Delta backup fails for specific vm with VDI chain error
-
Now something strange happened:
To have at least some sort of recent backup I started a vm copy to the other host. It is currently only 10% through but while it was working I saw some activity in the SMLog and one after another, the stalled coalesce jobs disappeared.
I'll wait for the copy to finish and see if backup is now working again.
I'm with you Olivier, on "creating more new blocks than the SR can coalesce", but there's only double digit or low triple digit IOPS on the sr, barely throughput, etc. So there's very low load. Whenever some of the other vms' vdis get coalesced or when they are backupped stats pick up and we get several thousand IOPS, etc.
That's why I'd say that bare metal performance can't be the issue here. -
It's not bare metal perf, it's how coalesce prio is set with hard limits in the code. Feel free to dig inside it, I never had the time to do it myself
")
-
Hi mbt,
Sadly, when thing get that messy for me, I find that the only solution is to export the VM and then import. Thats one the (longest but most reliable) ways of de-leafing the tree.
Now, a trick I use, if downtime is an issue, is to do a Disaster Recovery backup to the same machine or SR. Once the backup is complete, I copy the MAC addresses for the network cards to the new VM (it will complain, but its OK), clear the blocked operations on the new VM, shutdown the original and then start the new.
If you use the above method, you can clear the blocked operation by using CLI:
xe vm-param-clear param-name=blocked-operations uuid=<NEW UUID>If you are using the "enterprise" or open source version, you can eliminate the amount of data that will be missing from the point of starting the DR backup and the starting up of the new server by performing a Continuous Replication while the server is still running and after the replication is finished, shut the server down, do a second Continuous Replication to sync the images and then perform the steps I mentioned above.
If you do the above, your downtime is in minutes and not longer.
I hope that helps a bit,
Peg -
We are not aware of that kind of coalesce issues, what kind of SRs do you have?
-
Hi Oliver,
The problem is of my own making and in no way blame XO for this. Its a perfect storm of events that caused my problem. Basically, I had a schedual that did delta backups to a local NFS repo. Later that night, I have 2 other jobs that do Cont Replication to 2 other DC's. Lastly, I have a monthly backup that spools to another NFS Repo that we backup to DLT tapes.. Basically what happened is some of the jobs got delayed finishing and they over-ran and were running on top of each other. The GC got overloaded and started to throw "Exception Timeout" and the situation just kept building and got worse. As a consequence, I started to get "Weird" things happening in the running VM's (long delays, sluggishness, crashing of daemons, etc..) Once I realized what was going on, it was to late and I am doing the above to about 200+ VM's to get it fixed.
We are using LLVMoiSCSI on Equal Logic PS6000's as the backend
If you want a laugh, this is what one of my VDI tree's looks like:
