Migration between pools slow down or interrupted
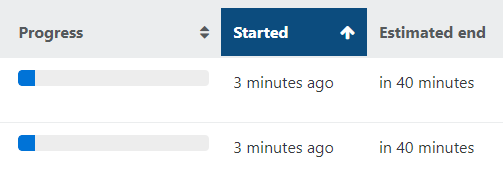
-
So, as you can read in the log:
SR_BACKEND_FAILURE_47. All CAPS messages are coming directly from the host. So it's NOT a Xen Orchestra issue, but something bad on your host. -
@olivierlambert that must like this
xe vm-migrate uuid=65ab6d31-60ef-7352-bde9-e509a5727660 remote-master=1.2.3.4 remote-username=root remote-password=password host-uuid=1396f539-9f94-42db-a968-289163e0e26e vdi=? VM's disk vdi?Performing a Storage XenMotion migration. Your VM's VDIs will be migrated with the VM. Will migrate to remote host: hostname, using remote network: eth2 Mng. Here is the VDI mapping: VDI 9fcba1f0-bd8a-4f60-8298-519a22793cc8 -> SR 7d01ed49-f06a-31f0-42a3-c7fc8527e65c This VIF was not mapped to a destination Network in VM.migrate_send operation vif: 36099318-9cdb-751f-d127-8447a00c66cbwhat else i need to specify?
-
As the answer given by the command, you need to provide a map for your VIFs and your VDIs.
A map is telling which disk is going to which SR on destination, and which virtual interface is going to which network on destination
-
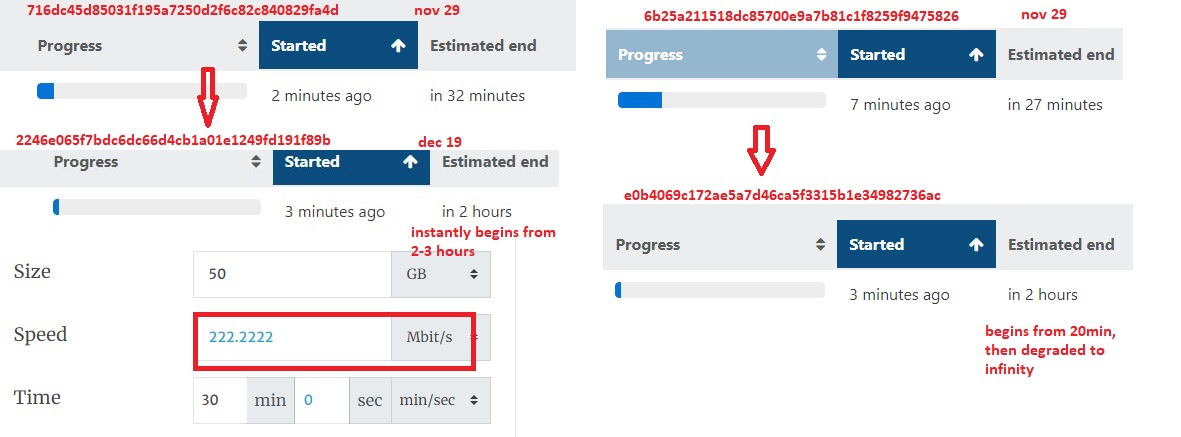
@olivierlambert finally got it.
vdi:vm vif id=new pool vif id, not new host.same speed as with XO.
-
As I said, then
") Your issue isn't XO related at all.
Your issue isn't XO related at all. -
@olivierlambert yay!
i'm rollback to6b25a211518dc85700e9a7b81c1f8259f9475826which is working for me from XO, then start migration from cli:
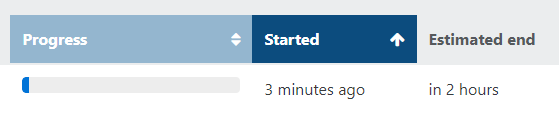
so, that HW or xen problem. could it be related with 8.2.1 clean installation? https://xcp-ng.org/forum/topic/6669/vdi_io_error-continuous-replication-on-clean-install?_=1672425861045
but migration to\from this pool works after install 20 days ago.
-
- XO version you are using doesn't matter in your case.
- It's hard to answer, I'm not inside your infrastructure. So many moving pieces could affect the migration speed. Network, I/O load, VM size etc.
-
@olivierlambert and last test, migration to 3rd pool - same speed.
so i have no idea what can be a cause.upd
pool2<>pool3 migration fastas should be.
