Weird performance alert. Start importing VM for no reason.
-
XCP-ng, updated
XO CE, commit 749f0 (now 2 behind)For some strange reason, I got performance alerts every minute starting at 05:00 this morning.
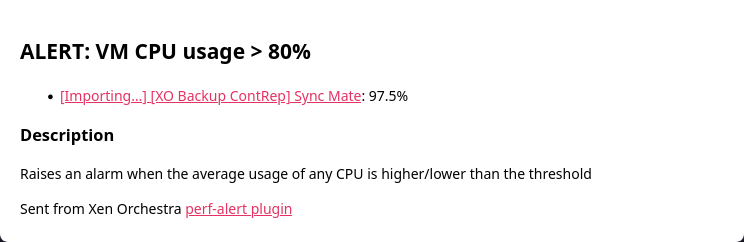
XO was trying to start/import a VM without any reason to.
The backup of this VM is started from a Sequence-job and this job was run from 03:04 to 03:05
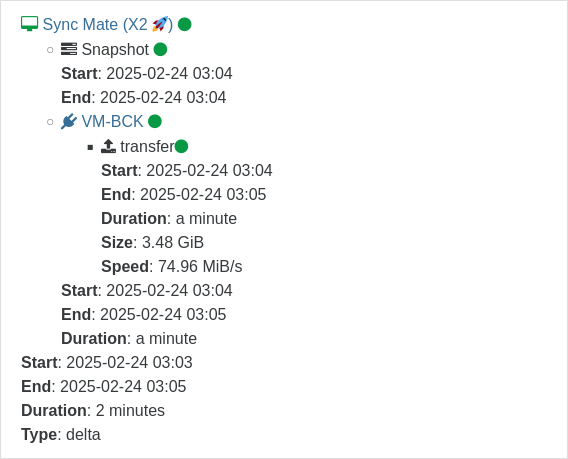
The ed2b-job has
health checkenabled, but should only run on 1st and 15th
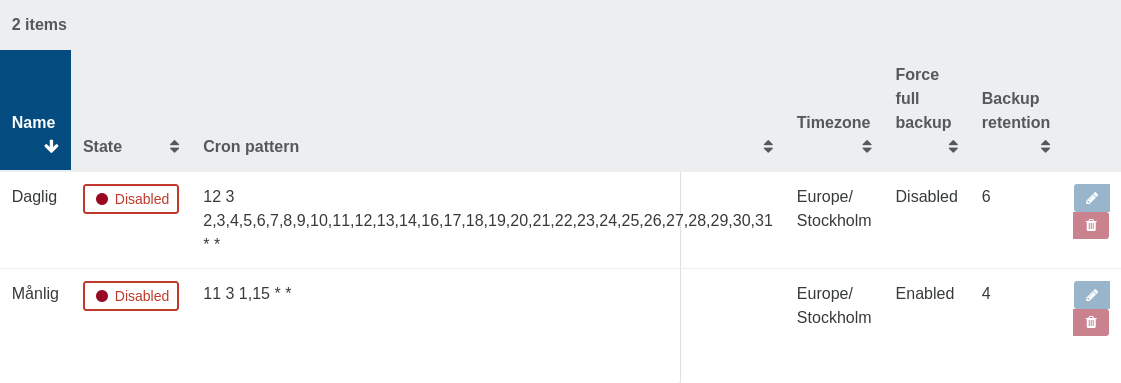
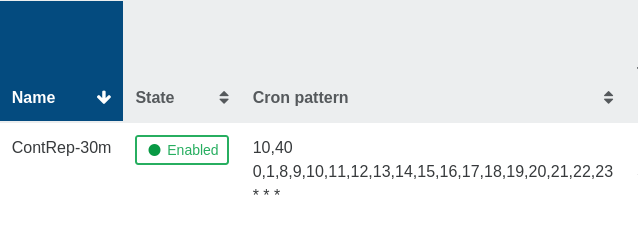
I also run a replication job during the day outside the backup schedule
The VM has autostart enabled, and maybe the host crashed and when it restarted it somehow thought it should auto start the replicated VM
Unfortunately I did destroy the VM but I did read that it was started 32min ago, and this was around 05:30.
Now when I checked the Host performance, there was nothing in the graph
[11:23 x2 ~]# uptime 11:26:44 up 6:37, 2 users, load average: 0,10, 0,09, 0,10The host did restart for some reason
I ran dmesg and at line 618 I found that I should run fsck
[ 3.459057] FAT-fs (sda4): Volume was not properly unmounted. Some data may be corrupt. Please run fsck.Maybe this isn't a backup problem, but I started investigating it as that
-
Continuous replication is using export/import mechanism, so I think that's the reason for this task
")
-
P ph7 referenced this topic on
-
@olivierlambert
All backups and Continuous replication ran fine during these ~ 15hours that the graphics was gone.
