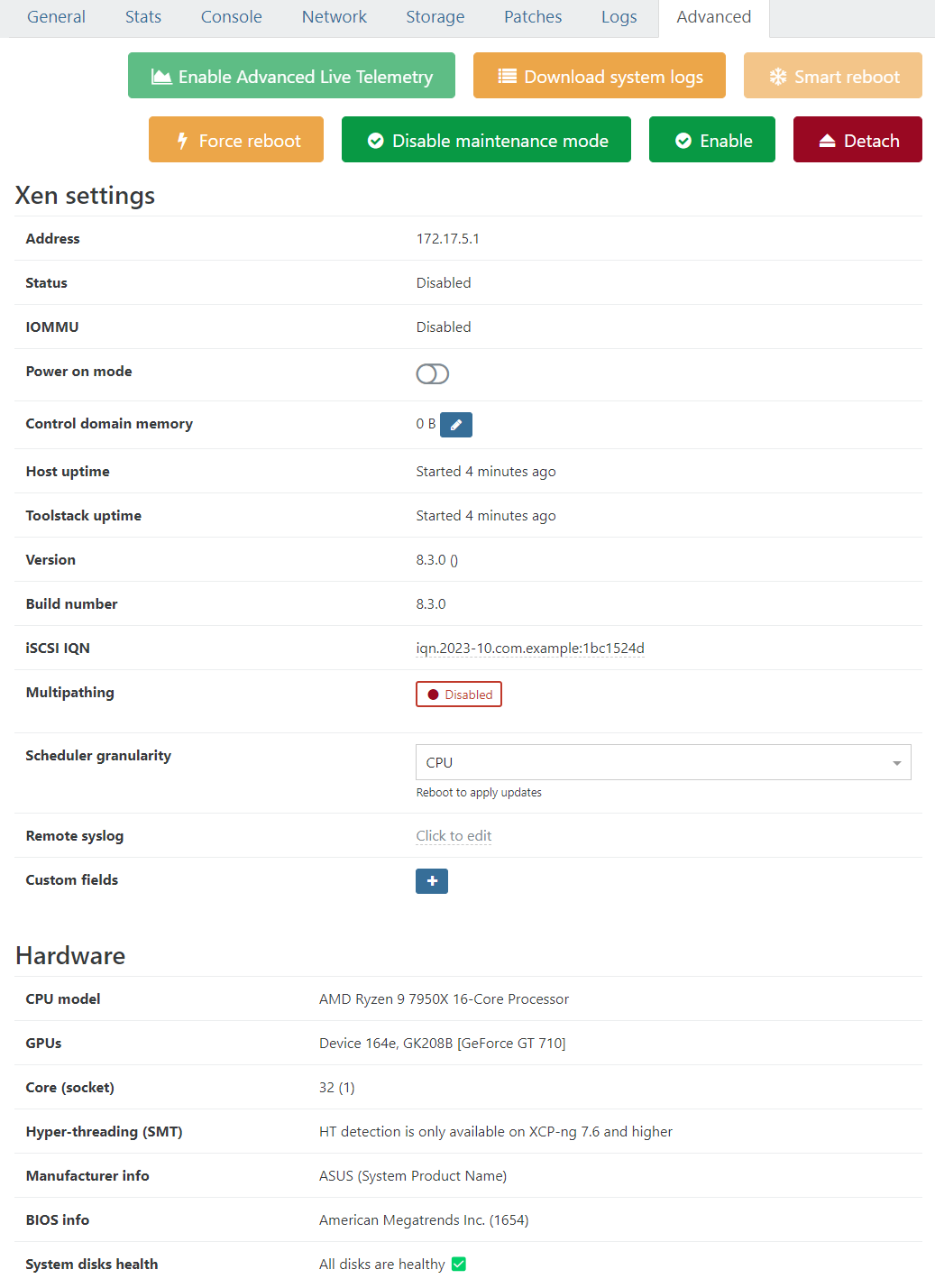
After installing updates: 0 bytes free, Control domain memory = 0B


-
-
@yann
Hello Yann, thank you for pitching in.

