CBT: the thread to centralize your feedback
-
So i have had good luck with NBD+CBT enabled for around the last week, however "Purge snapshot data when using CBT" causes me a number of issues unfortunately especially after a migration from one host to another with a shared SR as reported above. Hoping to see that fixed in the next release coming soon!
")
Recently I've discovered that it seems the coalesce process with "purge snapshot data" enabled does something our NFS storage array does not like. If a coalesce process with "Purge snapshot data when using CBT" enabled runs for too long of time the NFS server will start dropping connections. I have had this happen a few times last week and have not been able to explain it. Is the process quite different from the standard coalesce process? Trying to come up with something to explain why the array gets so angry!
I have a case open with our storage vendor and they pointed out that the client gets disconnected due to expired NFS leases when this happens. It might be a coincidence this happens during backup runs, if it continues to happen i plan to try NFS3 instead of NFS4.1 as well but something i thought i'd report!
-
i try to migrate VDIs to another storage. After 4 hours no one is migrated, new tasks run and close in loop.
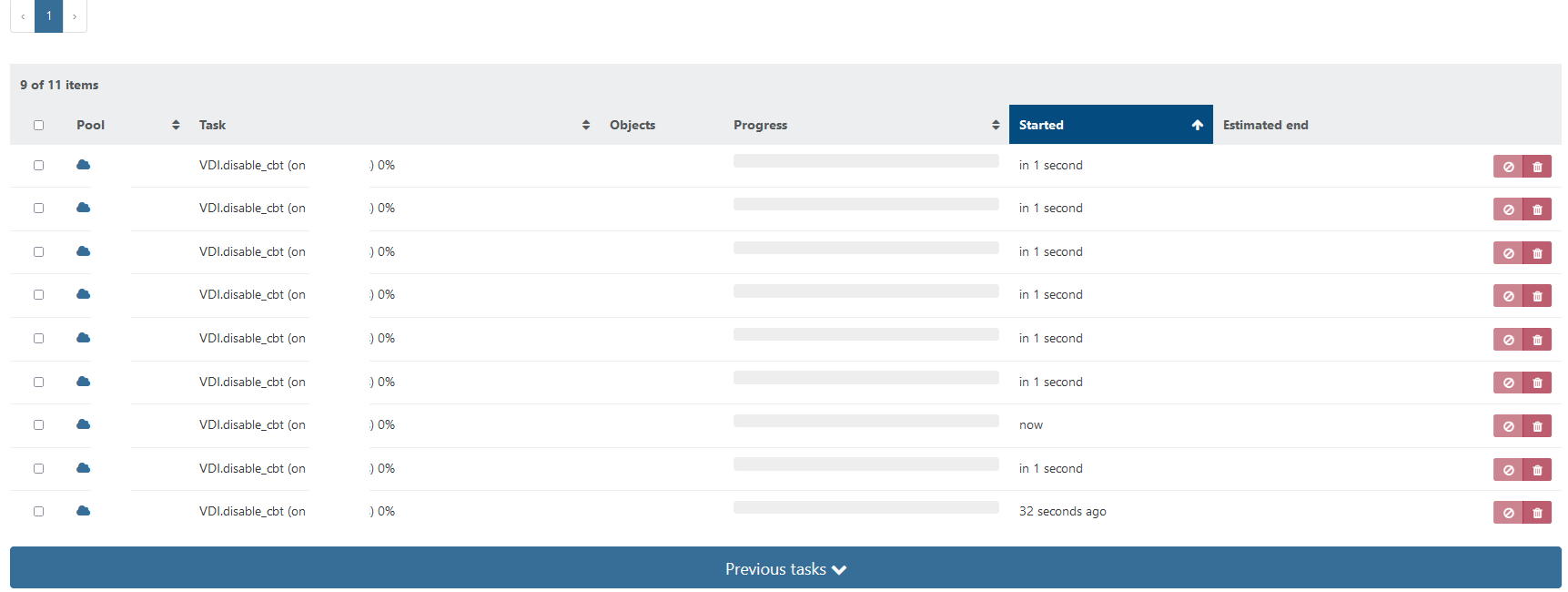
-
I think a fix is coming very soon in master by @florent
-
Sadly the latest XOA update does not seem to resolve the "falling back to base" issue for me which occurs after migrating a VM from one host to another. (Using a shared NFS3 SR)
-
Can you bring the entire log please? We cannot reproduce the issue
 This should NOT happen if the VDI UUID is the same.
This should NOT happen if the VDI UUID is the same. -
@olivierlambert For sure! Where is the log location on the XOA appliance? I'd be happy to provide it. I can also provide a support tunnel!
I can reproduce this on 2 separate pools (both using NFS3) so getting logs should be easy!
-
I am testing the new release as well but we had some issue this week with one repository so i need to fix that as well. So far the jobs seem to process normally.
