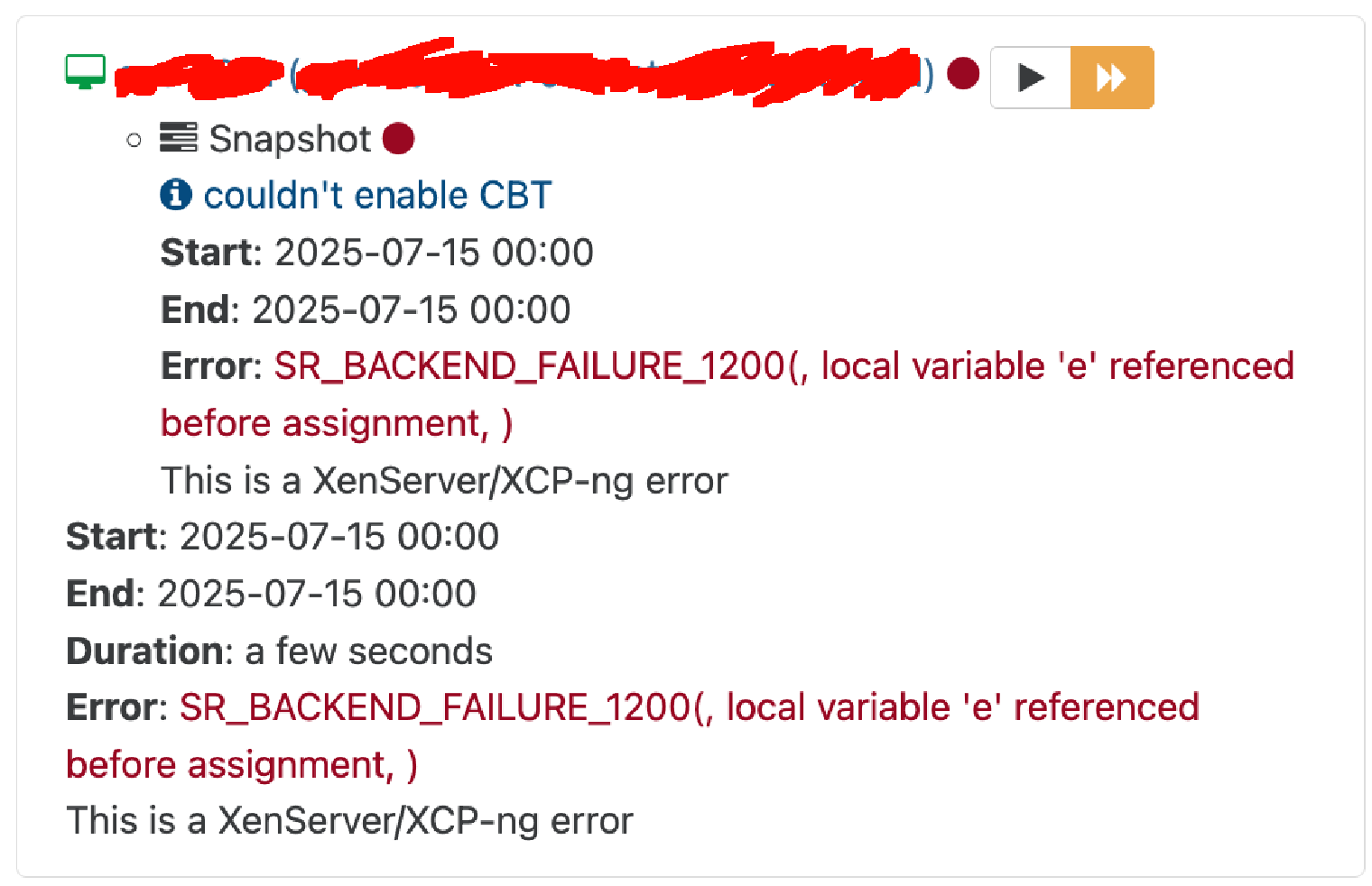
However, i have 2 healthy node on 3. it should work no ?
 ️ I don't need support, it's just an observation in our test pool, maybe a bug, i report
️ I don't need support, it's just an observation in our test pool, maybe a bug, i report ")
Best regards
-
Hi,
I think this issue is being fixed soon. Adding @dthenot in the loop to be sure
-
@henri9813 Hi! Just to confirm, can you share the exception in the SMlog file of the master host? We are aware of an exception in the same style, and it is a side effect of another exception caused in the _snapshot function of LinstorSR. We have already planned to correct it in a new version of the sm, it's been a while that it's there but not critical. Thanks!
-
Hello @ronan-a
I will reproduce the case, i will re-destroy one hypervisor and retrigger the case.
Thank you @ronan-a et @olivierlambert
If you need me to tests some special case don't hesit, we have a pool dedicated for this
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login