Backup to S3 aborted what permissions are required?
-
The same VM backed up to NFS was 30 GB, so not that large?
The transfer to S3 was aborted in just 60 seconds or so, I also retried it a couple of times with the same result.
As it was so quick I would assume there was some kind of configuration issue.
Is there any way I can get a detailed log from the S3 transfer?
Kind regards
Jens -
In
xo-serverlogs. -
@olivierlambert I have not checked the logs at /var/log/syslog. Even though I have the backup running at 01:00 according to the scheduler, nothing happens in the logs at this time. Total silence. Nothing happens even near 01:00.
I see a huge amount of these in the log but I assume it is not related:
May 24 02:29:20 xoce xo-server[1730356]: 2021-05-24T02:29:20.055Z xo:main WARN WebSocket send: { May 24 02:29:20 xoce xo-server[1730356]: error: Error [ERR_STREAM_DESTROYED]: Cannot call write after a stream was destroyed May 24 02:29:20 xoce xo-server[1730356]: at afterWrite (internal/streams/writable.js:470:24) May 24 02:29:20 xoce xo-server[1730356]: at onwrite (internal/streams/writable.js:446:7) May 24 02:29:20 xoce xo-server[1730356]: at WriteWrap.onWriteComplete [as oncomplete] (internal/stream_base_commons.js:89:12) May 24 02:29:20 xoce xo-server[1730356]: at WriteWrap.callbackTrampoline (internal/async_hooks.js:131:14) { May 24 02:29:20 xoce xo-server[1730356]: code: 'ERR_STREAM_DESTROYED' May 24 02:29:20 xoce xo-server[1730356]: } May 24 02:29:20 xoce xo-server[1730356]: } May 24 02:29:20 xoce xo-server[1730356]: 2021-05-24T02:29:20.058Z xo:main WARN WebSocket send: { May 24 02:29:20 xoce xo-server[1730356]: error: Error [ERR_STREAM_DESTROYED]: Cannot call write after a stream was destroyed May 24 02:29:20 xoce xo-server[1730356]: at afterWrite (internal/streams/writable.js:470:24) May 24 02:29:20 xoce xo-server[1730356]: at onwrite (internal/streams/writable.js:446:7) May 24 02:29:20 xoce xo-server[1730356]: at WriteWrap.onWriteComplete [as oncomplete] (internal/stream_base_commons.js:89:12) May 24 02:29:20 xoce xo-server[1730356]: at WriteWrap.callbackTrampoline (internal/async_hooks.js:131:14) { May 24 02:29:20 xoce xo-server[1730356]: code: 'ERR_STREAM_DESTROYED' May 24 02:29:20 xoce xo-server[1730356]: } May 24 02:29:20 xoce xo-server[1730356]: } -
-
@olivierlambert no I have never encountered this error, but the "websocket" keyword make me suspect it's a UI error between XO and the browser,
-
@nraynaud Could be. I am running Safari and I guess it is not the most common. And in that case I guess this log lines are not at all related to my S3 issues.
But the strange thing is that I did not find anything in the logs that referred to s3. Anyone can give me an example of S3 logging so that I know what to look for in the logs?
-
@olivierlambert is there any other logs somewhere? Or could it simply be that I gave the account too low permissions?
Where is the code related to s3 located? Maybe I could read it and understand where it goes wrong. -
I don't know but @nraynaud can answer
")
-
@jensolsson-se hello, sorry the notification slipped through the cracks.