@olivierlambert or @florent what issues should be fixed by this release?
-
@flakpyro Don't you have a small download button for the backup log to get the entire log?
-
@olivierlambert My bad i see the button to download the log now!
Here is the log: https://drive.google.com/file/d/1OO8Rs6pST-W0qplpVu-E5lafYFXzhJA2/view?usp=drive_link
-
Hi,
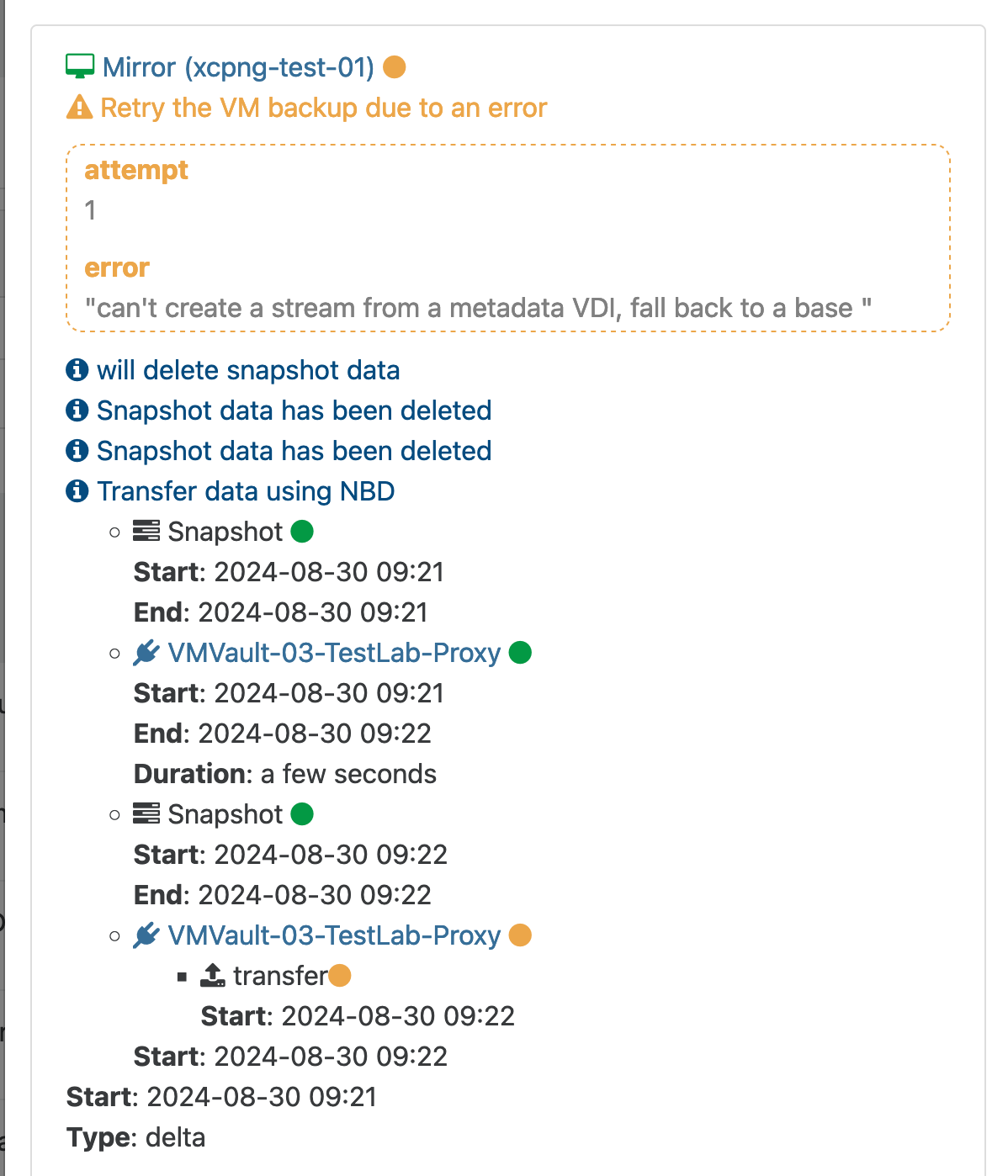
Same here, I updated XOA to 5.98 and I have this error
"can't create a stream from a metadata VDI, fall back to a base" on some VM
I have an active support contract.
