Monitoring disk usage of thin provisioned disks
-
Hello,
I have several hosts in production with thin provisioned disks on Ext3 SRs. I'm looking for a way to see the actual disk usage of each VHD or at least each virtual machine, but I am not seeing this anywhere. I can see total disk usage of the SR and how much I have overprovisioned, but I am not seeing actual disk usage of each VHD and/or snapshots. (I don't currently have any snapshots, as I generally run a full replication to my second site before major changes to VMs.)
I found this thread where someone wrote a bash script I have yet to try, but I would much rather see this on a web interface as opposed to getting a console on dom0 and running a script against individual VMs. Am I missing it somewhere? (entirely possible)
Thanks for all you do, Olivier and team!
-
I had trouble with the bash script, as syntax didn't translate well from the website and appears to have sourced another unpublished script which would have to be recreated. also should mention that I am running XCP-ng 8.0.0 on all hosts.
-
Was actually thinking of the same thing yesterday. It would be really interesting to see in XOA:
- Actual disk usage for each VM
- Actual disk usage for each backup on the remote
It isn't too difficult to find the UUID of the VDI and check on the NFS server, but it is tedious and not straight forward.
-
The actual disk usage would be only viable for thin pro SR (hence, VMs with disks on thin pro SR).
Where would you imagine to put this info exactly?
-
@olivierlambert Yes, I understand this would only be useful for thin provisioned SR. In the past on other hypervisors I had to deal with disk space issues on an SR which was overprovisioned, and it is helpful to quickly determine which VMs are bloating their storage usage to be able to make a decision to delete snapshots or move a VM to a different storage or host. My thought was to see it on the disks listing in the SR in order to see an overview of how that particular SR is being utilized.
I made an example of how it could look based on a screenshot from XO:
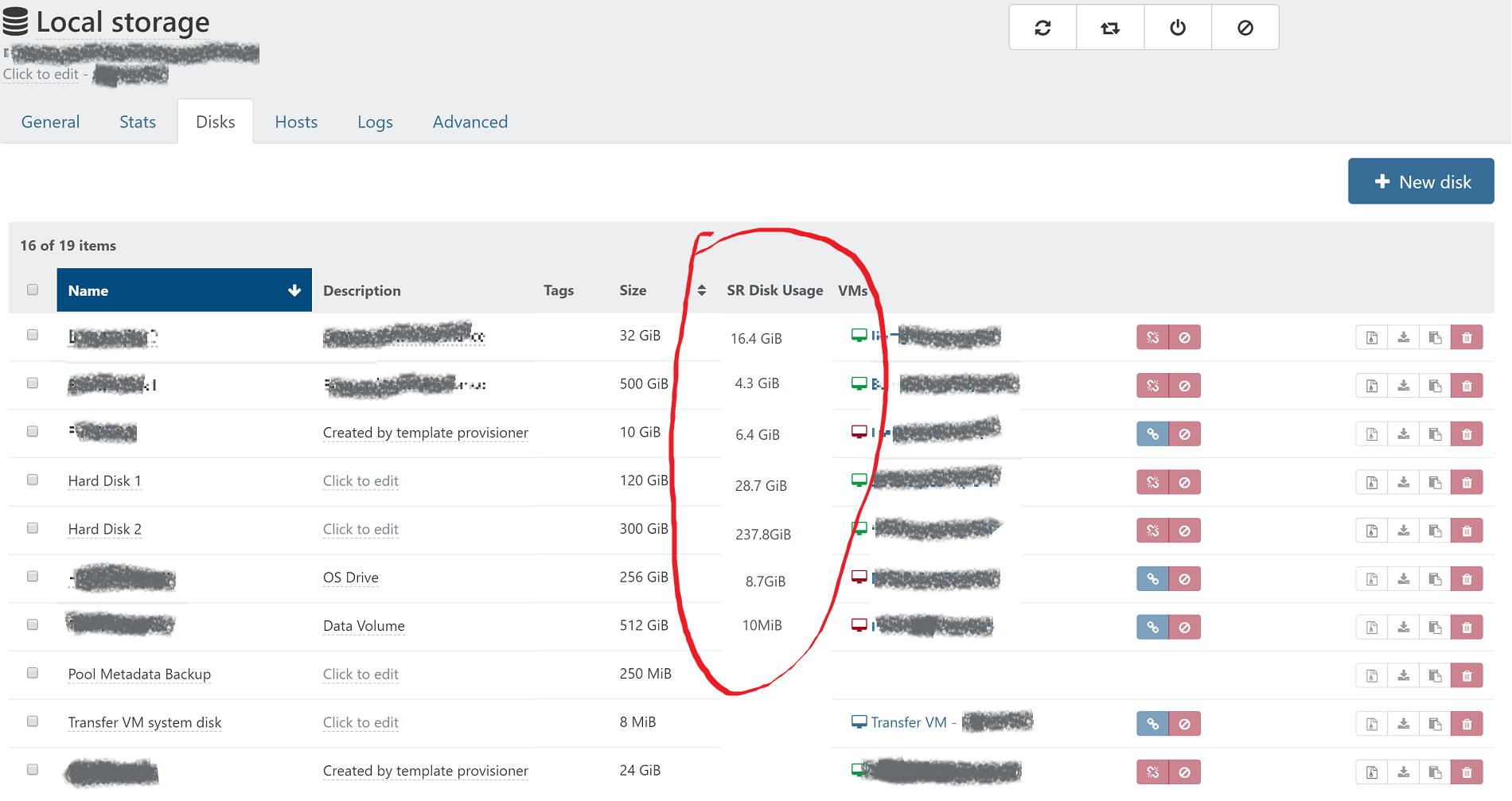
I think it would also be helpful to list the actual disk usage on the disks and snapshots pages for each individual VM. I think the total of base vhd and snapshots on the disks tab, and each individual snapshot size on the snapshots page. Here is how that could look:
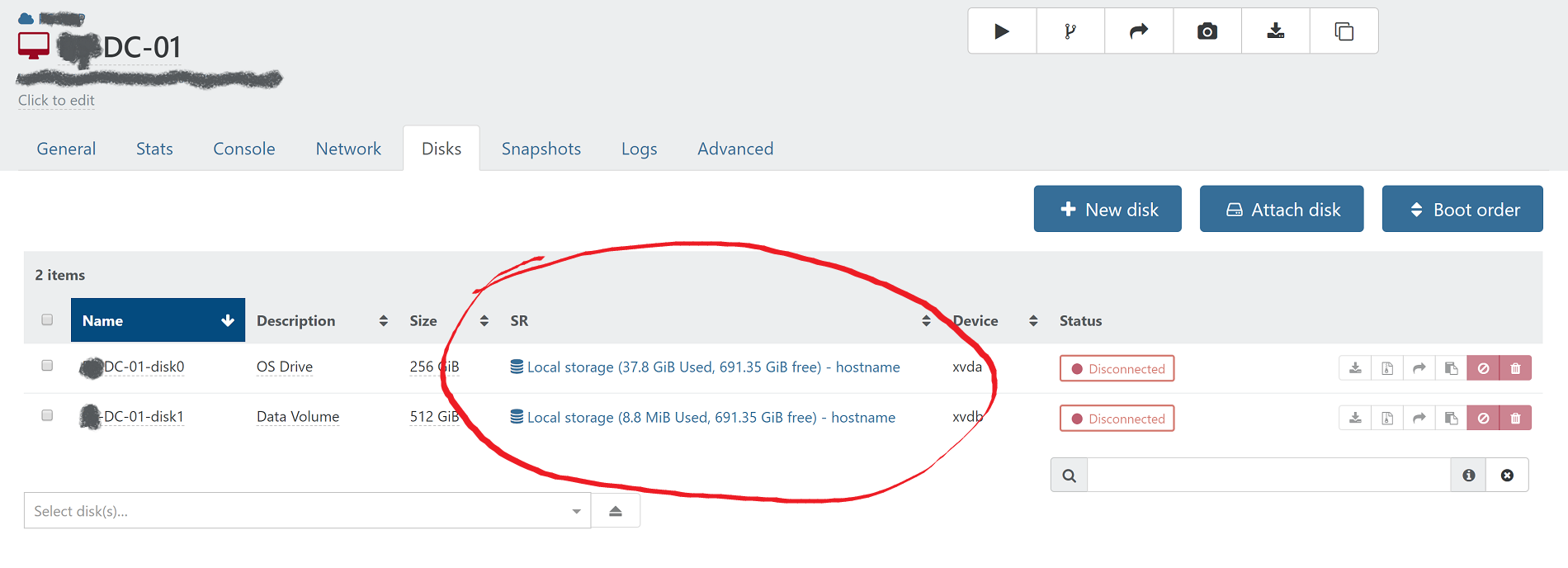
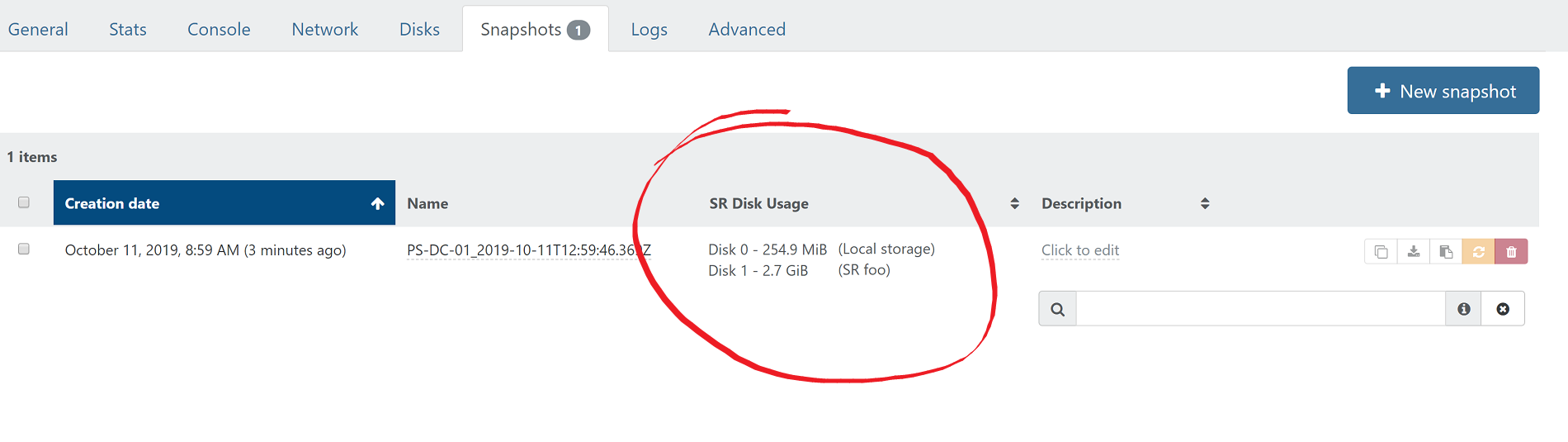
-
It's a bit more complicated than that. Eg a snapshot won't consume space per se, it's the base copy which will use some space.