-
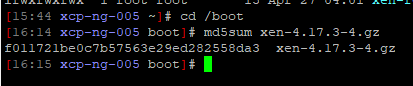
@Dataslak can you please request a commandline from GRUB (hit
con the boot menu), and issue the following commands:echo $root search --label --set root root-eqjpzg echo $root -
Also a
cat /proc/mdstatin the Dom0 would help. -
Info: I am mirroring two M.2 SSDs ! Software RAID established by the installation routine of v8.3.
Could the mirror be broken and cause this somehow? -
@olivierlambert said in After installing updates: 0 bytes free, Control domain memory = 0B:
Also a cat /proc/mdstat in the Dom0 would help.
Please forgive my ignorance: How do I execute this command in Dom0 ?
I've read https://wiki.xenproject.org/wiki/Dom0 and it helped a little. Do I run the command in the console within XOA?
-
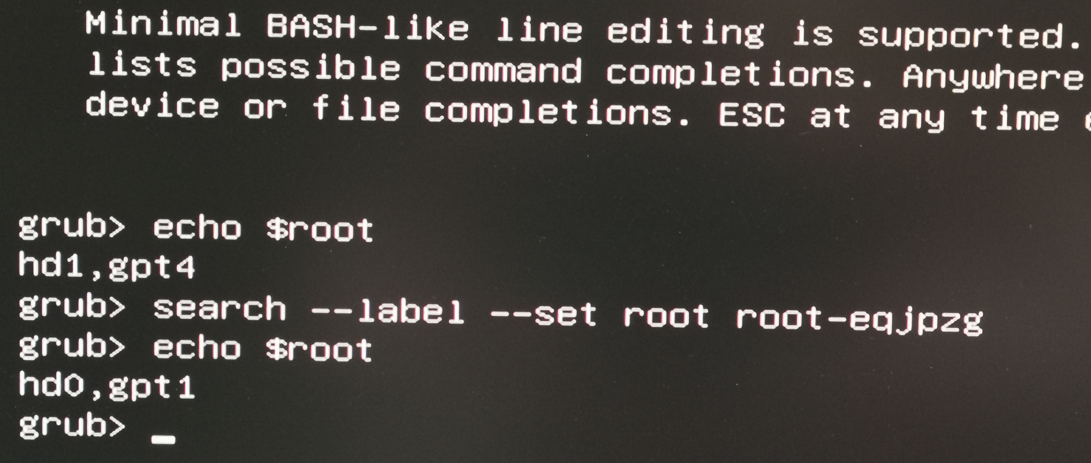
@Dataslak so it is choosing to "boot from the 1st disk of the raid1", we could try to tell him to boot from the 2nd one:
- on the grub menu hit
eto edit the boot commands - replace that
search ...line withset root=hd1,gpt1 - then hit Ctrl-x to boot
- on the grub menu hit
-
@Dataslak Dom0 is "the host" (if you think it's the host it's not really but anyway), ie the machine you are connected to and showing results since the start
")
-
@yann
Wohoo!!
All VMs came up!
Host is not in maintenance mode.
Control domain memory = 12GiB
Stats are back
