Alert: Control Domain Memory Usage
-
@stormi The ID for the case I just opened is 80240347. If you have a bugtracker issue open, you may want to mention that ticket. I just now opened the ticket, though, so it will be a while before it makes its way out of tier 1, etc.
EDIT: Had the wrong case number at first. Updated case number.
-
We also have an issue with growing control domain memory:
- XCP-ng 8.2
- NFS shared storage
- the poolmaster (xen19 is one of them) are more affected than pool members
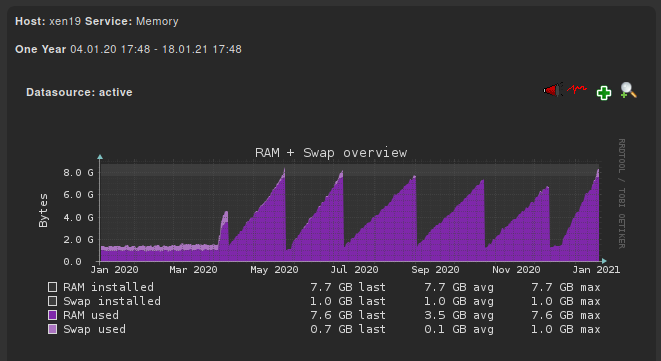
Today I install the alternate kernel on one of our poolmaster to see if that resolves our issue.
-
I noticed in my monitoring graphs, that since we have this issue, the SWAP is not used like before the issue:
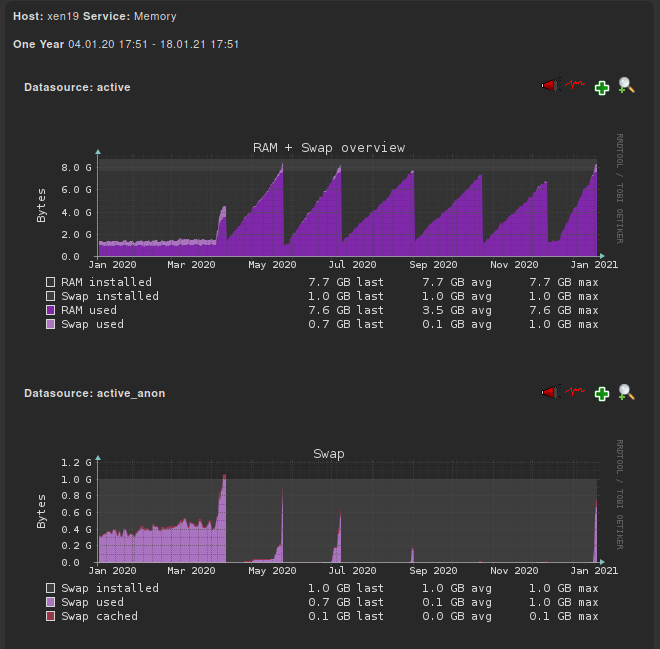
-
looked in my yum.log on this server (xen19):
our problems startet exactly since "Apr 10 18:10:29 Installed: kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64"
yum.log.4.gz:Oct 03 17:35:54 Installed: kernel-4.4.52-4.0.7.1.x86_64 yum.log.4.gz:Nov 20 18:29:29 Updated: kernel-4.4.52-4.0.12.x86_64 yum.log.2.gz:Oct 10 20:19:31 Updated: kernel-4.4.52-4.0.13.x86_64 yum.log.1:Apr 10 18:10:29 Installed: kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64 yum.log.1:Jul 07 17:46:34 Updated: kernel-4.19.19-6.0.11.1.xcpng8.1.x86_64 yum.log.1:Dec 10 17:59:07 Updated: kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 yum.log.1:Dec 19 13:53:39 Updated: kernel-4.19.19-6.0.13.1.xcpng8.1.x86_64 yum.log.1:Dec 19 13:55:20 Updated: kernel-4.19.19-7.0.9.1.xcpng8.2.x86_64 yum.log:Jan 18 17:35:07 Installed: kernel-alt-4.19.142-1.xcpng8.2.x86_64 -
@borzel How frequently do you restart VMs? And what's the last dom-id?