Do You have any clue what logs I can check -
In the replication job I keep
Replication Retention=2
So at the time of reboot, 03:48 UTC, there was 2 saved CR-jobs that ran at 01:10 and 01:40
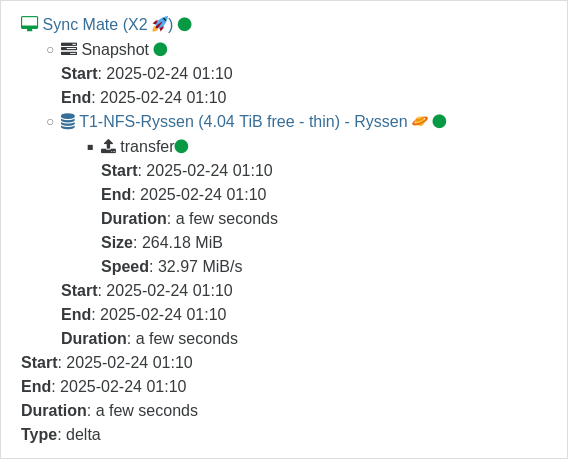
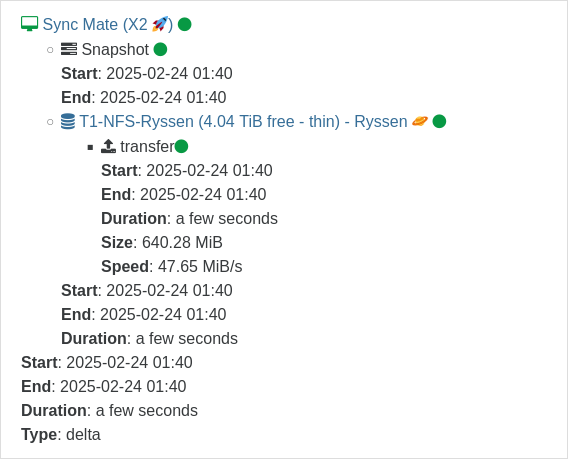
According to the time in red markings, The first alert ran at 05:00 CET (UTC + 1 hour)
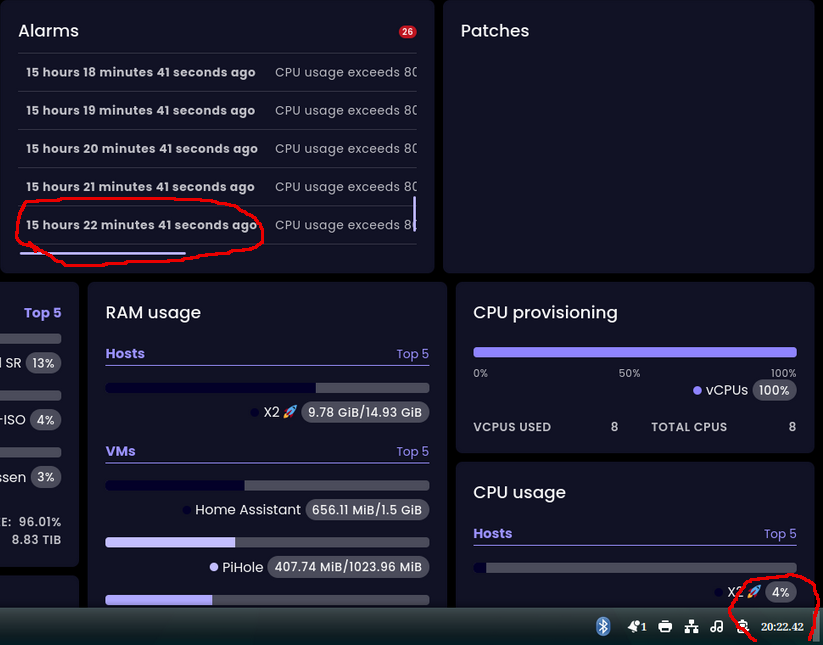
And this is from dmesg:
[ 0.994105] rtc_cmos 00:02: setting system clock to 2025-02-24 03:48:56 UTC (1740368936)I can not figure out
- why did the host reboot?
- why did one of the CR-jobs start ??
- why was there ~15 hours without any graph?
I have UPS with NUT-shutdown on the host and on my trueNAS, with no indication of power failure.
-
I increased the dom0 RAM from default 1.75 to 2 GiB
Hopefully this will do.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login