XCP-NG vm's extremly slow
-
One more Info: the problem only occurs on the VM, the base system is working normaly
-
- What kind of storage do you use for your VMs?
- When you do ls, what path do you do ls for?
- What is the output of
mount?
-
- What kind of storage do you use for your VMs?
both machine have 2 raid1 with 2x Seagate Guardian BarraCuda ST4000LM024 and 2x Intel Solid-State Drive D3-S4610 Series- 960GB.
there is no problem on the host, only on the VMs (and problem occurs on VMs on the ssd and on others on the seagate).
-
When you do ls, what path do you do ls for?
It's no problem with the "ls" command, it appears on every command (or even on commands that does not exists).... and on other disk operations. If i repeat the command it get's faster, but still to slow. -
What is the output of mount?
on the host system:
sysfs on /sys type sysfs (rw,nosuid,nodev,noexec,relatime)
proc on /proc type proc (rw,nosuid,nodev,noexec,relatime)
devtmpfs on /dev type devtmpfs (rw,nosuid,size=2091400k,nr_inodes=522850,mode=755)
securityfs on /sys/kernel/security type securityfs (rw,nosuid,nodev,noexec,relatime)
tmpfs on /dev/shm type tmpfs (rw,nosuid,nodev)
devpts on /dev/pts type devpts (rw,nosuid,noexec,relatime,gid=5,mode=620,ptmxmode=000)
tmpfs on /run type tmpfs (rw,nosuid,nodev,mode=755)
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/systemd type cgroup (rw,nosuid,nodev,noexec,relatime,xattr,release_agent=/usr/lib/systemd/systemd-cgroups-agent,name=systemd)
pstore on /sys/fs/pstore type pstore (rw,nosuid,nodev,noexec,relatime)
cgroup on /sys/fs/cgroup/freezer type cgroup (rw,nosuid,nodev,noexec,relatime,freezer)
cgroup on /sys/fs/cgroup/memory type cgroup (rw,nosuid,nodev,noexec,relatime,memory)
cgroup on /sys/fs/cgroup/blkio type cgroup (rw,nosuid,nodev,noexec,relatime,blkio)
cgroup on /sys/fs/cgroup/net_cls,net_prio type cgroup (rw,nosuid,nodev,noexec,relatime,net_cls,net_prio)
cgroup on /sys/fs/cgroup/cpuset type cgroup (rw,nosuid,nodev,noexec,relatime,cpuset)
cgroup on /sys/fs/cgroup/cpu,cpuacct type cgroup (rw,nosuid,nodev,noexec,relatime,cpu,cpuacct)
cgroup on /sys/fs/cgroup/devices type cgroup (rw,nosuid,nodev,noexec,relatime,devices)
configfs on /sys/kernel/config type configfs (rw,relatime)
/dev/md127p1 on / type ext3 (rw,relatime)
