Full Backup Successful But In Kilobytes
-
I'm curently running XO (5.107.1) community from source and have had scheduled backups for one of the XCP-ng server 8.0.0 regularly without issues previously with XO version 5.102.1. I originally wondered if it has something to do with the new version of XO but I rolled back to 5.98.1 and still have the same issue.
I am now getting successful backups but only in kilobytes for all the VMs on this particular XCP-ng server. Not sure if it has anything to do with it but I noticed in the gui showing the status of the job changing quickly from Started -> Interrupted -> Sucessful.
transfer Start: Dec 6, 2022, 02:18:05 PM End: Dec 6, 2022, 02:18:42 PM Duration: a few seconds Size: 5.62 KiB Speed: 154.26 B/s Start: Dec 6, 2022, 02:18:05 PM End: Dec 6, 2022, 02:18:42 PM Duration: a few seconds Start: Dec 6, 2022, 02:18:03 PM End: Dec 6, 2022, 02:18:42 PM Duration: a few seconds Type: fullBackup config is Full backup with Zstd compression and normal snapshot, SMB remote. If I include VMs from the problematic XCP-ng server and another in the backup job. It executes correctly and succesfully for one of them and the problematic server backup is only 5.63KB.
Nothing else has changed that I'm aware of, I have rebooted the XCP-ng server, XO server, and the remote storage, tries specifying a different remote storage point. I also create a new VM backup job but still the same. Other XCP-ng server backups from XO are working normally.
What else can I check? Does it have something to do with an error during snapshot? I doesn't look like it created the snapshot before transferring the 5KB.
Thanks.
-
@DeOccultist Hi,
Have you tired disabling ZSTD compression? What happen if you try to restore this backup? -
Hi @Darkbeldin
I disabled compression, the XVA is now 37KB
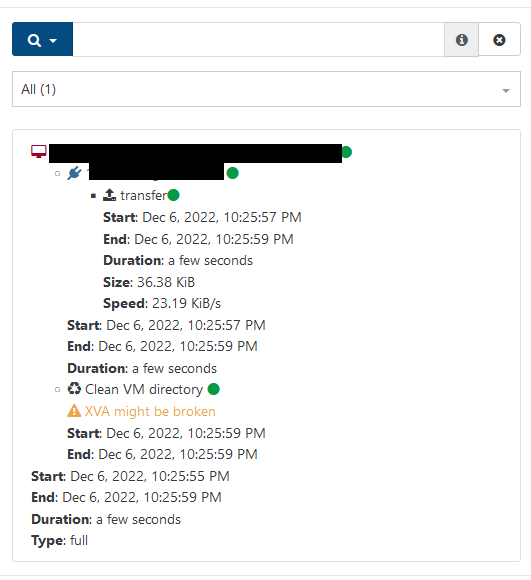
Normally it should say snapshot above transfer but I don't see it for some reason.
When trying to restore the backup, I get IMPORT_ERROR_PREMATURE_EOF().
-
@Darkbeldin I checked the xensource.log on the server and found the error message "failed with exception Server_error(INVALID_DEVICE, [ autodetect ])" during export, similar to the post here: https://xcp-ng.org/forum/topic/4319/invalid_device-autodetect-during-backup
I checked the XO dashboard health and found 256 "Pool Metadata Backup" VDIs attached to Control Domain.
Not sure how or why the "Pool Metadata Backup" got stuck attached to Control Domain but I guess it has reached the 256 limit. I "Forget" all of them and full backup seems to be working now.
For the record, it wasn't anything to do with snapshots. The VM was OFF so I guess it doesn't need to take a snapshot before transfer hence the log doesn't mention snapshot.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login