the current fashion in S3 bugs at the moment is in the backups, and the stacktrace clearly shows our code:
"stack": "Error: Error calling AWS.S3.upload: write ECONNRESET\n at rethrow (/home/xoa/xen-orchestra/node_modules/@sullux/aws-sdk/index.js:254:24)\n at runMicrotasks (<anonymous>)\n at processTicksAndRejections (internal/process/task_queues.js:95:5)\n at async S3Handler._outputStream (/home/xoa/xen-orchestra/@xen-orchestra/fs/dist/s3.js:100:5)\n at async S3Handler.outputStream (/home/xoa/xen-orchestra/@xen-orchestra/fs/dist/abstract.js:250:5)\n at async RemoteAdapter.outputStream (/home/xoa/xen-orchestra/@xen-orchestra/backups/RemoteAdapter.js:509:5)\n at async /home/xoa/xen-orchestra/@xen-orchestra/backups/writers/FullBackupWriter.js:69:7"I am extremely puzzled by the stacktrace you posted, the "websocket" keyword almost suggest that the server tried to answer to the browser, but the TCP socket had been closed.
what do you have in the backup log ?
This circled button copies a very long detail of the error to the clipboard, you can paste it in a text editor and have a look.
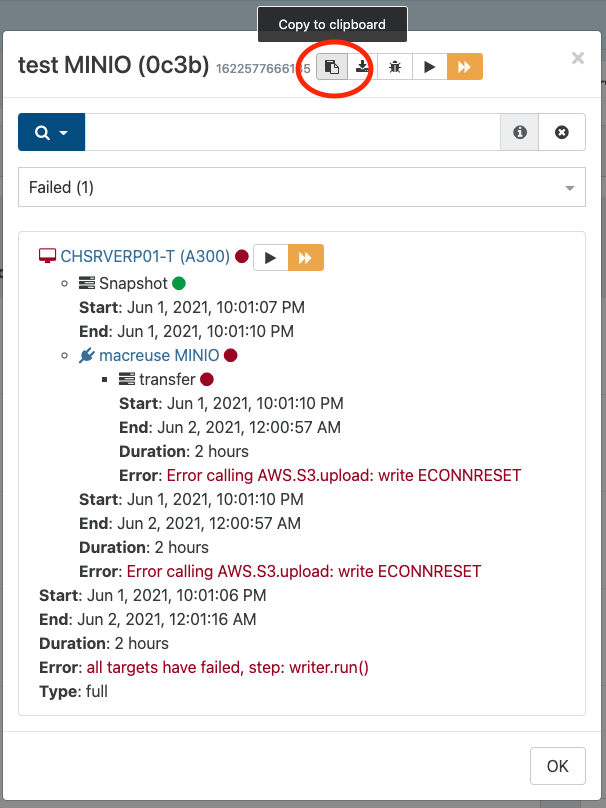
-
Here is how it looks:
{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1622934000014", "jobId": "930a47dd-69f2-4fad-9570-a40a6df5c45d", "jobName": "Backup Seafile to S3", "message": "backup", "scheduleId": "1bae3493-1a16-4806-be3d-ec5f863dfe37", "start": 1622934000014, "status": "interrupted", "tasks": [ { "data": { "type": "VM", "id": "3659ce78-d278-7cad-4967-e565bfaa7064" }, "id": "1622934000054", "message": "Starting backup of Seafile. (930a47dd-69f2-4fad-9570-a40a6df5c45d)", "start": 1622934000054, "status": "interrupted", "tasks": [ { "id": "1622934000255", "message": "snapshot", "start": 1622934000255, "status": "success", "end": 1622934001160, "result": "96d64bf4-60a7-d539-c082-02307a0845e9" }, { "id": "1622934001174", "message": "add metadata to snapshot", "start": 1622934001174, "status": "success", "end": 1622934001180 }, { "id": "1622934001972", "message": "waiting for uptodate snapshot record", "start": 1622934001972, "status": "success", "end": 1622934002177 }, { "id": "1622934002324", "message": "start snapshot export", "start": 1622934002324, "status": "success", "end": 1622934002324 }, { "data": { "id": "16d0ab1e-b32a-48fa-8774-3f9cd4ad35c7", "isFull": true, "type": "remote" }, "id": "1622934002325", "message": "export", "start": 1622934002325, "status": "interrupted", "tasks": [ { "id": "1622934002352", "message": "transfer", "start": 1622934002352, "status": "interrupted" } ] } ] } ] }I am thinking it could be a permission problem maybe. This is the permissions I have given the AWS user:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:ListBucketMultipartUploads", "s3:DeleteObjectVersion", "s3:ListBucketVersions", "s3:ListBucket", "s3:DeleteObject", "s3:ListMultipartUploadParts" ], "Resource": [ "arn:aws:s3:::<bucket hidden>", "arn:aws:s3:::<bucket hidden>/*" ] }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "s3:ListStorageLensConfigurations", "s3:ListAllMyBuckets", "s3:ListJobs" ], "Resource": "*" } ] }Also if I press "test your remote" it sais
Test passed for S3
The remote appears to work correctly -
@jensolsson-se that is weird, there is no real error in the logs you posted, and the testing function actually writes on the S3 bucket, so I really think a lot of things went right.