vhd=VHD-036594ed-6814-4afa-a063-c702d575316e capacity=21474836480 size=11580473344 hidden=1 parent=none vhd=VHD-0bf17661-b95f-4b5f-adf6-ef5b2ff0a039 capacity=21474836480 size=8388608 hidden=0 parent=VHD-036594ed-6814-4afa-a063-c702d575316e vhd=VHD-40df70e3-25b9-4875-a995-0f7497924afd capacity=21474836480 size=901775360 hidden=1 parent=VHD-036594ed-6814-4afa-a063-c702d575316e vhd=VHD-8b409ba8-77f4-4270-a36d-6d4c0091ed3c capacity=21474836480 size=8388608 hidden=0 parent=VHD-40df70e3-25b9-4875-a995-0f7497924afd vhd=VHD-5ec35406-34c0-4c9c-b92d-80df45f5e6c1 capacity=21474836480 size=1094713344 hidden=1 parent=VHD-40df70e3-25b9-4875-a995-0f7497924afd vhd=VHD-e039102b-ac33-487a-b38b-ccd60cf83573 capacity=21474836480 size=8388608 hidden=0 parent=VHD-5ec35406-34c0-4c9c-b92d-80df45f5e6c1 vhd=VHD-ccdfe0c5-6044-4131-8ce5-3b2129f083c2 capacity=21474836480 size=843055104 hidden=1 parent=VHD-5ec35406-34c0-4c9c-b92d-80df45f5e6c 1 vhd=VHD-26560aef-677c-498f-81e0-91cd791ec2ee capacity=21474836480 size=8388608 hidden=0 parent=VHD-ccdfe0c5-6044-4131-8ce5-3b2129f083 c2 vhd=VHD-91abb814-214b-4fe7-aac6-20f0177348cb capacity=21474836480 size=977272832 hidden=1 parent=VHD-ccdfe0c5-6044-4131-8ce5-3b2129f0 83c2 vhd=VHD-78cac789-3a46-4d79-87ff-0e8d28c17916 capacity=21474836480 size=8388608 hidden=0 parent=VHD-91abb814-214b-4fe7-aac6-20f0177 348cb vhd=VHD-aab84809-2165-4af3-9f47-a1b1ff4044f8 capacity=21474836480 size=1019215872 hidden=1 parent=VHD-91abb814-214b-4fe7-aac6-20f0 177348cb vhd=VHD-cdb89a9e-a583-461c-adc6-7b68c0e88556 capacity=21474836480 size=8388608 hidden=0 parent=VHD-aab84809-2165-4af3-9f47-a1b1 ff4044f8 vhd=VHD-78d28f42-9327-440c-bd72-46b0716252a8 capacity=21474836480 size=268435456 hidden=1 parent=VHD-aab84809-2165-4af3-9f47-a1 b1ff4044f8 vhd=VHD-76360be2-10b7-4be1-8cb6-b2595ed8f5df capacity=21474836480 size=8388608 hidden=0 parent=VHD-78d28f42-9327-440c-bd72-4 6b0716252a8 vhd=VHD-492d0a9f-8a1d-469d-8bbc-9bbdd910a83e capacity=21474836480 size=994050048 hidden=1 parent=VHD-78d28f42-9327-440c-bd72 -46b0716252a8 vhd=VHD-9276a1dc-185b-4299-b958-415dc52ee2f8 capacity=21474836480 size=8388608 hidden=0 parent=VHD-492d0a9f-8a1d-469d-8bb c-9bbdd910a83e vhd=VHD-c5017f51-309a-4e49-bf42-ce6a838212d2 capacity=21474836480 size=1111490560 hidden=1 parent=VHD-492d0a9f-8a1d-469d- 8bbc-9bbdd910a83e vhd=VHD-22a8f4fb-11ca-4caa-8439-ac8082482ca3 capacity=21474836480 size=8388608 hidden=0 parent=VHD-c5017f51-309a-4e49- bf42-ce6a838212d2 vhd=VHD-b0151f77-e694-437b-8ff2-f352871ad37d capacity=21474836480 size=243269632 hidden=1 parent=VHD-c5017f51-309a-4e4 9-bf42-ce6a838212d2 vhd=VHD-25fffec1-fb4d-4717-8bff-c2050eb49aa2 capacity=21474836480 size=8388608 hidden=0 parent=VHD-b0151f77-e694-43 7b-8ff2-f352871ad37d vhd=VHD-a0e6091b-3560-40bd-85ec-eb251e47366c capacity=21474836480 size=918552576 hidden=1 parent=VHD-b0151f77-e694- 437b-8ff2-f352871ad37d vhd=VHD-c40b1169-7d28-464c-9a6f-5309c7e2382d capacity=21474836480 size=8388608 hidden=0 parent=VHD-a0e6091b-3560 -40bd-85ec-eb251e47366c vhd=VHD-1038bb56-d4d9-49ef-b2fb-10319423cbd1 capacity=21474836480 size=264241152 hidden=1 parent=VHD-a0e6091b-35 60-40bd-85ec-eb251e47366c vhd=VHD-85b6bd0c-da46-41ab-8483-a831beeb0a0a capacity=21474836480 size=8388608 hidden=0 parent=VHD-1038bb56-d 4d9-49ef-b2fb-10319423cbd1 vhd=VHD-52b51deb-1c26-4101-a6b0-c2fde959c66b capacity=21474836480 size=830472192 hidden=1 parent=VHD-1038bb56 -d4d9-49ef-b2fb-10319423cbd1 vhd=VHD-4aa2d7d6-cf34-449d-8ee1-98e9b6a19bf5 