Alert: Control Domain Memory Usage
-
So is it better than before?
-
Still checking. Going to run for another day and see.
Should the memory usage in DOM0 be dropping as part of normal use?
I understand ram usage going up and down just like a normal OS, but a constant increase in memory usage doesn't seem right to me or am I misunderstanding how this work?
Gary
-
"Depends". But you shouldn't have invisible RAM used.
-
Sorry I was unclear, but we are not running Kubernetes in our environment. We are running Citrix Hypervisor 8.2 LTSR.
-
I have another observation to throw in the thread here. In working with Citrix support on our dom0 memory exhaustion issue in CH8.2LTSR, they are focusing on several of our VMs that had dynamic memory control enabled, which is deprecated in CH8.x. They believe this is related to the control domain memory exhaustion.
I have disabled this on all VMs that I can find with the feature enabled and will continue to monitor. I don't have much hope that this is the underlying issue, since we are seeing the memory issue on our pool master, which could only have hosted a VM with DMA enabled for very brief periods of time while other VMs were shuffled around for maintenance.
Does this track with anyone else here?
-
This is... Surprising. I thought
xl topwould allow to rule that out very fast (and it did earlier in this thread when I suspected something related to dom0 memory ballooning). Unless Xen leaks the memory in some way that would not be visible to itself. I don't know if that is even possible and I don't see how that would relate at all with the memory used by dom0, even if there was such a leak related to domU DMC. -
I am also suspicious of this diagnosis, and I think this is likely related to checking off the "misalignments" in our configuration before escalating the case to the next level of troubleshooting support. That said, I figured I'd run it by the group here to see if there's any correlation between users with dynamic memory on their VMs and this issue.
-
The boxes that I have do not have dynamic memory (never used it), and we are getting the issue.
Some feedback on my test box running 8.0 alternative kernel. Been running it for a week and getting this.
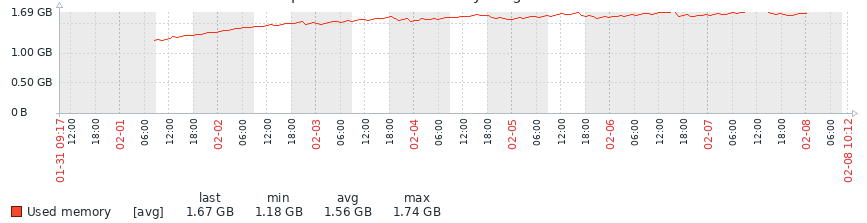
As you can see there was a increase in memory of the first few days, but then it seemed to level off. I'll continue to do some tests, then I'm intending to upgrade to 8.2 and see if I can replicate (both with the standard and alternative kernels).
I'll provide feedback once I have it.
Gary
-
I have another production box that has this issue.. and noticed this
[10:41 host ~]# free -m total used free shared buff/cache available Mem: 7913 6445 77 210 1390 284 Swap: 1023 41 982 [10:41 host ~]# ps -ef | grep sadc | wc -l 6337 [10:41 host ~]# ps -ef | grep CROND | wc -l 6337 [10:41 host ~]# ps -ef | grep 32766 root 306 32766 0 Jan31 ? 00:00:00 /usr/lib64/sa/sadc -F -L -S DISK 1 1 - root 32766 2898 0 Jan31 ? 00:00:00 /usr/sbin/CROND -nNot sure why I have 6337 processes for CROND and sadc, but going to do some investigations
-
[10:36 xs03 ~]# free -m total used free shared buff/cache available Mem: 11921 11322 171 151 427 175 Swap: 1023 37 986 [10:36 xs03 ~]# ps -ef | grep CROND | wc -l 1BTW: All my affected pools never had dynamic memory.
-
@garyabrahams I think this is a separate issue that would deserve a separate thread, though it's interesting to have mentioned it here just in case someone else would have noticed something similar (I don't remember anyone mentioning such proliferation of processes in this thread).
Now, maybe that host also is affected by the memory leak, but for now nothing allows to think both issues are related. Or maybe the lack of free memory is what caused the processes to never quit.
-
Update: we have disabled dynamic memory on all VMs in our pool and the issue is still occurring.I expect this to be sent to the citrix developers shortly, since the normal support team has exhausted their troubleshooting options.
-
An update from my side.
I have tried 8.0 alt kernel, 8.2 standard kernel and 8.2 alt kernel and in each case the memory usage increased over timeBelow the first increase is 8.0 alt kernel, 2nd increase was 8.2 standard and 3rd 8.2 alt kernel.
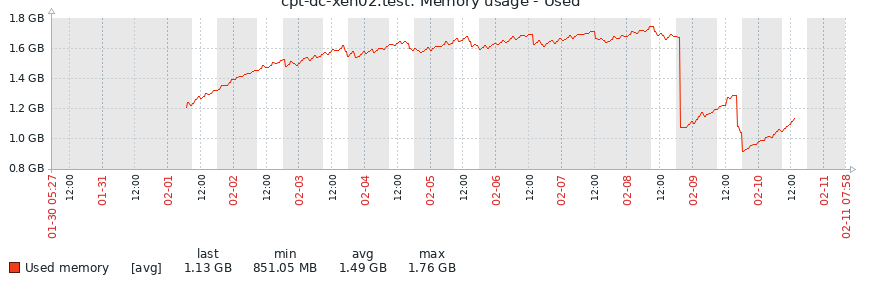
-
I don't think there's enough time to really be sure about the memory leak. It's normal to see raising RAM usage, what's not is to consume all the dom0. Can you wait a bit longer between 2 tests?