3rd was disabled, i just turn it on for this test.
so that only pool1 problem. -
You can read https://xcp-ng.org/docs/troubleshooting.html and start digging in the logs
-
@olivierlambert still trying to find reason of problem. This question more about informative of logs.
something happens and now i can't migrate vms outside of pool
https://pastebin.com/afHQUiFBok it say
The VDI is not available [opterr=Interrupted operation detected on this VDI, scan SR first to trigger auto-repair]
but on scan i got same log
https://pastebin.com/WKA1juqzalso problem with backups. That another physical storage, nfs connection but same error again.
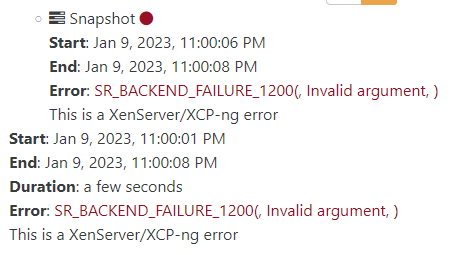
Also snapshot at few vms became orphaned and i can't delete them. again same log here.
https://pastebin.com/XPm1Y9Dfstorage have no error, raid is healthy, i can rescan 2nd lun but have same problems with migration.
again nothing interesting at SMlogJan 9 20:05:07 : [3865] lock: released /var/lock/sm/lvm-22fc6b8e-19f0-880b-e604-68431a93f91c/9fcba1f0-bd8a-4f60-8298-519a22793cc8 Jan 9 20:05:07 : [3865] ***** LVHD over iSCSI: EXCEPTION <class 'util.CommandException'>, Invalid argument Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/SRCommand.py", line 376, in run Jan 9 20:05:07 : [3865] sr = driver(cmd, cmd.sr_uuid) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/SR.py", line 156, in init Jan 9 20:05:07 : [3865] self.load(sr_uuid) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/LVMoISCSISR", line 329, in load Jan 9 20:05:07 : [3865] LVHDSR.LVHDSR.load(self, sr_uuid) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/LVHDSR.py", line 197, in load Jan 9 20:05:07 : [3865] self._undoAllJournals() Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/LVHDSR.py", line 1155, in _undoAllJournals Jan 9 20:05:07 : [3865] self._undoAllInflateJournals() Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/LVHDSR.py", line 1179, in _undoAllInflateJournals Jan 9 20:05:07 : [3865] lvhdutil.deflate(self.lvmCache, vdi.lvname, int(val)) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/lvhdutil.py", line 197, in deflate Jan 9 20:05:07 : [3865] vhdutil.setSizePhys(path, newSize) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/vhdutil.py", line 262, in setSizePhys Jan 9 20:05:07 : [3865] ioretry(cmd) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/vhdutil.py", line 102, in ioretry Jan 9 20:05:07 : [3865] errlist = [errno.EIO, errno.EAGAIN]) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/util.py", line 330, in ioretry Jan 9 20:05:07 : [3865] return f() Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/vhdutil.py", line 101, in <lambda> Jan 9 20:05:07 : [3865] return util.ioretry(lambda: util.pread2(cmd), Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/util.py", line 227, in pread2 Jan 9 20:05:07 : [3865] return pread(cmdlist, quiet = quiet) Jan 9 20:05:07 : [3865] File "/opt/xensource/sm/util.py", line 190, in pread Jan 9 20:05:07 : [3865] raise CommandException(rc, str(cmdlist), stderr.strip())is it possible to get more information from XO about whats really wrong?
-
No, the issue is deep within your host, and not in XO. You need to tail the SMlog while doing a scan, check if you have ISO mounted in your VM and all of that. This can take time, but if you do it carefully, you might your problem
-
@olivierlambert solved. that was somewhere here.
Jan 10 16:32:51 SM: [6019] lock: released /var/lock/sm/.nil/lvm Jan 10 16:32:51 SM: [6019] ['/sbin/dmsetup', 'status', 'VG_XenStorage--22fc6b8e--19f0--880b--e604--68431a93f91c-VHD--9fcba1f0--bd8a--4f60--8298--519a22793cc8'] Jan 10 16:32:51 SM: [6019] pread SUCCESS Jan 10 16:32:51 SM: [6019] lock: released /var/lock/sm/lvm-22fc6b8e-19f0-880b-e604-68431a93f91c/9fcba1f0-bd8a-4f60-8298-519a22793cc8 Jan 10 16:32:51 SM: [6019] ***** LVHD over iSCSI: EXCEPTION <class 'util.CommandException'>, Invalid argumentone of VHD became corrupted so no backups, storage can't be mounted, speed issues, etc. Need to remove it manually and it works again.
in my opinion xen should ignore such error and work with SR same way like with hdd bad blocks. But it works how it works.
-
Good catch