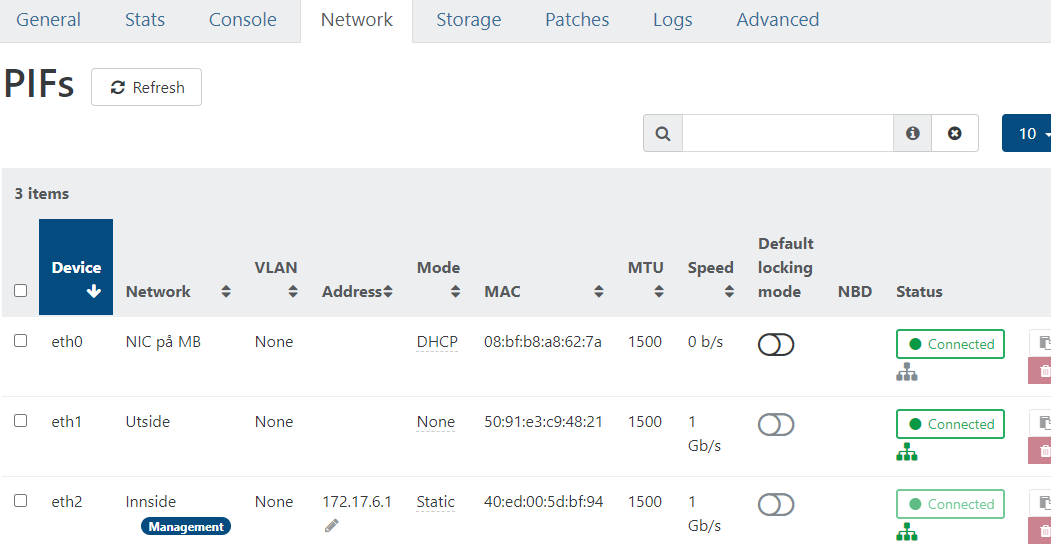
Etc....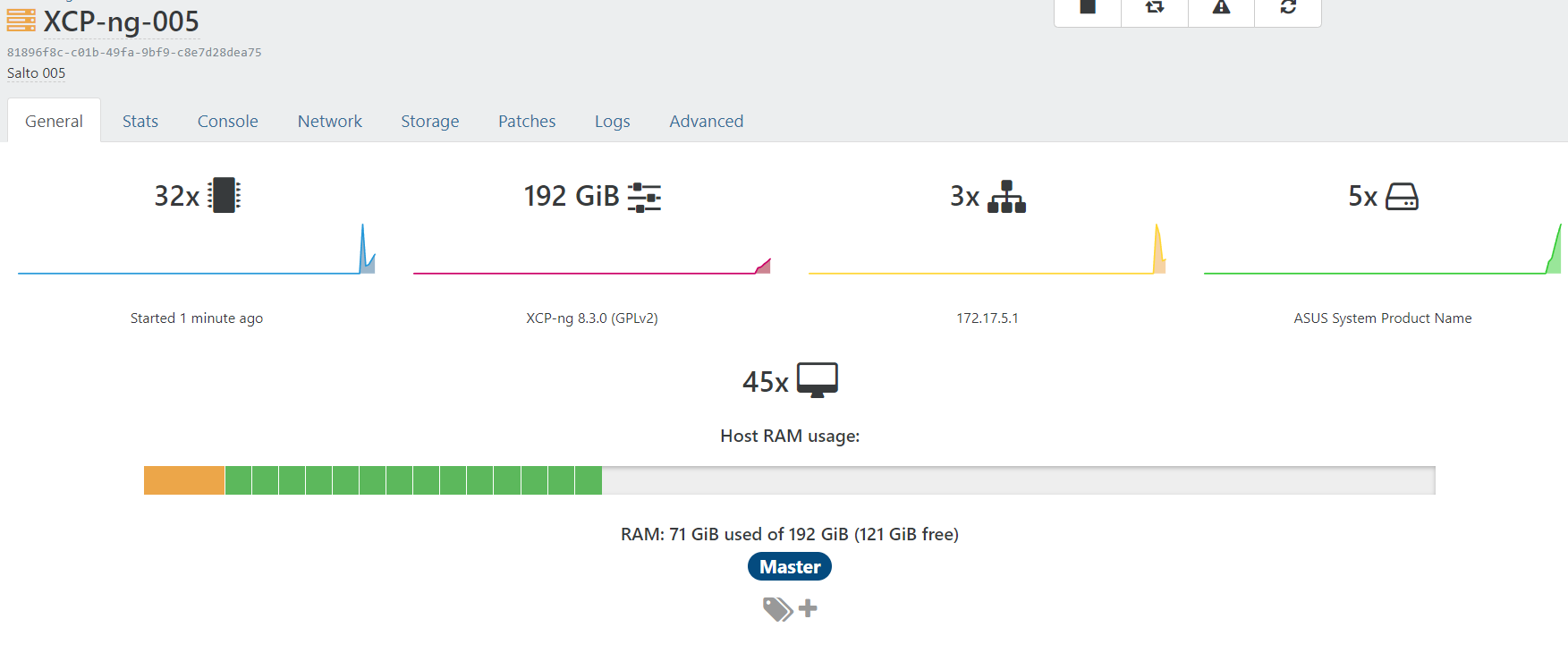
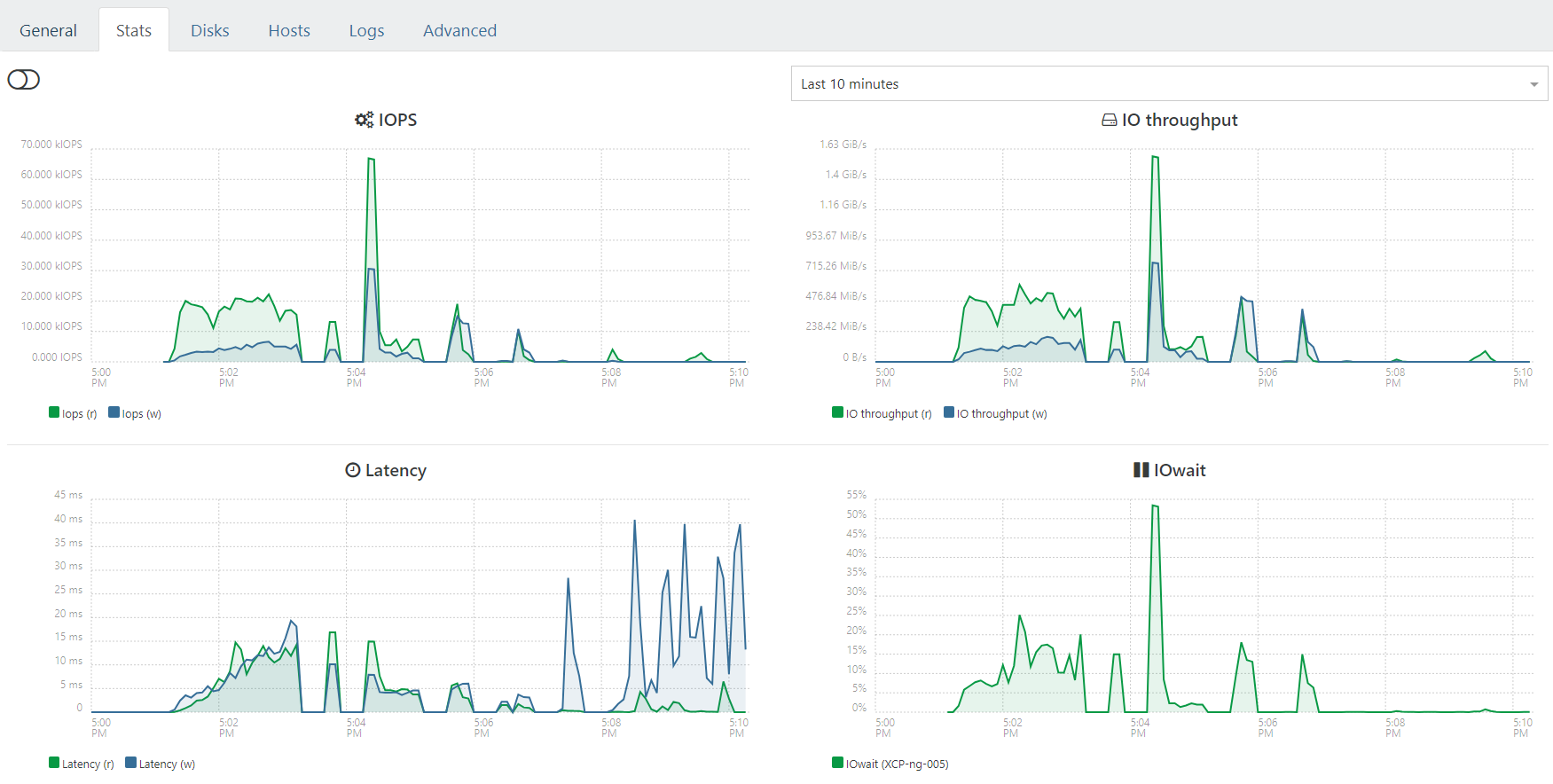
As far as I can see (which is limited) everything looks good?
How can I see the status of the RAID1 and see if the mirror is intact ?
-
@olivierlambert
Thank you for explaining to me. I will look more into details when (if) I find time
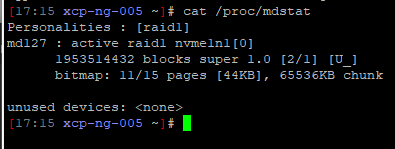
Ah - I see you were ahead of me !
How can I interpret this? Raid1 OK? Synched? Ready to deal with a single drive failure?
How will XO inform me if one of the drives fails? Will I have to scour through logs, or will there be a clear visible notice in the interface?