-
Hello,
I can confirm we encountered this issue on several hosts in the past few months.Config :
- Server is Dell PowerEdge M630
- local storage on SSD + remote SR on ISCSI
- kernel used: kernel-4.19.19-6.0.11.1.xcpng8.1.x86_64
- we use ixgbe (intel-ixgbe-5.5.2-2.xcpng8.1.x86_64) and network cards are Intel 82599 10 Gigabit dual Port (with bonding on XCP NG).
- firmwares up to date (less than 6 months, when we updated to XCP-NG 8.1+).
Additional informations :
- we don't have any VM with memory ballooning
- shutting down VMs does not free memory
- we don't do many operations each day (less than 5 reboots/stop/start).
- size of pools does not matter (bug happened with two hosts and on another pool with 10 hosts).
According to some messages, it seems kernel-alt fixes the issue ... We'll try to switch kernel when we encounter the issue again.
-
Yes, please, keep us posted
")
Thank for your feedback!
-
One more observation here. This issue does not occur on a different pool of ours that's also running CH8.2LTSR. That pool has lower loading overall, 2 hosts instead of 7, and does not contain any NICs using the ixgbe driver. Other aspects of the pool are identical.
-
@stormi said in Alert: Control Domain Memory Usage:
Before I realized that not every affected host was using the
ixgbedriver, contrarily to what I initially thought, I built an alternate driver from the latest sources from Intel.So, even if there's little hope that it will fix anything, here's how to install it (on XCP-ng 8.1 or 8.2):
yum install intel-ixgbe-alt --enablerepo=xcp-ng-testing rebootHas anyone tested the updated ixgbe driver?
-
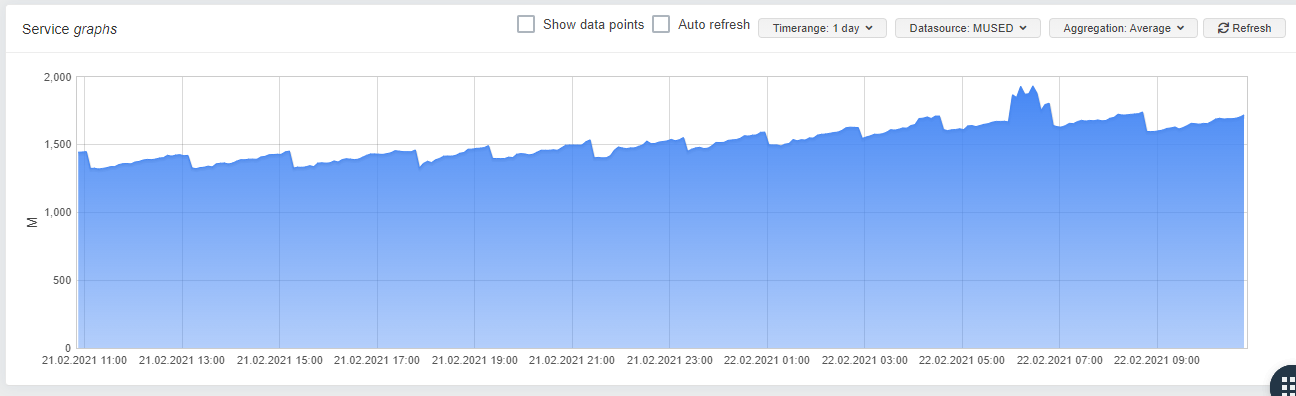
I upgraded a pool which was affected from 8.1 to 8.2 this weekend and installed the driver on one of the Hosts. Its a little early, but as you can see, there seems to be a difference in the memory usage:
Stock Driver
Stromis Driver:
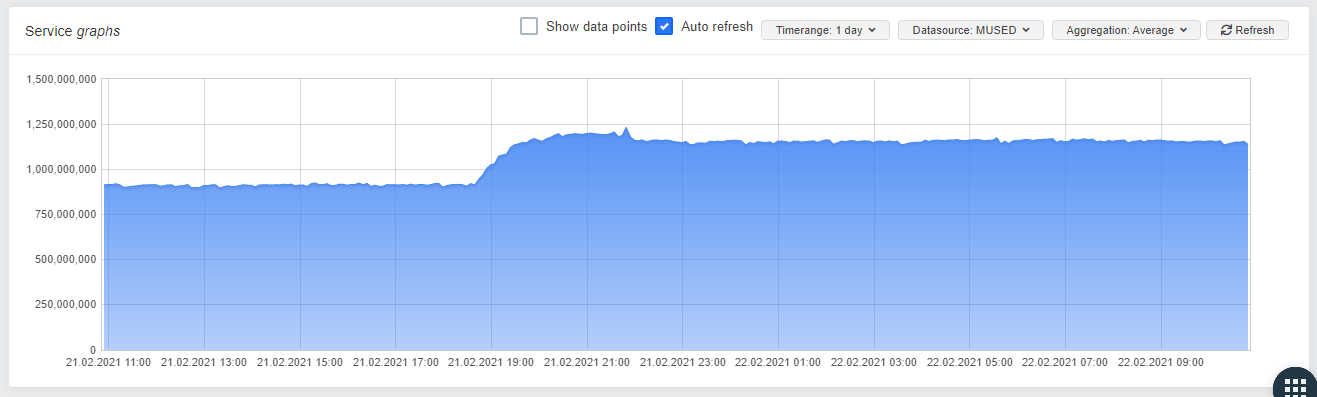
One can allready see a constanty, slowly growing mem-usage in "small steps" on the Server with the stock driver, wheras the server with stormis driver seems to be stable.
-
Indeed, sounds better in any case! Thanks a lot @dave for the feedback.
For everyone else with the issue: please try the same and report. Maybe we found the culprit!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login