mqueue on /dev/mqueue type mqueue (rw,relatime)
debugfs on /sys/kernel/debug type debugfs (rw,relatime)
xenfs on /proc/xen type xenfs (rw,relatime)
xenstore on /var/lib/xenstored type tmpfs (rw,relatime,mode=755)
/dev/md127p5 on /var/log type ext3 (rw,relatime)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw,relatime)
tmpfs on /run/user/0 type tmpfs (rw,nosuid,nodev,relatime,size=420744k,mode=700) -
@Andi79
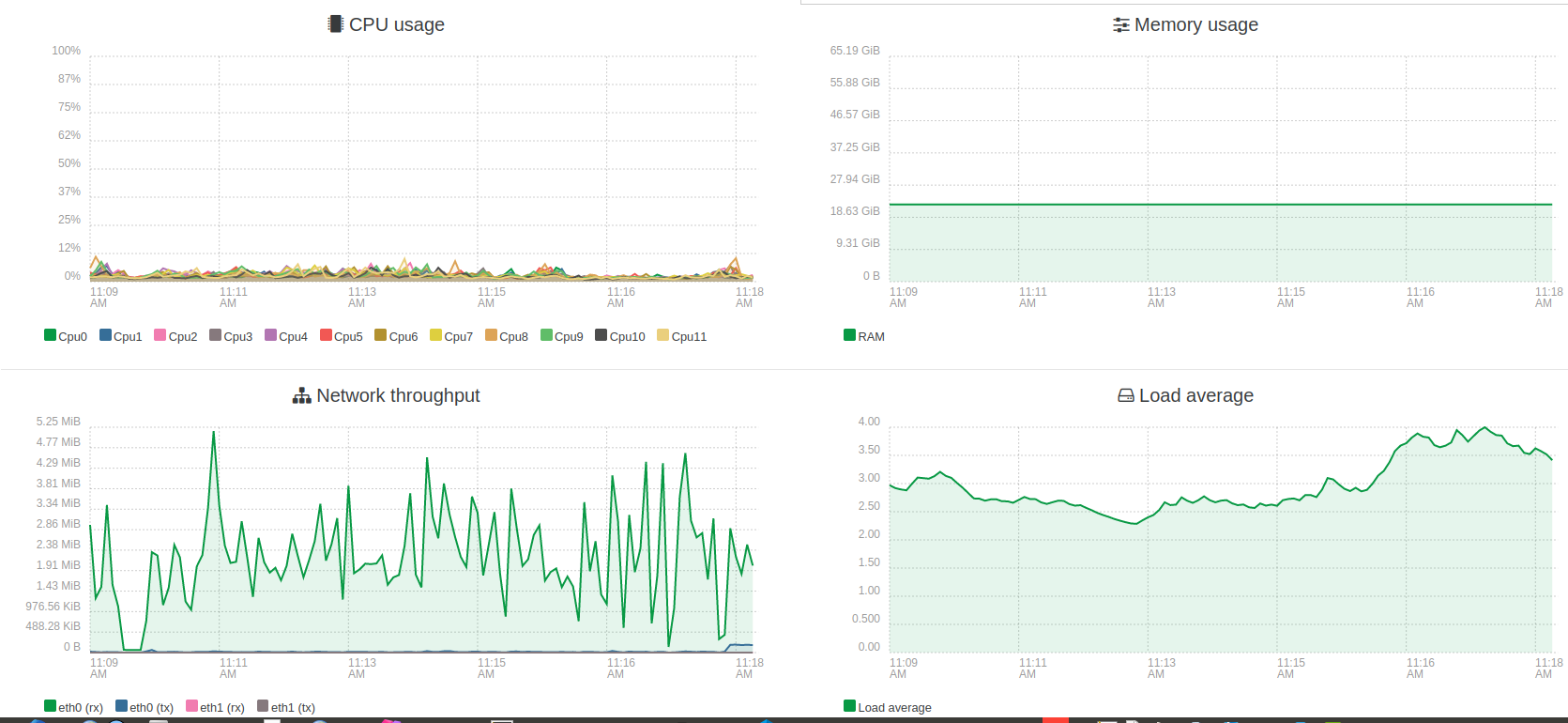
this is the current from the pc that only hosts 2vms. One VM with backuppc that is running (extremly slow backups..... many file accesses from backuppc). CPU usage is verly low. I really suspect an IO problem, but i have no idea how to prove or solve it. -
What SR do you have setup for storing your VMs? Your mount output does not list /dev/mapper/XSLocalEXT-xxxx as would be normal for a local SR or a NFS mount used for share storage. What do you have in /run/sr-mount/ ?
Is this a plain xcp-ng installation or did you build from source?
It is unusual that ls would be slow. It sounds like a networking issue, perhaps DNS timeout or something similar that is affecting things.
-
here is a Video of the problem
as you can see in the beginning everyhing is ok, then it beginns to stop when i make the apt update (no network problem). When I make the ctrl + c on the wget it hangs... also a short time on the rm. but this could also happen on an ls or when I enter a command that does not exists.
it's a plain xcp-ng installation with default values, i only added the second raid by mdadm and attached it as an sr.
-
@Andi79 said in XCP-NG vm's extremly slow:
here is a Video of the problem
https://we.tl/t-A8JF4EAWhtI can't download from there. But in any case. Can you provide the details exactly how things are configured?
-
@Forza i uploaded here again as direct link
"It sounds like a networking issue"
how could network issues cause a problem like a freze after an ls?
"Can you provide the details exactly how things are configured?"
what exactly do you need to know? it's a standard instalation, the ssd is attached during instalation as a raid1 on md127. the hdd is attached after that as md126. The VMs where migrated from some other hosts where they did not made this troubles.