-
That's the problem. Your RAID1 lost the sync. And so it continued to boot on the disk out of sync, loading the old Xen from the boot while the rest (root partition) was up to date.
-
@olivierlambert
Since this happened on six servers simultaneously when applying updates through XO I guess we may have found an error ?If so then all of this was not in vain, and I can be happy to have made a tiny tiny contribution to the development of 8.3 ?
Will the modification of the Grub boot loader be safe to apply to all remaining 5 servers? Or should I do some verification on each before applying it?
Is the modification of Grub what I will have to do if a drive fails? Change that one line from set root=hd1,gpt1 to set root=hd0,gpt1 or something?
-
I don't know yet, but you lost one drive. Can you run
xe host-call-plugin host-uuid=<uuid> plugin=raid.py fn=check_raid_pool? (replace with the UUID of the host)edit: check that on all your other hosts
-
XCP-ng-002:
This runs 8.2.1 with only one drive. I was planning on upgrading it to 8.3 and insert another drive to obtain redundancy when time was available:

XCP-ng-003:

XCP-ng-004:

XCP-ng-005:

XCP-ng-006:

XCP-ng-008:
This server is clean installed after the problems

Can your trained eyes see anything I should be aware of?
-
I can immediately see the hosts with the State: "clean, degraded" on XCP-ng 005. The rest is in the state "active", which is OK.
So you don't have a similar issue on your other hosts, it's only with this one, you have a dead disk (not syncing since a while). Try to check the dead disk and if you can, force a RAID1 sync on it.
-
@olivierlambert
XCP-ng-005 is the only 8.3 host I have restarted so far. All the hosts showing "3" in the triangle is asking for a reboot and claims hardware does not support virtualization.

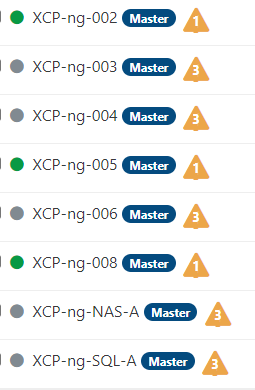
Shall I try to reboot one of them and see if the RAID1 breaks like it did on XCP-ng-005?
If you plan on going home for the week-end soon then we can delay this until monday? I hope the power does not fail in the meantime (it very very rarely does; it is very reliable where I am).
I do not wish to keep you at work. But if you - like me - plan to remain at work then I am very happy to keep going.Please forgive my rudeness:
THANK YOU for solving the problem so far! The 900+ USD I invested 3/4 year ago was money well spent. Not only is your product amazing. Your skill and availability is also great! -
@Dataslak if you only launched the upgrade and did not reboot yet, that alert is normal. Now if you did reboot them already, there is likely a problem.
One idea crossed my mind: when you upgraded to 8.3, in the list of products found on your disks, were you properly proposed to upgrade a RAID install, on all those hosts?
-
@yann
6 hosts had originally been running 8.3 for half a year. A bit of time had passed since I had last checked for updates when I noticed several were waiting to be installed. I accepted this in XO, and honestly did not check what the individual updates did. The names and texts are greek to me (and I speak Norwegian :-).
When the updates were installed I only rebooted one of the six hosts: XCP-ng-005. I do not remember if this was because I was interrupted by a phone call or colleague or something.When I checked back after the reboot I noticed that none of the VMs had come up. Then I discovered all the other symptoms.
Since no VM could be started on the rebooted host - and all were running fine on the remaining 5 hosts - I chose to not reboot any of the other hosts.Fearing that the same thing that happened to XCP-ng-005 will happen to the rest upon reboot I will delay doing so until Vates tell me when it suits them best. Perhaps monday morning is extra busy because week-end has passed. If so then I will wait until tuesday or wednesday.
If it turns out that the remaining hosts reboots fine and the sole reason for my worries was XCP-ng-005 broken mirror then I will LOL. Then ask if we can have some more visible notification in XO when a RAID breaks so we won't have to scour logs to discover such important events.
RAID install:
The only servers I had 8.2 on originally were XCP-ng-001 and 002. Those I could install 8.2 fine. They had ony one drive each. -Could not afford more back then.
XCP-ng-001 died after some time. This was a small testing/learning server. No big loss.