# xl list -
@r1 in general we do not restart many of our VMs, its all very static, only manual operated
xen19 is now rebootet (we need it in production) with kernel-alt - highest id is currently 4
xen22 (pool master of another affected pool) - highest id is curently 30
memory graphs of xen22
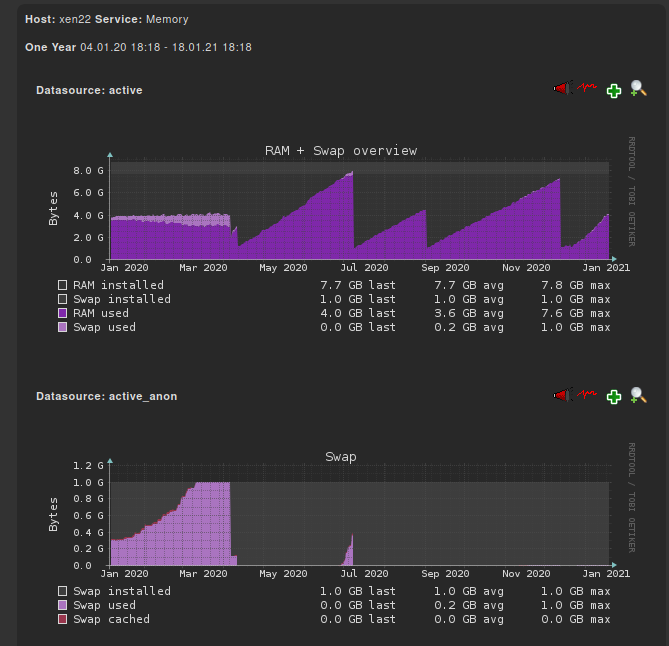
yum.log of xen22 (Problem here also after installing kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64)
yum.log.5.gz:Dec 19 00:52:47 Updated: kernel-4.4.52-4.0.12.x86_6 yum.log.3.gz:Nov 08 10:07:40 Updated: kernel-4.4.52-4.0.13.x86_64 yum.log.1:Apr 10 20:31:01 Installed: kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64 yum.log.1:Aug 31 23:10:50 Updated: kernel-4.19.19-6.0.11.1.xcpng8.1.x86_64 yum.log.1:Dec 11 18:00:54 Updated: kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 yum.log.1:Dec 19 12:52:00 Updated: kernel-4.19.19-6.0.13.1.xcpng8.1.x86_64 yum.log.1:Dec 19 12:54:13 Updated: kernel-4.19.19-7.0.9.1.xcpng8.2.x86_64 -
@borzel Between 4.19.19-6.0.9 to 4.19.19-6.0.10, following two patches were added.
0001-block-cleanup-__blkdev_issue_discard.patch 0001-block-fix-32-bit-overflow-in-__blkdev_issue_discard.patchBoth are well vetted and seems stable without any further changes in them. Was there anything else updated along with kernel?
-
@r1 yes, ever line "installed" in yum.log is an Upgrade from XCP-ng.
Problems started with XCP-ng 8.x -
@borzel did you "yum upgrade" from 7.x from 8.x?
-
@stormi on server xen19 I think so, on server xen22 I'm not sure
I looked more close on my memory graphs and saw, that the memory baseline increases every night:
"bump" every day:
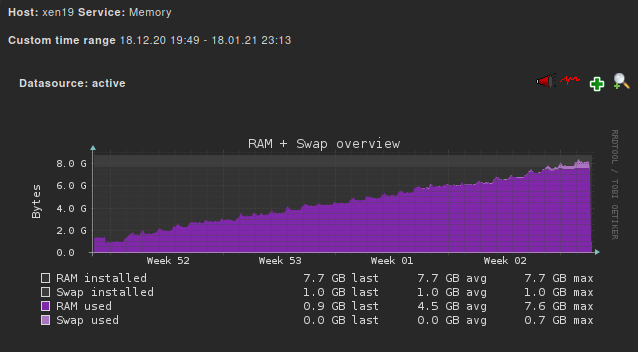
closer look in week 53:
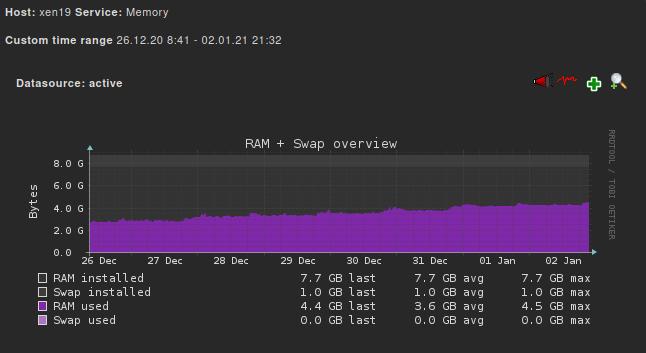
Dez 31. - Jan 01.
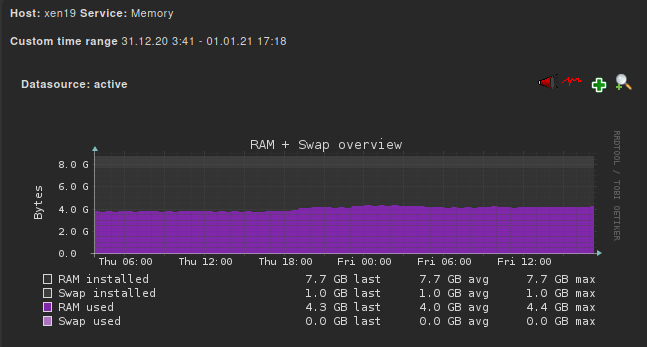
Our Backups run from 18.00 till 3 or 4 in the morning (including coalesce).