The Host system took 4GB Ram by default. -
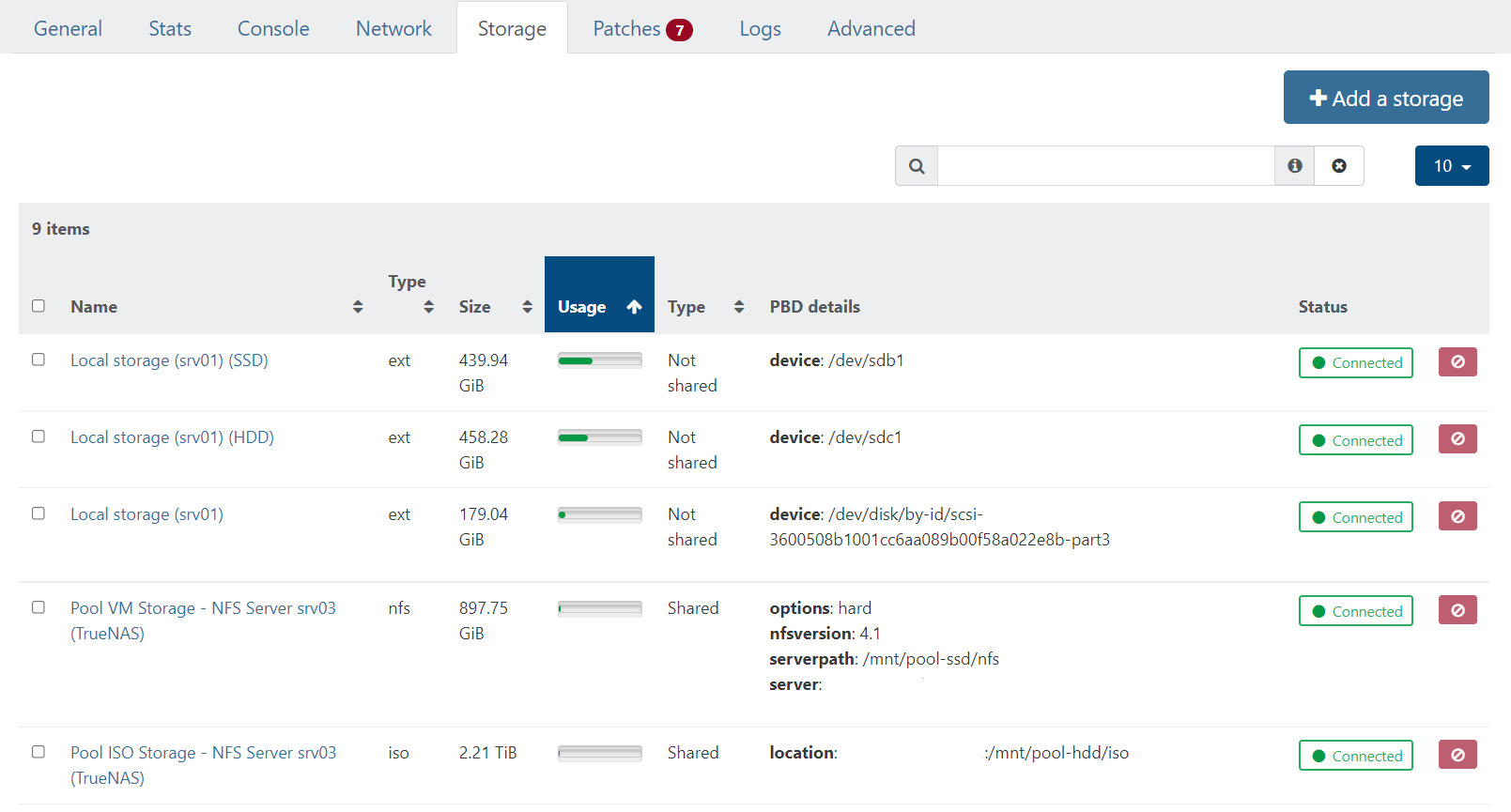
You did not show any SR details. You can see those in XOA->Hosts->(your host->Storage-tab
Example:
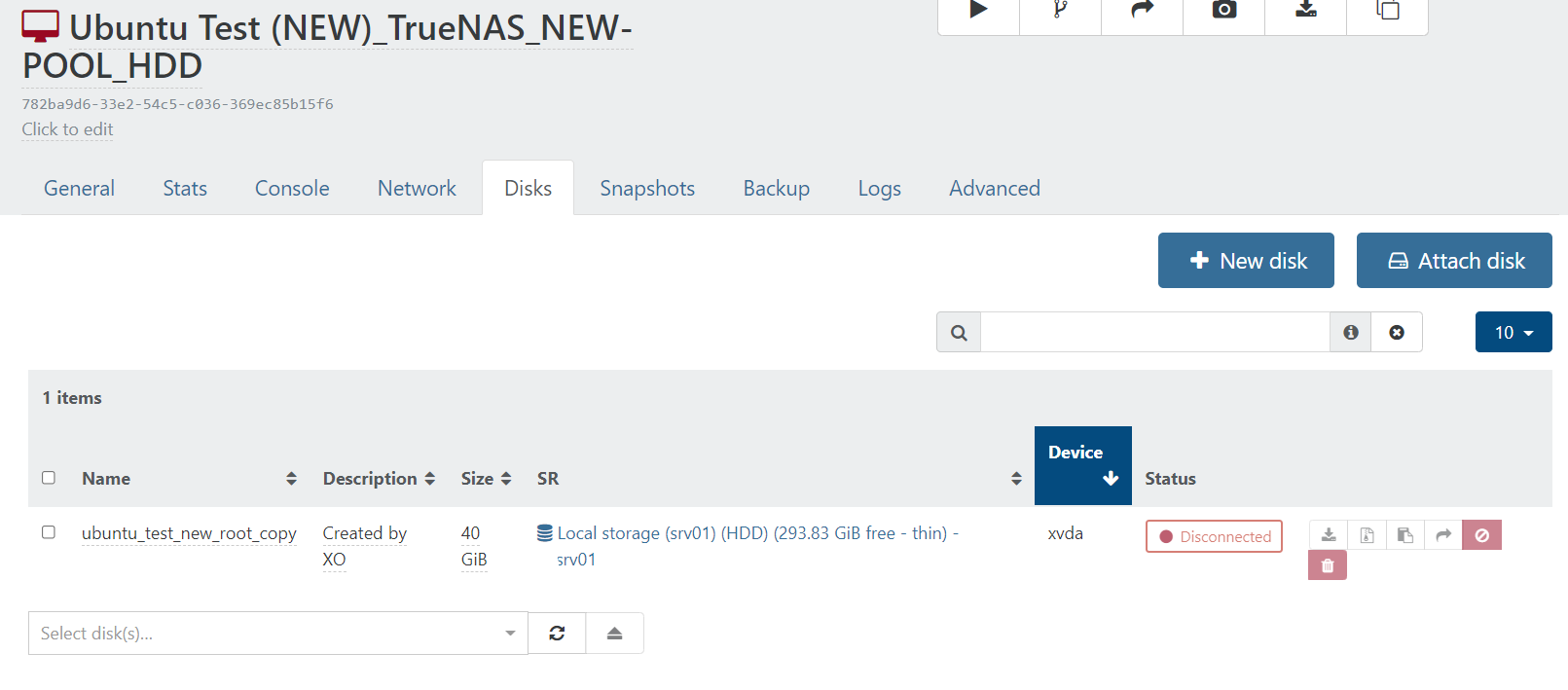
Also. Your VM. What storage does it use?
Example:
-
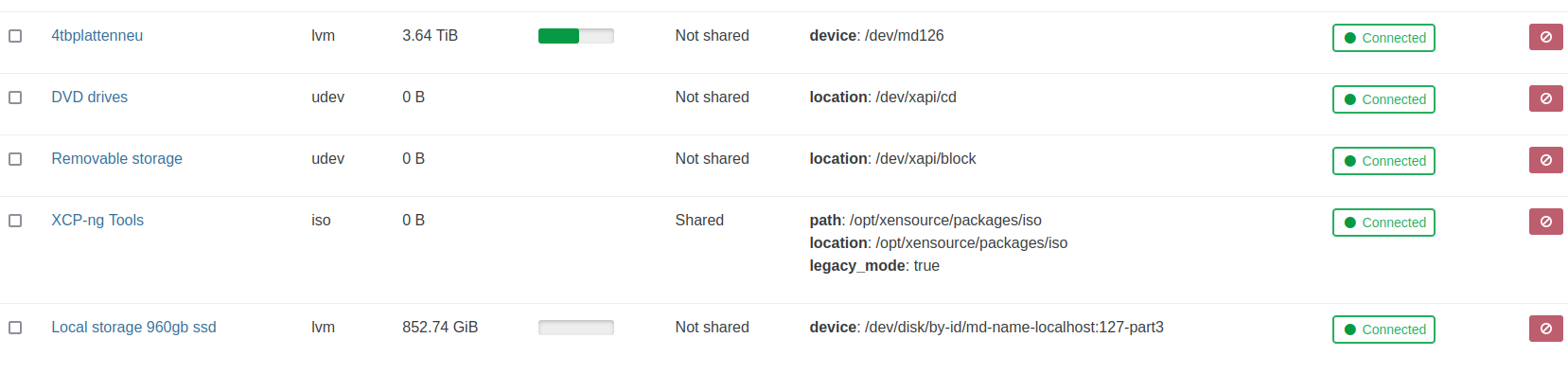
here is the storage list
-
@Andi79
Is the problem occurring both when the vm's are on HDD and on SSD storage or only on HDD ? -
@hoerup on both. I allready thought this could happen on some idle thing on the hdd's, but same problem on the ssd's, so that could not be the cause
-
Can you try ext/thin instead of LVM? Not that this should matter that much.