Then I put 003, 004 and 005 together using different hardware than 001 and 002. Here: Trying to install 8.2 failed : Black screen midway during install.
Reading the forums I read that 8.3 had better driver support for modern PC hardware. This worked fine.Two more small servers were added later to host only a handful of VMs (SQL, file server, file backup). These were also installed with 8.3 to "standardize" on this version which I had come to rely on. Had forgotten that this was a beta.
I had long planned on upgrading XCP-ng-002 to 8.3. But since this host only has one drive I planned on emptying VMs over to other hosts, then install the second drive and clean-install it with 8.3 instead of upgrading it. Installing XCP-ng is a walk in the park, and I have had better experience with clean-installs rather than upgrades when it comes to OSes.
In short: No currently running hosts have been upgraded.
Only time I've even tried upgrading was recently when experimenting on XCP-ng-008.
Learning that v8.3 is beta and not recommended for production environments I was desperate since only one of my hosts could install 8.2 without black screen.
Then stormi gave me an 8.2.1 image with additional drivers. This installed fine on the hardware I use.
I then did some testing with upgrading and downgrading between 8.2 and 8.3 to learn what worked and not. Learning that downgrading will not preserve VMs (it states this clearly in the installation routine) I did a clean-install of 8.2.1 on XCP-ng-008 before re-creating all VMs from the failed 005 host on 008 (took me 22 hours of hard concentrated work).So I have been presented with the RAID step during upgrade from 8.2 to 8.3, and remember having navigated into it to see that both drives were still selected. But the servers in production are all clean-installed and not upgraded.
I fear I have not replied to your question. If you do not find the answer in my text then please help me understand
-
@Dataslak said in After installing updates: 0 bytes free, Control domain memory = 0B:
Since this happened on six servers simultaneously when applying updates through XO I guess we may have found an error ?
Nothing tells us it happened on 6 servers. For now, all we know for sure is it happened on one. The rest, you didn't reboot, so they are in a state where it's normal that you can't start new VMs, since Xen was updated from version 4.13 to 4.17 and requires a reboot.
-
@stormi
I am not as experienced as you with what the tabs of a host may display when updates have been installed and host is waiting for reboot.I have delayed restarts before until nightfall to reduce burden on customers. And then I have not seen hosts behave like this :

And:
etc.
If these are possible behaviors after updates are applied then I will add this to my experience and not be so worried next time.
In my ignorance I calculated bad odds for:
- Me randomly choosing to restart the one host with a broken mirror (1/6)
- Host "chose" to boot from the drive that had not been updated properly due to drive failure (1/2)
- But updated properly enough so the update engine did not report any updates (1/A)
(or perhaps did not do so because the host was in service?) (1/1) - Grub chose to boot from the failed drive (1/2)
- And succeeded because drive did not fail enough for the RAID-system to choose the fully functional drive (est. 1/4)
- XO does not report with a red triangle that RAID has been broken (Would that be a nice feature?) (1/B)
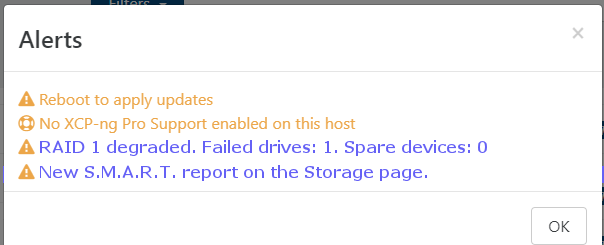
Odds: 1 : 96xAxB
Another nice feature would be if this alert system could provide S.M.A.R.T. alerts to better help operators mange drives in their hosts. Currently I feel a bit in the dark on how drives are faring in the hosts.
(I hope you will forgive me for my word salad.)
Can you confidently tell me that restarting another host will work fine?
If the VMs do not come back up then I have no more vacant hardware to establish new ones on (008 was the one I had for backup).
And it will cost me >20 hours of hard labour to do so.
And my colleagues will have to deal with angry customers who may not feel safe purchasing more VMs from me.I aim to build a business, that in turn will pay 1000 USD per host per year to you. I just need help to start up this arm of the company.
If the sales team will get in touch with me so I can negotiate a subscription cost with them, then I hope to unlock features in XO that allow me to better utilize the hardware I have, reduce risks, and free up time I can use to develop my product and sell more.