capacity=21474836480 size=8388608 hidden=0 parent=VHD-52b51de b-1c26-4101-a6b0-c2fde959c66b vhd=VHD-57304603-4a25-4723-93cf-24564d3e96f3 capacity=21474836480 size=264241152 hidden=1 parent=VHD-52b51 deb-1c26-4101-a6b0-c2fde959c66b vhd=VHD-e28412b8-af76-4a72-85af-7780a97c7ae4 capacity=21474836480 size=8388608 hidden=0 parent=VHD-5730 4603-4a25-4723-93cf-24564d3e96f3 vhd=VHD-dedb2e9b-78e3-4067-92c9-42e3266c72cd capacity=21474836480 size=1946157056 hidden=1 parent=VHD-5 7304603-4a25-4723-93cf-24564d3e96f3 vhd=VHD-4b697f4c-2169-4d7c-a41a-718fd427745b capacity=21474836480 size=8388608 hidden=0 parent=VHD-d edb2e9b-78e3-4067-92c9-42e3266c72cd vhd=VHD-9ffc4f7c-c27a-4976-8c93-b1522822fab4 capacity=21474836480 size=21525168128 hidden=0 parent=V HD-dedb2e9b-78e3-4067-92c9-42e3266c72cd~Peg
-
IIRC, we got a protection on the same job to re-run on itself. But not between jobs.
I'm a bit surprised that our VDI chain protection didn't prevent this scenario.
-
<looks sheepishly as he admits> It probably would have.... The Cont replication jobs were running on a opensource version (different appliance) while the incremental and full (monthly) exports were being run on a Enterprise version.
Not sure if the VDI protection would pick up the other XOA jobs.
~Peg
-
Mixing jobs in various XO isn't a good idea in any case.
-
For the records:
After the vm copy that somehow seems to have triggered the coalescing the delta backup job and another weekly full backup job ran without any issues.
Today is going to be interesting. The daily deltas only run weekdays (Mo-Fr), the full backup on Sundays. The deltas ran fine, the full backup afterwards, too. But now I again see stuck vdi coalesce jobs on the sr's advanced tab.
Looks the same as last Monday. If it doesn't clear over the day I'll try the same trick from Friday and see if that works again.Interesting, that now twice in a row this happens after the full backup job.
-
Same as Friday. I started a copy of the vm and immediately the coalescing began and finished successfully shortly after.
-
mbt,
How are you copying the VM? Are you using XC or XO and are you doing a fast clone or a full copy? If you have the same problem as I do at the moment, using fast clone will not help your situation as it will not create a new tree for the VHD.
It does not surprise me that you are seeing the SMGC kick in. Some operations will ask the SM to re-scan the SR and this will also cause the SMGC to start. If you previously had a stuck job that "Exceptioned" the GC will try again, and if the VM is shutdown, it will be able to do a offline coalesce.
See if you can get a tree view of your VDI's and look for something that has a lot of indents in it.. What type of SR do you use? iSCSI or NFS?
~Peg
-
Hi Peg:
I did a full copy in XO.Coalescing of the vm's vdis is blocking the backup again.

I can tell from the log, that SMGC ist doing something. In htop I can also see the "vhd-util check" running at 100% cpu, then stopping, then a "vhd-util coalesce" runs and does the reading / writing.
When I wrote here last week, there was always only a "vhd-util check", no coalesce, until I did the VM copy.May it be the "vhd-util check" is taking too long? This is what I see consuming most of the time. The actual coalescing of maybe 100MB, 200 MB is done in a splitsecond.