-
Looking at the video it seems the writes get queued up (Dirty in /proc/meminfo). I wonder why writes are so slow.
What filesystems do you use on the guest?
-
this was the standard from xcp-ng during installation. The problem is that there allready are VMs on this machine and i can't reformat it without any problems (no other hosts in this data center where i could use the same IPs).
guest system uses ext3
-
Some more Infos:
#cat /proc/mdstat Personalities : [raid1] md126 : active raid1 sdb[1] sda[0] 3906886464 blocks super 1.2 [2/2] [UU] bitmap: 3/30 pages [12KB], 65536KB chunk md127 : active raid1 sdd[1] sdc[0] 937692352 blocks super 1.0 [2/2] [UU] bitmap: 1/7 pages [4KB], 65536KB chunk#mdadm --detail /dev/md126 /dev/md126: Version : 1.2 Creation Time : Sat Jun 4 12:08:56 2022 Raid Level : raid1 Array Size : 3906886464 (3725.90 GiB 4000.65 GB) Used Dev Size : 3906886464 (3725.90 GiB 4000.65 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Intent Bitmap : Internal Update Time : Tue Jun 14 19:55:36 2022 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Consistency Policy : bitmap Name : server2-neu:md126 (local to host server2) UUID : 784c25d6:18f3a0c2:ca8fe399:d16ec0e2 Events : 35383 Number Major Minor RaidDevice State 0 8 0 0 active sync /dev/sda 1 8 16 1 active sync /dev/sdb#mdadm --detail /dev/md127 /dev/md127: Version : 1.0 Creation Time : Sat Jun 4 09:56:54 2022 Raid Level : raid1 Array Size : 937692352 (894.25 GiB 960.20 GB) Used Dev Size : 937692352 (894.25 GiB 960.20 GB) Raid Devices : 2 Total Devices : 2 Persistence : Superblock is persistent Intent Bitmap : Internal Update Time : Tue Jun 14 19:56:15 2022 State : clean Active Devices : 2 Working Devices : 2 Failed Devices : 0 Spare Devices : 0 Consistency Policy : bitmap Name : localhost:127 UUID : b5ab10b2:b89109af:9f4a274a:d7af50b3 Events : 4450 Number Major Minor RaidDevice State 0 8 32 0 active sync /dev/sdc 1 8 48 1 active sync /dev/sdd#vgdisplay Device read short 82432 bytes remaining Device read short 65536 bytes remaining --- Volume group --- VG Name VG_XenStorage-cd8f9061-df06-757c-efb6-4ada0927a984 System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 93 VG Access read/write VG Status resizable MAX LV 0 Cur LV 5 Open LV 3 Max PV 0 Cur PV 1 Act PV 1 VG Size <3,64 TiB PE Size 4,00 MiB Total PE 953826 Alloc PE / Size 507879 / <1,94 TiB Free PE / Size 445947 / 1,70 TiB VG UUID yqsyV9-h2Gl-5lMf-486M-BI7f-r3Ar-Todeh9 --- Volume group --- VG Name VG_XenStorage-c29b2189-edf2-8349-d964-381431c48be1 System ID Format lvm2 Metadata Areas 1 Metadata Sequence No 25 VG Access read/write VG Status resizable MAX LV 0 Cur LV 1 Open LV 0 Max PV 0 Cur PV 1 Act PV 1 VG Size <852,74 GiB PE Size 4,00 MiB Total PE 218301 Alloc PE / Size 1 / 4,00 MiB Free PE / Size 218300 / 852,73 GiB VG UUID 4MFkwD-1JW1-zVE3-QFKf-XmOX-QsSf-60oCKZ -

ok.... it really seems to be an io problem. any ideas what could cause this?
-
@fohdeesha does it ring any bell?
-
now i noticed that tje jdb2 and kworker processes have gone... but system is still extremly slow
on this video i try to install munin for future data to analyse the problem. As you can see absolutly nothing happens (this can take many minutes now). There is a rsync "running" at a very slow speed, but as you can see cpu usage is ultra low and also top says no system load.
I think it must be a problem with xcp-ng, but I have no idea what it could be.
-
Can you do a
dmesgand also asmartctl -a /dev/sdbandsmartctl /dev/sda?