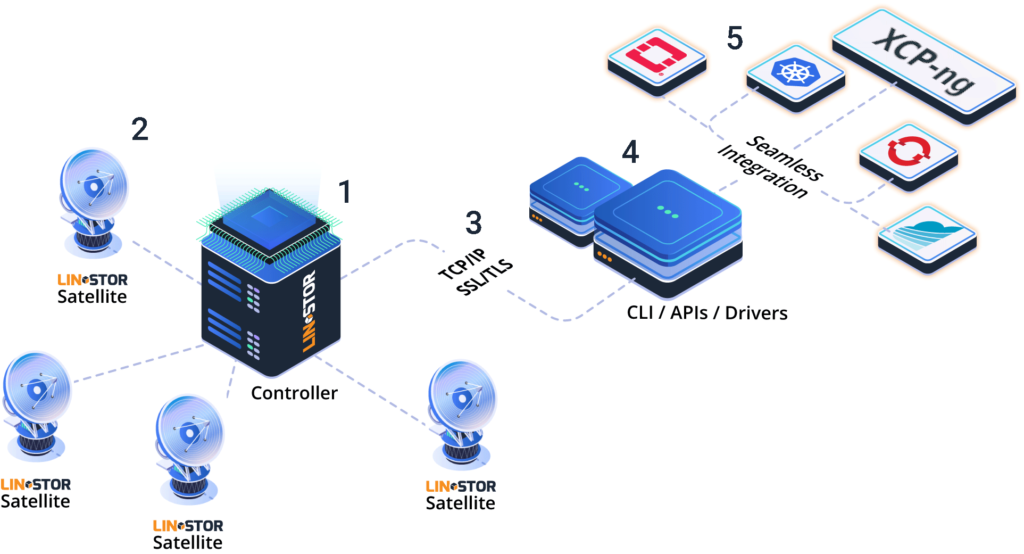
-
@Maelstrom96 said in XOSTOR hyperconvergence preview:
After reviewing the code, it seems like there's a critical file /etc/xensource/xhad.conf that is not created when setting up HA and LinstorSR.py expects it. Hopefully that information can help
Not exactly the problem. I fixed the issue but not released yet.
You can edit/opt/xensource/sm/LinstorSR.pyand replaceget_host_addressfunction definition on each host:def get_host_addresses(session): addresses = [] hosts = session.xenapi.host.get_all_records() # Instead of: # for record in hosts: # use the new line below: for record in hosts.itervalues(): addresses.append(record['address']) return addressesMust be fixed after that.
") I think I will release a new RPM in ~1-2 weeks.
I think I will release a new RPM in ~1-2 weeks. -
Hi,
I restarted one of my vms but I couldint get it up due to this error.
SR_BACKEND_FAILURE_46(, The VDI is not available [opterr=Plugin linstor-manager failed], )I really dont know why, I tried my best to debug it but I dont know from where to start.
I did a
grep -r {VID-UUID} /var/log, hopefully there is something here we can debug.Note it was working normally before August 1 3pm in the logs, I cant migrate the data from this XOSTOR to local SR due to another error but I have a backup of the vms.
I'm on the latest version of the xostor;
./xostor --update-onlysays im on the latest version.Thank you
-
I exported a snapshot for the vm so the data is safe. It is just now I'm worried about restarting other nodes on the cluster.
I'm happy to debug it I just need some gudiance as I havent done anything special to the VM since it is creation, so not sure why the VDI error appeared.
-
@ronan-a In my latest test I created a new VM with multiple disks on XOSTOR. This worked OK and I was able to run and access all the disks.