How do I get a tree view of my vdis?
The system is a brand new 2x Intel Xeon Silver 4110 8Core, 2.1GHz. The sr is a local LVM sr and sits on a 4x 1.9TB SATA SSD hardware RAID and 128 GB RAM. Both pool members are identical.
Here is a part of the log as example:
Aug 27 10:29:55 rigel SMGC: [11997] Num combined blocks = 154287 Aug 27 10:29:55 rigel SMGC: [11997] Coalesced size = 301.938G Aug 27 10:29:55 rigel SMGC: [11997] Leaf-coalesce candidate: 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) Aug 27 10:29:55 rigel SMGC: [11997] Leaf-coalescing 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) -> *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:29:55 rigel SMGC: [11997] Got other-config for 7ef76d55[VHD](500.000G/170.450M/500.984G|ao): {} Aug 27 10:29:55 rigel SMGC: [11997] Single-snapshotting 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) Aug 27 10:29:58 rigel SMGC: [11997] Single-snapshot returned: OpaqueRef:12365b17-46e6-4808-adeb-538ef12eed73 Aug 27 10:29:58 rigel SMGC: [11997] Found new VDI when scanning: c220c902-8cf7-4899-b894-15c4723b5973 Aug 27 10:29:58 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 27 10:29:58 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 27 10:29:58 rigel SMGC: [11997] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 10:29:58 rigel SMGC: [11997] *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:29:58 rigel SMGC: [11997] *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:29:58 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:29:58 rigel SMGC: [11997] Aug 27 10:29:58 rigel SMGC: [11997] Coalescing parent *c220c902[VHD](500.000G//172.000M|ao)Where it says "10:29:58 Coalescing parent" is, when the "vhd-util check" runs. Around 90 seconds later:
Aug 27 10:31:28 rigel SMGC: [11997] Removed vhd-blocks from *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:28 rigel SMGC: [11997] Set vhd-blocks = eJzt2sttwkAUBVCDkGARKS6BEihh0klKeYsUQgkpIaWklAAmWTgKKP7wyOQce2Fbnrl3a/lFAwAAwJw2L9kNgMguALWL7AKMFtkFGC4yw5eZ4QAAAAAAAHCfnqLtLtpmldsk024R2RWoWskuANy55+wC01tHdgPgpuI8GxhjNnl8Hbz07XAcvY/JBxigZBe4yvg0AAAwjUjO3ybn75PzAcgR3y7g/9if/7/NYDHXxtQjUlLL1wTt8PxN777bqfRfW54e/Tixezm/9D+QVqezGwRuL/fjL4hfvl/b+PPn/Mk2tQUAtxYj15emeZigBgAAAABQoQ8pNhSV for *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:28 rigel SMGC: [11997] Set vhd-blocks = (lots of characters) for *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:28 rigel SMGC: [11997] Num combined blocks = 154287 Aug 27 10:31:28 rigel SMGC: [11997] Coalesced size = 301.938G Aug 27 10:31:28 rigel SMGC: [11997] Running VHD coalesce on *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:31 rigel SMGC: [11997] Child process completed successfully Aug 27 10:31:31 rigel SMGC: [11997] Set vhd-blocks = (lots of characters) for *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:32 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): no changes Aug 27 10:31:32 rigel SMGC: [11997] Relinking 7ef76d55[VHD](500.000G//500.984G|ao) from *c220c902[VHD](500.000G//172.000M|ao) to *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:32 rigel SMGC: [11997] Set vhd-parent = 775aa9af-f731-45e0-a649-045ab1983935 for 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:32 rigel SMGC: [11997] Updated the vhd-parent field for child 7ef76d55-683d-430f-91e6-39e5cceb9ec1 with 775aa9af-f731-45e0-a649-045ab1983935 Aug 27 10:31:32 rigel SMGC: [11997] Reloading VDI 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:33 rigel SMGC: [11997] Got other-config for 7ef76d55[VHD](500.000G/162.434M/500.984G|ao): {} Aug 27 10:31:33 rigel SMGC: [11997] Single-snapshotting 7ef76d55[VHD](500.000G/162.434M/500.984G|ao) Aug 27 10:31:36 rigel SMGC: [11997] Single-snapshot returned: OpaqueRef:47f3c5e9-8ddb-4f27-8e7c-295c89db3026 Aug 27 10:31:36 rigel SMGC: [11997] Found new VDI when scanning: 78ab27a9-92a4-4b02-94a7-261283fde7c9 Aug 27 10:31:36 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 27 10:31:36 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 27 10:31:36 rigel SMGC: [11997] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 10:31:36 rigel SMGC: [11997] *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:36 rigel SMGC: [11997] *78ab27a9[VHD](500.000G//164.000M|ao) Aug 27 10:31:36 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:36 rigel SMGC: [11997] Aug 27 10:31:36 rigel SMGC: [11997] Coalescing parent *78ab27a9[VHD](500.000G//164.000M|ao)And so on...