Here the detailed log
{ "data": { "type": "VM", "id": "96cfde06-61c0-0f3e-cf6d-f637d41cc8c6", "name_label": "blabla_VM" }, "id": "1725081943938", "message": "backup VM", "start": 1725081943938, "status": "failure", "tasks": [ { "id": "1725081943938:0", "message": "clean-vm", "start": 1725081943938, "status": "success", "end": 1725081944676, "result": { "merge": false } }, { "id": "1725081944876", "message": "snapshot", "start": 1725081944876, "status": "success", "end": 1725081978972, "result": "46334bc0-cb3c-23f7-18e1-f25320a6c4b4" }, { "data": { "id": "122ddf1f-090d-4c23-8c5e-fe095321f8b9", "isFull": false, "type": "remote" }, "id": "1725081978972:0", "message": "export", "start": 1725081978972, "status": "success", "tasks": [ { "id": "1725082089246", "message": "clean-vm", "start": 1725082089246, "status": "success", "end": 1725082089709, "result": { "merge": false } } ], "end": 1725082089719 }, { "data": { "id": "beee944b-e502-61d7-e03b-e1408f01db8c", "isFull": false, "name_label": "BLABLA_SR_HDD-01", "type": "SR" }, "id": "1725081978972:1", "message": "export", "start": 1725081978972, "status": "pending" } ], "infos": [ { "message": "will delete snapshot data" }, { "data": { "vdiRef": "OpaqueRef:1b614f6b-0f69-47a1-a0cd-eee64007441d" }, "message": "Snapshot data has been deleted" } ], "warnings": [ { "data": { "error": { "code": "VDI_IN_USE", "params": [ "OpaqueRef:989f7dd8-0b73-4a87-b249-6cfc660a90bb", "data_destroy" ], "call": { "method": "VDI.data_destroy", "params": [ "OpaqueRef:989f7dd8-0b73-4a87-b249-6cfc660a90bb" ] } }, "vdiRef": "OpaqueRef:989f7dd8-0b73-4a87-b249-6cfc660a90bb" }, "message": "Couldn't deleted snapshot data" } ], "end": 1725082089719, "result": { "message": "can't create a stream from a metadata VDI, fall back to a base ", "name": "Error", "stack": "Error: can't create a stream from a metadata VDI, fall back to a base \n at Xapi.exportContent (file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/xapi/vdi.mjs:202:15)\n at process.processTicksAndRejections (node:internal/process/task_queues:95:5)\n at async file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_incrementalVm.mjs:57:32\n at async Promise.all (index 0)\n at async cancelableMap (file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_cancelableMap.mjs:11:12)\n at async exportIncrementalVm (file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_incrementalVm.mjs:26:3)\n at async IncrementalXapiVmBackupRunner._copy (file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_runners/_vmRunners/IncrementalXapi.mjs:44:25)\n at async IncrementalXapiVmBackupRunner.run (file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_runners/_vmRunners/_AbstractXapi.mjs:379:9)\n at async file:///usr/local/lib/node_modules/xo-server/node_modules/@xen-orchestra/backups/_runners/VmsXapi.mjs:166:38" } }, -
So far i did see this fall back to base error only once, it looks like it does finish correct in the retry action. I will keep an eye on this.
-
I was having a backup fail due to the VDI must be free error, but updating XOA to the latest commit fixed that.
Now I'm getting VDI IN USE errors when backing up. Going to the Health tab of the Dashboard lists the VDIs still attached to the Control Domain. However, when I try to forget the VDI, I get the OPERATION NOT PERMITTED VBD still attached error.
I've enabled maintenance mode on the node which migrated the VMs to my other node, but that didn't fix the issue. I assume because I'm using shared storage. I tried coalescing the leaf but there were none.
Any suggestions for the next step?
-
@CJ u need to check what host the vdi is attached to and reboot that host. That will release this vdi.
-
@rtjdamen The VMs were running on the master so I had rebooted it since I don't recall how match the UUIDs. I'll try rebooting the other node and see if that works.
EDIT: That worked. Even though they were running on the master they were attached to the other node.
-
@rtjdamen I notice this too, on retry it does run, but it seems to take much longer than a normal incremental backup would take so not entirely sure whats going on there. It ONLY happens if i migrate a VM from one host to another for me. (On shared NFS storage)
-
@CJ nbd does pick a random host for transfer so it is not specific the poolmaster. U should be able to determine the host holding this vdi in the error message.
-
@flakpyro this is because it creates a new full, i think it has an issue with the cbt to be invallid what is causing it to run a new full.
-
@rtjdamen Correct, it does appear to run a full. Even though the backup report afterwards says it ran a "delta". After that initial run it will run backups error free again, unless i migrate the VM to another host in which case the same error occurs once again.
-
@flakpyro yes, we do not see this error in relation to a migration but it does sometimes just occur, in the prior version it failed in the retry, with the latest version it does resolve itself so it is improved a bit.
We also still see the vdi in use errors, would be nice if they will be improved.
-
I'm not sure if this happened after my initial manual run of my backup job or the scheduled one that ran afterwards, but one of the VMs is now showing again as attached to the control domain.
Is this something I need to keep checking or should it resolve itself? The backup job completed hours ago.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login