However I then tried to remove this VM. After a long period of nothing happening (other than the spinning icon on the remove button) I get a "operation timed out" error and the VM is now shown as paused again.
vm.delete { "id": "90613dbb-bd40-8082-c227-a318cbdbd01d" } { "call": { "method": "VM.hard_shutdown", "params": [ "OpaqueRef:8aa8abb0-d204-43fd-897f-04425b790e68" ] }, "message": "operation timed out", "name": "TimeoutError", "stack": "TimeoutError: operation timed out at Promise.call (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/timeout.js:11:16) at Xapi.apply (/opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/index.js:693:37) at Xapi._call (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/limit-concurrency-decorator/src/index.js:85:24) at /opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/index.js:771:21 at loopResolver (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:83:46) at Promise._execute (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/debuggability.js:384:9) at Promise._resolveFromExecutor (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:518:18) at new Promise (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:103:10) at loop (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:85:22) at retry (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:87:10) at Xapi._sessionCall (/opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/index.js:762:20) at Xapi.call (/opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/index.js:273:14) at loopResolver (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:83:46) at Promise._execute (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/debuggability.js:384:9) at Promise._resolveFromExecutor (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:518:18) at new Promise (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:103:10) at loop (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:85:22) at Xapi.retry (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:87:10) at Xapi.call (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/promise-toolbox/retry.js:103:18) at Xapi.destroy (/opt/xo/xo-builds/xen-orchestra-202206111352/@xen-orchestra/xapi/vm.js:361:18) at Api.callApiMethod (file:///opt/xo/xo-builds/xen-orchestra-202206111352/packages/xo-server/src/xo-mixins/api.mjs:310:20)" }If I try to delete again, the same thing happens.
All the volumes used by this VM still exist on linstor and linstor shows no errors.
Now when I try to create any new VM, this now also fails with the following error:
vm.create { "clone": true, "existingDisks": {}, "installation": { "method": "cdrom", "repository": "16ead07f-2f23-438f-9010-6f1e6c847e2c" }, "name_label": "testx", "template": "d276dc0c-3870-2b7e-64c2-b612bb856227-2cf37285-57bc-4633-a24f-0c6c825dda66", "VDIs": [ { "bootable": true, "device": "0", "size": 23622320128, "type": "system", "SR": "141d63f6-d3ed-4a2f-588a-1835f0cea588", "name_description": "testx_vdi", "name_label": "testx_xostor_vdi" } ], "VIFs": [ { "network": "965db545-28a2-5daf-1c90-0ae9a7882bc1", "allowedIpv4Addresses": [], "allowedIpv6Addresses": [] } ], "CPUs": "4", "cpusMax": 4, "cpuWeight": null, "cpuCap": null, "name_description": "testx", "memory": 4294967296, "bootAfterCreate": true, "copyHostBiosStrings": false, "secureBoot": false, "share": false, "coreOs": false, "tags": [], "hvmBootFirmware": "bios" } { "code": "SR_BACKEND_FAILURE_78", "params": [ "", "VDI Creation failed [opterr=error Invalid path, current=/dev/drbd1031, expected=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0 (realpath=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0)]", "" ], "call": { "method": "VDI.create", "params": [ { "name_description": "testx_vdi", "name_label": "testx_xostor_vdi", "other_config": {}, "read_only": false, "sharable": false, "SR": "OpaqueRef:7709e595-7889-4cf1-8980-c04bd145d296", "type": "user", "virtual_size": 23622320128 } ] }, "message": "SR_BACKEND_FAILURE_78(, VDI Creation failed [opterr=error Invalid path, current=/dev/drbd1031, expected=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0 (realpath=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0)], )", "name": "XapiError", "stack": "XapiError: SR_BACKEND_FAILURE_78(, VDI Creation failed [opterr=error Invalid path, current=/dev/drbd1031, expected=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0 (realpath=/dev/drbd/by-res/xcp-volume-cc55faf8-84a0-431c-a2dc-a618d70e2c49/0)], ) at Function.wrap (/opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/_XapiError.js:16:12) at /opt/xo/xo-builds/xen-orchestra-202206111352/packages/xen-api/src/transports/json-rpc.js:37:27 at AsyncResource.runInAsyncScope (async_hooks.js:197:9) at cb (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/util.js:355:42) at tryCatcher (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/util.js:16:23) at Promise._settlePromiseFromHandler (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:547:31) at Promise._settlePromise (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:604:18) at Promise._settlePromise0 (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:649:10) at Promise._settlePromises (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/promise.js:729:18) at _drainQueueStep (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/async.js:93:12) at _drainQueue (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/async.js:86:9) at Async._drainQueues (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/async.js:102:5) at Immediate.Async.drainQueues [as _onImmediate] (/opt/xo/xo-builds/xen-orchestra-202206111352/node_modules/bluebird/js/release/async.js:15:14) at processImmediate (internal/timers.js:464:21) at process.callbackTrampoline (internal/async_hooks.js:130:17)" }Note
/dev/drbd1031does not exist in/dev/drdbor as a volume.How do I remove the test VM? How to fix the issue with creating new VMs?