So yes, it seems like Olivier said, that the system is not coalescing fast enough. The most time seems to be spent in "vhd-util check". I assume that is a process that checks for changed blocks?
What I am not getting is:
Why is it too slow?
Why now?The vm has no heavier usage compared to the past years. It's been running without such problems on SAS HDDs with XCP-ng 7.x and Xenserver using XO before.
Btw. I'm seeing exceptions again (they were gone last week after the vm copy):
Aug 27 10:41:21 rigel SM: [31806] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:42:55 rigel SM: [571] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:42:58 rigel SM: [924] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:43:00 rigel SM: [1512] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:35 rigel SM: [2833] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:36 rigel SM: [3083] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:38 rigel SM: [3641] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:12 rigel SM: [4876] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:13 rigel SM: [5083] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:15 rigel SM: [5636] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! -
Do you have the same issue on the other host on its local SR?
-
I moved the vm last week to the other host and checked if the delta job worked but it didn't. But I didn't give it time to maybe coalesce. I'll migrate the vm and check that out.
One question for my understanding:
The line "Coalesced size = xxx" - does it mean how much of the vhd size is coalesced right now?
I can see that number in the logs slowly increasing over time.For example:
Aug 27 04:03:13 rigel SMGC: [11997] Coalesced size = 276.902G Aug 27 05:16:01 rigel SMGC: [11997] Coalesced size = 276.906G Aug 27 06:01:39 rigel SMGC: [11997] Coalesced size = 276.910G Aug 27 07:05:36 rigel SMGC: [11997] Coalesced size = 292.246G Aug 27 08:03:28 rigel SMGC: [11997] Coalesced size = 298.625G Aug 27 09:00:06 rigel SMGC: [11997] Coalesced size = 301.609G Aug 27 10:01:26 rigel SMGC: [11997] Coalesced size = 301.770G Aug 27 10:56:06 rigel SMGC: [11997] Coalesced size = 301.938GAnd I got 475 entrys from 4 a.m until now (11 a.m.).
FYI: There's a total of 12 VMs on both pool members, including the XO vm.