I am trying to think of a bug that would have gone around the error reporting system. The websocket message is a bit suspicious.
-
@nraynaud Is there anything I can try to narrow down the problem?
-
@nraynaud What does isFull: true mean? Could this be the issue?
Did my permissions look correct?
Also wonder if there are any other logs anywhere I could find, or if there is something maybe I could try from the console to narrow down the problem?
Kind regards
Jens -
-
isFull: truemeans that it's a full copy (because there were no previous valid delta chain).The issue is not related to this or to permissions, it appears that S3 protocol has constraints not really compatible with our use case (more info), we are investigating but it does not look great so far.
-
@julien-f Ah of course, If I would have thought about that isFull line a few minutes I would probably figure that out
Regarding S3 I think it sounds a bit strange. I read the linked article, but for what I understand there should not be a problem uploading a multipart object to S3 not knowing the total filesize. https://docs.aws.amazon.com/AmazonS3/latest/userguide/mpuoverview.html
Do you really need to sign the url? I think the credentials can be used to upload without signing the URL. Or is this used so that the xcp-ng servers are actually transferring directly to S3 ? I also found this article which implies that every part of the multipart upload could be signed individually if signed urls are preferred:
https://www.altostra.com/blog/multipart-uploads-with-s3-presigned-urlDon't know what API you are using with S3, but using the command line, if the source is a stream one could do something like
<command streaming to stdout> | aws s3 cp - s3://bucket/...I know that S3 needs an expected size of the upload. This is to calculate the number of parts so that it does not reach the limit of 5GB per part or too many parts, but setting the expected upload size to 5TB would probably work.
https://loige.co/aws-command-line-s3-content-from-stdin-or-to-stdout/Does this makes sense or did I fully misunderstood the problem?
Kind regards
Jens -
@jensolsson-se Hi Jens, you are on the right track. The other thing is that 5TB/10000 leads to big fragment size that are a bit much to keep in memory.
-
@nraynaud So memory requirements are ~500 MB and that is too much?
Is there a requirement that there need to be one single file in the destination or would it be possible to set the fragment size to 100 MB and if the file will be over 1 TB just create a new file? .0 .1 .2 .3 and so on ?
Maybe I am now braking some convention here but I guess it should work in a good way?
Also read that it is possible to copy objects into parts
https://aws.amazon.com/blogs/developer/efficient-amazon-s3-object-concatenation-using-the-aws-sdk-for-ruby/I am thinking if this would make it possible to make a multipart upload of 10 MB parts into one big 100 GB file
Then take 50 x 100 GB files and combine them into one big 5 TB file and as I understand it this can be done 100% within S3. No upload/download
Kind regards
Jens -
@jensolsson-se yes, we have though of complicated solutions too, but we haven't yet really dug into it, because this is a backup situation, we'd like the state of things and failure modes to be manageable.
-
@nraynaud Makes sense to keep it simple.
But this means that S3 backup in XO is currently broken, right, and I need to find some other way to back up my VMs for now.