-
I have been attempting to use xostore with k8s linstor csi for storage class
on the host on port 3370, it returns the following via via http
API Documentation
As LINBIT SDS subscriber you can install the UI by running apt install linstor-gui or dnf install linstor-gui.Using this guide https://linbit.com/blog/linstor-csi-plugin-for-kubernetes/
This is what it is outputting. The port is accessible with telnet from inside the k8s cluster.I0802 17:56:53.196698 1 csi-provisioner.go:121] Version: v2.0.2-0-g0c6347dbf I0802 17:56:53.196816 1 csi-provisioner.go:135] Building kube configs for running in cluster... I0802 17:56:53.221618 1 connection.go:153] Connecting to unix://10.2.0.19:3370 W0802 17:57:03.221861 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:57:13.221702 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:57:23.221915 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:57:33.221860 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:57:43.221871 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:57:53.221866 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:58:03.221822 1 connection.go:172] Still connecting to unix://10.2.0.19:3370 W0802 17:58:13.221863 1 connection.go:172] Still connecting to unix://10.2.0.19:3370Thoughts?
-
Ah, I had the configuration wrong.
What I am currently debugging is
I0802 20:13:51.419681 1 node_register.go:55] Starting Registration Server at: /registration/linstor.csi.linbit.com-reg.sock
I0802 20:13:51.419859 1 node_register.go:64] Registration Server started at: /registration/linstor.csi.linbit.com-reg.sock
I0802 20:13:51.419991 1 node_register.go:86] Skipping healthz server because port set to: 0
I0802 20:13:52.764092 1 main.go:79] Received GetInfo call: &InfoRequest{}
I0802 20:13:52.787102 1 main.go:89] Received NotifyRegistrationStatus call: &RegistrationStatus{PluginRegistered:false,Error:RegisterPlugin error -- plugin registration failed with err: rpc error: code = Unknown desc = failed to retrieve node topology: failed to get storage pools for node: 404 Not Found,}
E0802 20:13:52.787170 1 main.go:91] Registration process failed with error: RegisterPlugin error -- plugin registration failed with err: rpc error: code = Unknown desc = failed to retrieve node topology: failed to get storage pools for node: 404 Not Found, restarting registration container. -
@ronan-a is off this week, but he'll come back next week!
-
@olivierlambert
Not a problem! I am 99% it is an issue with the CSI.I am making progress, the CSI is trying to use k8s nodename, and has no idea what the hostname which is running the VM.
-
OK I figured it out! I made an init container that gets a manually created node label for the node the pod is running on. This value is the bare metal host for that k8s node. The init contianer then takes that value and makes a script wrapper and then calls linstor-csi with the correct values. After making these changes all the linstor csi containers are running with no errors.
Current problem comes from deploying and using storage class. Started with a basic one that failed, and noticed I did not know what the correct
storage_pool_namename was, so went to http://IP:3370/v1/nodes/NODE/storage-pools and http://IP:3370/v1/nodes/NODE to get information.Still troubleshooting, but wanted to provide info.
-
@AudleyElwine It seems a volume is still open but should be removed by the driver. You can check if a process has a fd on it using (on each host!):
cat /sys/kernel/debug/drbd/resources/xcp-volume-38e34dc1-8947-4b3d-af49-fbc5393c7069/volumes/0/openers.Maybe a tapdisk instance or another process. Also can you send me the related SMlog file please?
")
-
@ronan-a said in XOSTOR hyperconvergence preview:
@geoffbland Thank you for your tests.
Could you send me the other logs (/var/log/SMlog + kern.log + drbd-kern.log please)? Also check if the LVM volumes are reachable with linstor resource list. Also, you can check with lvs command on each host. EIO error is not a nice error to observe.So after analysis, I will patch the driver to log using DRBD
openersfile instead oflsofbecause there is probably a process that prevents tapdisk from opening the volume.@geoffbland said in XOSTOR hyperconvergence preview:
Note /dev/drbd1031 does not exist in /dev/drdb or as a volume.