--> maybe the heavy IO load leads to memory leaks "somewhere"?
-
Good news from the kernel-alt (server xen19): No RAM leaks so far
")
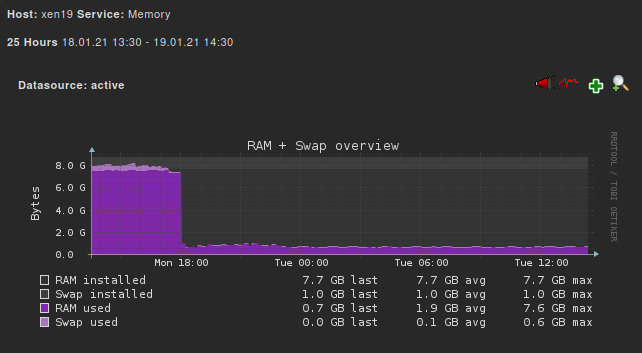
-
At least that's consistent
Thanks for the feedback @borzel -
@borzel
yum upgradefrom 7.x to 8.x is not supported, so it's likely that your host isn't in a perfectly clean state.This is unrelated to the memory leak, but could cause other kinds of issues. Basically, scripts that should have run during the RPM upgrade to ensure the final state is consistent with what you'd have from an ISO upgrade either don't exist or haven't been tested.
-
@stormi I'm not complete sure if I did the iso upgrade or not...

But it's a good idea to reinstall the poolmaster from scratch...
-
@borzel I wish comparing kernel-alt and base kernel was easy to catch this... I'm sure that the tapdisk IO code is same in kernel and kernel-alt.
Also the 2 patches mentioned earlier are also present in base kernel of xcp-ng 8.2 as well as kernel-alt 4.19.142. They are also present for xcp-ng 8.1 base kernel, however they are not present in xcp-ng 8.1 kernel-alt.
Can you confirm your kernel-alt version?
-
@borzel Also, I somehow need to be able to reproduce the issue at lab. If you can give more details about how do you do backup, may be I can simulate something.
-
@r1 If it helps at all, I have seen this more often on the pool master than in other pool hosts. We are using XO delta backup on 125 VMs in this pool daily. So, the master is busy doing a lot of snapshot coalesce operations (lots of iSCSI storage IO) compared to other hosts. The other host that has hit 95% control domain memory use is also IO heavy (it has some database server VMs).
-
@r1 our complete setup:
[FreeNAS NFS] <----shared-storage----> [Pool of 2 servers (xen22 + xen23)] ----XAPI---> [XO from sources] -----remote----> [FreeNAS NFS]
All [servers] are real hardware servers, no VMs involved.
Same chain of servers for xen19, execpt there are more pool members (and VMs).
-
[02:27 xen19 ~]# uname -a Linux xen19 4.19.142 #1 SMP Tue Nov 3 11:27:36 CET 2020 x86_64 x86_64 x86_64 GNU/Linux[02:30 xen19 ~]# yum list installed | grep kernel kernel.x86_64 4.19.19-7.0.9.1.xcpng8.2 @xcp-ng-updates kernel-alt.x86_64 4.19.142-1.xcpng8.2 @xcp-ng-basememory graph so far:
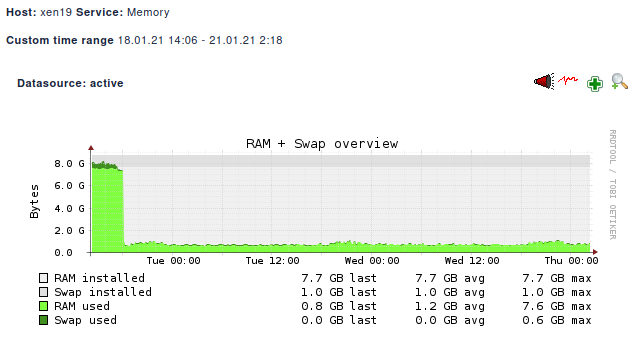
looking very good!!!
-
@borzel Thanks. That rules out the my suspicion on those patches. We are still working on reproducing this issue without success. We would really appreciate if you or someone from community can arrange a test hosts which shows this problem. Reason for test host is because we will have to replace the kernel multiple times to observe change.
Another test users can do is to remove iscsi from equation. Run some workloads on local disks (with backups) and verify control domain memory usage.