So the question is: what do you really want to know? active vdi usage for a disk, total chain space of the snapshot and all its parents? only one parent?
-
I was kind of thinking about that as far as snapshots are concerned. I don't know how to calculate it, but ultimately I would want to know how much disk space would be freed if I deleted a particular snapshot. I understand that could be difficult (impossible?) to determine.
I think the seeing snapshot disk usage is less important than seeing the total SR disk usage of the VM. Typically the first thing I would do when trying to free up disk space would be to just remove unnecessary snapshots first, not really worrying about exactly what size they are.
So in my opinion, the most important thing to see would be the current actual disk usage on the SR for the VM's disks, which I think would be adding up the base vhd size plus the size of all snapshots in the chain and showing that total on the SR disks tab and/or the VM disks tab.
-
Let me explain a bit more. A snapshot is just a pointer toward the read only
base copy. It's only few KiB big.However, if you remove it, the active disk (current VM blocks written since the snapshot) will be merged inside the
base copy, and the result will be the new active disk.So removing the snapshot, is the end, **asking to merge the active disk inside the
base copy. How to guess the result of this? Impossible to predict before the actual coalesce (computing the coalesce will need the resources of doing the actual coalesce). -
What you said so well was my basic understanding, so to use your terminology, adding the active disk plus others in the chain if there are more snapshots, plus the base copy would be what I would think of as current disk usage.
I suspected that to calculate the snapshot size, the coalesce would have to be computed, so that sounds like too much of a strain on the system to implement. I think simply adding up the total size of the chain from the active disk back to the base image and putting that somewhere would be most helpful with the least impact on the systems performance.
-
Current disk usage for an active disk is:
- active disk space used
- base copy disk space used
Obviously, if you have a bigger chain (more than 1 parent) you need to compute the space of the whole chain until the parent (but does it make sense? because most of the space is due to addition of the chain, also a chain can be a tree, with multiple active disks if you converted snapshots to active disks)
-
Oh boy, this can be complicated. I think I opened up a can of worms!

 I'm really not sure what is most useful until I can see it in action. Another example of where I would use this is to determine if migrating the VM to another SR is possible because of disk space constraints on the target. Again in this case, I would first probably get rid of any snapshots before moving, so really the size of whatever would be moved, possibly including metadata for the VM itself, though that amount is trivial compared to base and active disks.
I'm really not sure what is most useful until I can see it in action. Another example of where I would use this is to determine if migrating the VM to another SR is possible because of disk space constraints on the target. Again in this case, I would first probably get rid of any snapshots before moving, so really the size of whatever would be moved, possibly including metadata for the VM itself, though that amount is trivial compared to base and active disks. -
When you use storage migrate, I think only one (or two?) snapshot max can be sent on destination. In a thin pro scenario, it shouldn't be a problem.
-
From my point of View you need only to monitor free space to stay out of torubles. You check free space in dashboard. Also let's call it good admin never overcoomits available resources. That's you task to know how much disk space you can allocate in the vms.
-
@schmalztech said in Monitoring disk usage of thin provisioned disks:
@olivierlambert Yes, I understand this would only be useful for thin provisioned SR. In the past on other hypervisors I had to deal with disk space issues on an SR which was overprovisioned, and it is helpful to quickly determine which VMs are bloating their storage usage to be able to make a decision to delete snapshots or move a VM to a different storage or host. My thought was to see it on the disks listing in the SR in order to see an overview of how that particular SR is being utilized.
I made an example of how it could look based on a screenshot from XO:
I think it would also be helpful to list the actual disk usage on the disks and snapshots pages for each individual VM. I think the total of base vhd and snapshots on the disks tab, and each individual snapshot size on the snapshots page. Here is how that could look:
How you enable that field SR DISK USAGE my xenorchestra not have it.
Im using xenorchestra comunnity edition -
It's because it's a fake, edited to show how we would like to have it
")
If you need that, please open an issue in XO bugtracker, only after checking there isn't an existing same request
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login