Regarding this specific issue if you have this resource in the LINSTOR DB, it's really weird.
 So can you upload the logs please? (SMlog + linstor files).
So can you upload the logs please? (SMlog + linstor files).How do I remove the test VM? How to fix the issue with creating new VMs?
You can forget the VDI to remove the VM. If you can't remove properly it, you can use
drbdsetup(detach/del-minor) to force destroy the DRBD volume.
Do you always have this issue when you create new VMs? -
@ronan-a said in XOSTOR hyperconvergence preview:
You can forget the VDI to remove the VM
I couldn't forget it as the VM needs to be started to forget it and the VM is stuck in a "paused" state.
I was eventually able to get the VM in a stopped state by force rebooting all the hosts in the pool. Once the VM was stopped by this I was then able to delete the VM and all XOSTOR disks were then also removed.
Do you always have this issue when you create new VMs?
Yes, I got this error anytime I try to create a new VM on the XOSTOR SR. However after rebooting all the hosts in the pool I am able to recreate VMs again.I will continue with more testing as and when I get time. Currently I have a VM up and running and seemingly healthy yet linstor reports the volume as outdated, what would cause this and how do I fix it?
┊ XCPNG30 ┊ xcp-volume-9163fab8-a449-439d-a599-05b8b2fa27bf ┊ DfltDisklessStorPool ┊ 0 ┊ 1002 ┊ /dev/drbd1002 ┊ ┊ InUse ┊ Diskless ┊ ┊ XCPNG31 ┊ xcp-volume-9163fab8-a449-439d-a599-05b8b2fa27bf ┊ xcp-sr-linstor_group ┊ 0 ┊ 1002 ┊ /dev/drbd1002 ┊ 20.05 GiB ┊ Unused ┊ UpToDate ┊ ┊ XCPNG32 ┊ xcp-volume-9163fab8-a449-439d-a599-05b8b2fa27bf ┊ xcp-sr-linstor_group ┊ 0 ┊ 1002 ┊ /dev/drbd1002 ┊ 20.05 GiB ┊ Unused ┊ Outdated ┊ ┊ XCPNG30 ┊ COMBINED ┊ 192.168.1.30:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG31 ┊ COMBINED ┊ 192.168.1.31:3366 (PLAIN) ┊ Online ┊ ┊ XCPNG32 ┊ COMBINED ┊ 192.168.1.32:3366 (PLAIN) ┊ Online ┊ -
@geoffbland said in XOSTOR hyperconvergence preview:
I will continue with more testing as and when I get time. Currently I have a VM up and running and seemingly healthy yet linstor reports the volume as outdated, what would cause this and how do I fix it?
The
outdatedflag is removed automatically after a short delay if there is no issue with the network.
See: https://linbit.com/drbd-user-guide/drbd-guide-9_0-en/#s-outdate
Do you still have this flag? -
@ronan-a said in XOSTOR hyperconvergence preview:
The
outdatedflag is removed automatically after a short delay if there is no issue with the network.
See: https://linbit.com/drbd-user-guide/drbd-guide-9_0-en/#s-outdate
Do you still have this flag?Sorry about the long delay in this response - unfortunately I have been busy with work and so not able to spend much time looking at this. But two weeks later after the Outdated volume is still present. As far as I can tell there was no issue with the network.
I wiped the install again and could get DRDB in the same state again by creating a few VMs each with several disks and then deleting the VMs - eventually the issue occurs again.
I have since wiped again and done a fresh XCPNG install - this time with a dedicated network (separate NICs and private switch) for data and I'll see how that goes.
-
@ronan-a My appoiliges for replying late. The issue happened again and remembered this thread.
I triedcat /sys/kernel/debug/drbd/resources/xcp-volume-{UUID}/volumes/0/openersand it is empty across all hosts for both the old broken VDI and the new one.
The hosts are:- eva (master)
- phoebe
- mike (linstor controller)
- ozly
I also have scheduled backups snapshots so not sure if this will affect the vdi removal.