-
@Peg:
Not sure if this is the vdi tree you mentioned, but I get this when triggering a sr rescan in the log:
Aug 27 11:04:52 rigel SMGC: [28194] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): Aug 27 11:04:52 rigel SMGC: [28194] 03035c65[VHD](40.000G//40.086G|n) Aug 27 11:04:52 rigel SMGC: [28194] 03190d28[VHD](10.000G//10.027G|n) Aug 27 11:04:52 rigel SMGC: [28194] *f74fa838[VHD](15.000G//14.633G|ao) Aug 27 11:04:52 rigel SMGC: [28194] a23e7cbd[VHD](15.000G//15.035G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *62feee6c[VHD](50.000G//36.227G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 667cf6a9[VHD](50.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 19333817[VHD](50.000G//50.105G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *43454904[VHD](500.000G//500.949G|ao) Aug 27 11:04:52 rigel SMGC: [28194] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *775aa9af[VHD](500.000G//301.961G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *894dbc3a[VHD](500.000G//21.406G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *cb9ff226[VHD](40.000G//34.605G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *2a99181e[VHD](40.000G//4.238G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 6371a662[VHD](40.000G//40.086G|ao) Aug 27 11:04:52 rigel SMGC: [28194] e5af497f[VHD](40.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] b70f6e7f[VHD](40.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *0494da11[VHD](100.000G//2.207G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 63b37e30[VHD](100.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 2ca68323[VHD](100.000G//100.203G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *d80f9f3d[VHD](70.000G//28.410G|ao) Aug 27 11:04:52 rigel SMGC: [28194] bfb778e9[VHD](70.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *f56b9b4e[VHD](70.000G//716.000M|ao) Aug 27 11:04:52 rigel SMGC: [28194] 3978cd9a[VHD](70.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 1c6e7b14[VHD](70.000G//70.145G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *971a59b8[VHD](10.000G//5.859G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 48edb7f4[VHD](10.000G//10.027G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 5dddf827[VHD](10.000G//8.000M|n) -
I wonder why it's so slow. What's your load average on the dom0?
It could worth to investigate about the SR speed, coalesce is doing a lot of small random read/writes. You have a bottleneck somewhere.
-
Hi Olivier!
[11:09 rigel ~]# uptime 11:09:41 up 28 days, 21:18, 3 users, load average: 1,13, 1,28, 1,29As I mentioned, usually it is "vhd-util scan" running 100% on a single core with no disk read / write at all according to htop. Then comes "vhd-util coalesce" with e.g. 270 M/s read / 120 M/s write
I'm not sure what the sr stats in XO are showing as I sometimes see the coalescing i/o in htop without anything going on in the stats. Currently it looks like this:
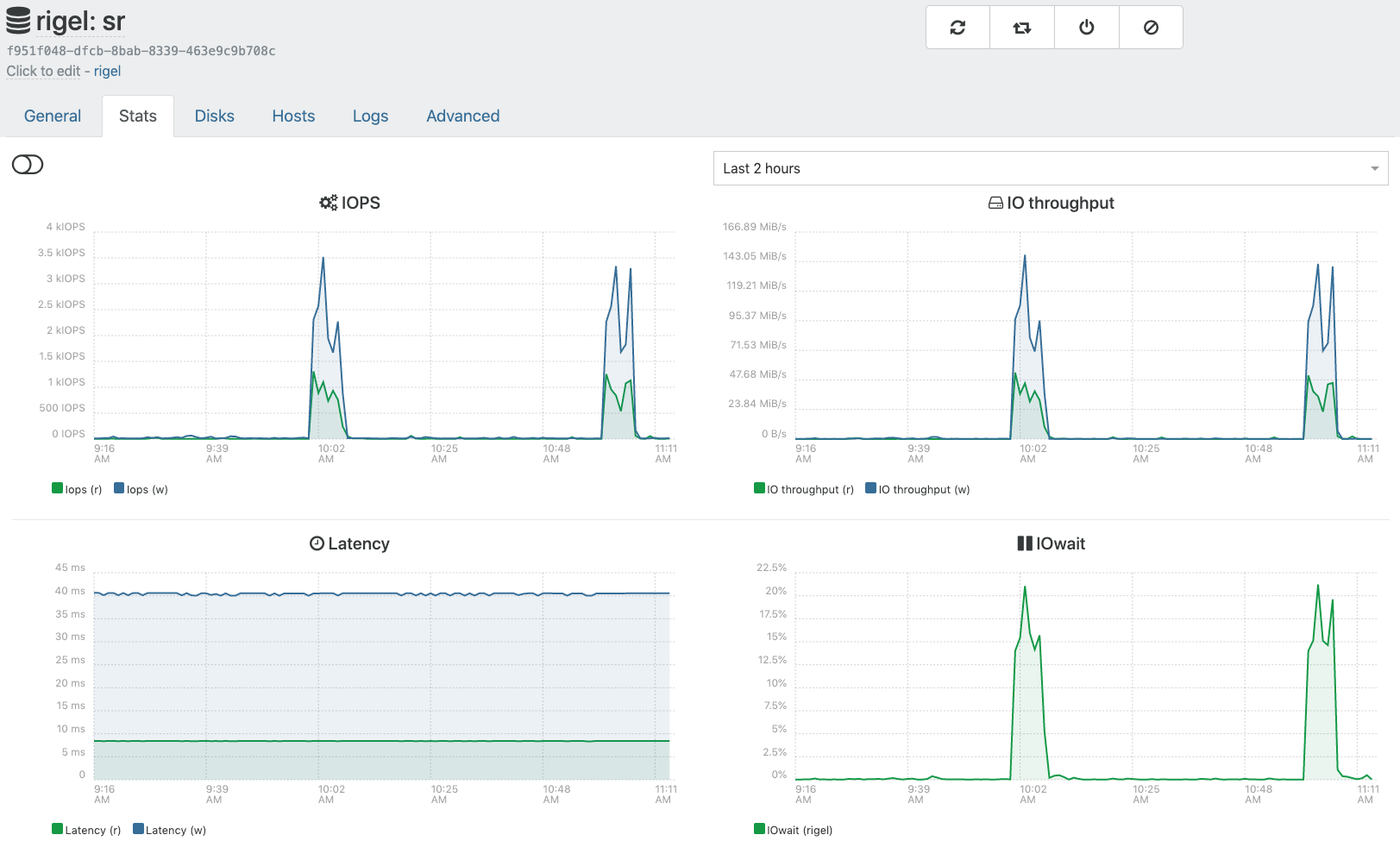
-
How long is your chain in XO SR view/Advanced tab
-
Usually looks like this:
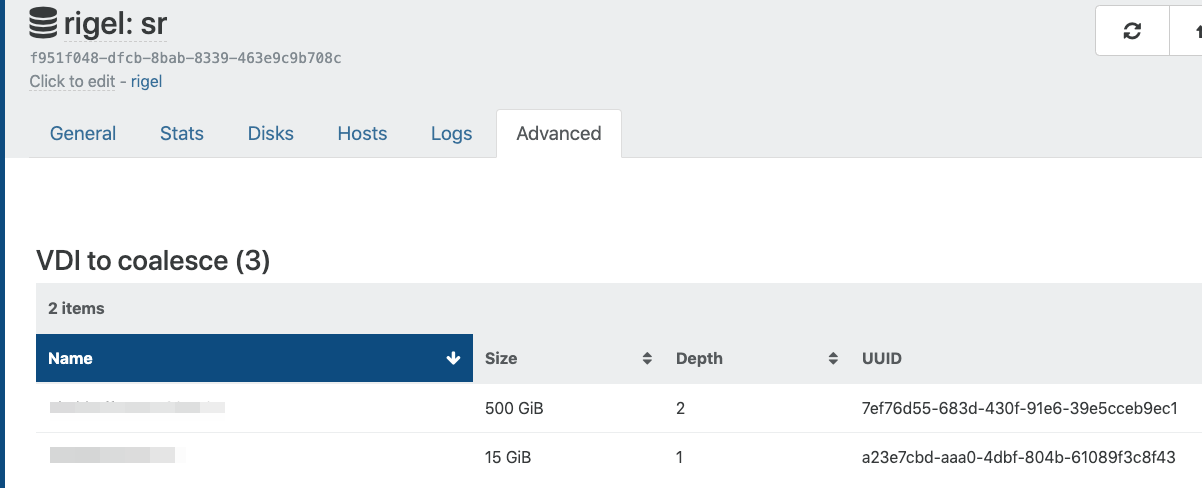
Sometimes the 500 GB vdi depth goes down to 1 for a couple of seconds max.
-
Can you do a
xapi-explore-srso I can see the whole chain in details?