Here is the log SMlog.zip.txt The file is not a.txtit is just a.zip(the forum doesnt allow.zip).
The file is filled withbad volumeand idk what to do to fix it. -
Just got this working in my 3 host home setup..... But I'm looking to drop down to two hosts. Is it going to be usable with 2 hosts (I've seen the recommendation of 3+ at the top) and if so, what happens when you get down to 1 host whatever reason??? Are read / writes locked on the remaining host?
-
Hi @jmccoy555
No, it's not meat to run on 2 hosts. A good advice is already to use replication 2 on 3 hosts, this way, even with one host down, it will continue to run. LINSTOR/DRBD is locking everything as soon you have a number of hosts inferior to the target replication.
-
@olivierlambert Thanks. I tried to find a definite answer in the Linstor docs but couldn't.
I had set replication = 2 and could see the diskless copies in the volume list.
I then shutdown one host, and then saw the auto eviction after an hour and overnight it has adjusted so each of the two remaining hosts has a complete replica, i.e. there are no more diskless copies. So it looks like a nice easy to deploy solution (if you need the CPU power of 3 hosts rather than just running them for storage, ££££ these days).
I had assumed too that if I shutdown / lost another host then everything would come to a halt, but there does appear to be some info 'out there' about a 2 node set up and avoiding split brain etc. so I was hopeful it may be possible!
So really the only 2 node option is XOSAN which is kind of not an option by the sounds of it after Gluster going EOL and for playing at home needing to pay or manual install which I don't think there's a guide for (not moaning, you guys give a lot). I guess my aim is to have a 2 host set up, which I can reduce to 1 when I don't need to capacity or to allow the installation of updates without getting shouted at..... 'whys the internet not working'
 . At present I'm running Ceph hyperconverged in VMs (for VMs and Kubernetes storage........ I know......) across 3 hosts and in reality often run with 2. Yeah I know that if one goes down everything stops, but if I plan to, I just start the third, let it sync and sort itself out and everything is good to do whatever I want. Likewise if something does go wrong, starting the 3rd hosts often gets things moving again whilst I work it out. I really think that I should have lost some data by now by doing something silly, but so far (a few years now) it just sorts it all out. I also rsync everything to TrueNAS every hour and regularly backup the VMs just in case.
. At present I'm running Ceph hyperconverged in VMs (for VMs and Kubernetes storage........ I know......) across 3 hosts and in reality often run with 2. Yeah I know that if one goes down everything stops, but if I plan to, I just start the third, let it sync and sort itself out and everything is good to do whatever I want. Likewise if something does go wrong, starting the 3rd hosts often gets things moving again whilst I work it out. I really think that I should have lost some data by now by doing something silly, but so far (a few years now) it just sorts it all out. I also rsync everything to TrueNAS every hour and regularly backup the VMs just in case.I guess I just need to accept that going to two hosts probably means that when moving VMs around their storage needs to go with them, and that TrueNAS (a VM again...... I know, but must be 15+years with no issues) needs to provide the storage for Kubernetes

-
Hey @ronan-a , Now all the VDIs on the device are broken, I tried to migrate them but i get errors such as.
SR_BACKEND_FAILURE_1200(, Cannot update volume uuid 36a23780-2025-4f3f-bade-03c410e63368 to 45537c14-0125-4f6c-a1ad-476552888087: this last one is not empty, )SR_BACKEND_FAILURE_78(, VDI Creation failed [opterr=error Error: Could not set kv(/volume/9cdc83cc-0fd8-490e-a3af-2ca40c95f398/not-exists:2): ERRO:Exception thrown.], )SR_BACKEND_FAILURE_46(, The VDI is not available [opterr=Plugin linstor-manager failed], )I dont care about the broken VDIs content so no worries.
It was fun experimenting with it, but I need more storage and will move the SSDs to my NAS and run my VMs on NFS there instead.
Before I do so I thought you might be interested in debugging the issues and getting my logs if that will help the project. Just let me know what files I need to send and will be happy to do so. -
Hey @AudleyElwine Ronan will take a look next week. It might be a bug we already fixed for our next beta round. He'll tell you