Updated and tested:
- one single Host
- lab-Pool (3 Hosts) - NFS Storage
- lab-Pool (4 Hosts) - iscsi Storage
Everthing seems to work as expected.
(new VM, live-migration, snapshots, clone VMs, import/export VMs)
Updated and tested:
Everthing seems to work as expected.
(new VM, live-migration, snapshots, clone VMs, import/export VMs)
Hi @all,
sorry for my late reply, but i was on site at a customer yesterday.
I can confirm its working again as expected.
Not only this, but it also cleaned up all the additional Replikas now.
Great work and thanks for all your efforts.
Kind regards
Alex
@probain
I have a similar, even not the same Problem right now.
Maybe there is the same root-cause, so im linkin it here.
https://xcp-ng.org/forum/topic/11540/continuous-replication-isnt-deleting-old-replikas-anymore-since-update
Kind Regards
Alex
Hi @all,
running XO from source - (Commit fa020) on a fully update XCP-NG 8.2.
I have 2 CR Jobs on 2 XCP-Hosts, replicating all running VMs vice versa with a retention of 2 three times a day.
This worked for Months flawlessly, so i always have on srv01 2 replikas of each running VM on srv02 and vice versa.
Since Friday (did an Update of XenOrchestra that day), replication is still running fine but the old replikas are not deleted anymore, resulting in 12 existing replikas today.
I've tried to delete the old schedule and re-create it.
I've tried to delete the replication-job, and re-create it.
I've tried adjusting the retetion
I deleted all Replikas and startet the jobs from scratch.
None of the above have had any discernable affect.
Any Idea where to start investigating?
I searched the forum, but could not find any existing topic like this, except one similar, but not the same Problem.
https://xcp-ng.org/forum/topic/11539/snapshots-are-no-longer-being-pruned-commit-58f02
Maybe it could be the same root cause, so i am linking it here.
Thanks for suggestions in advance!
Alex
@stormi
Did some Testing over the Weekend too.
Setup with 2 Hosts in a Pool and shared iSCSI-LMV Storage with multipath 8 paths per LUN.
Anything seems to work fine (migrate/import/cross-pool-migrate/snapshots/backups).
Even our longtime Problem (snapshots taking much too long) is getting much better (still not good, but much better).
Thanx for your replies.
And sorry, i havent seen your first reply between my last posts with the link to your existing Thread.
So, i think this is some kind of a bigger thing.
Will handle with care, but i have to leave for today.
Maybe i have time to test the snapshot and revert workarounds on the weekend.
But these are all production VMs.
Have to coordinate.
I have 2 NFS-SRs in the Pool.
Will try to migrate VMs from one to the other and see if this helps.
Kind Regards and thx again
Alex
Thanks for your Reply.
Just one little correction.
Also in XO6, the Disks are missing in the VM-VDI Tab.
Its exactly the same in XO5 and XO6.
Only in XCP-ng Center i see the Disks.
I noticed an additional thing.
In the Health-Dashboard, i see one orphaned "base copy" for each Disk that is adressed by this behaviour.
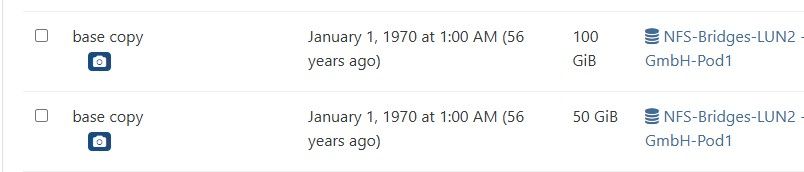
Exactly the amount of Disks of all my VMs with this problem.
(in the screenshot only the two of the VM of the former screenshots)
I am shure there are no orphaned VDIs, its just the base-copies of all my active Disks.
I think this could be possibly extremely dangerous, if someone has the same problem and removes the orphanes at this point.
But maybe i am too paranoid here?
@Pilow
Indeed.
Thats exactly the Point.

All my VMs that ran into my nightly Backups, have this.
To test it i created a new VM that didnt get a snapshop yet.
In the new VM i see the Disks.
Hi @all,
i noticed a strange behaviour in one environment with one pool (2 Hosts and NFS Storage) and 2 single node xcp-ng servers.
XenOrchestra from sources, connected directly to the pool and the 2 Servers.
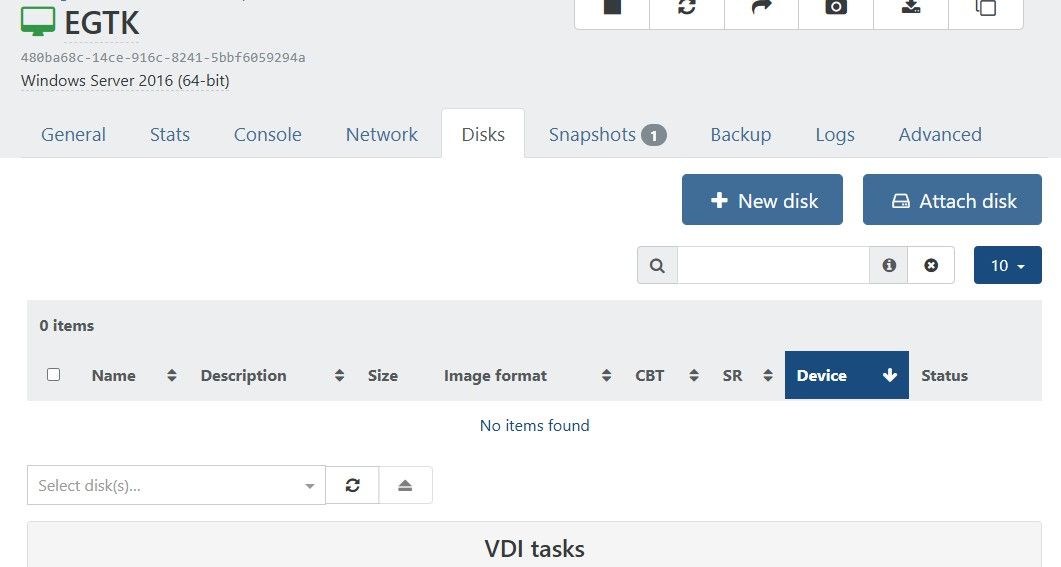
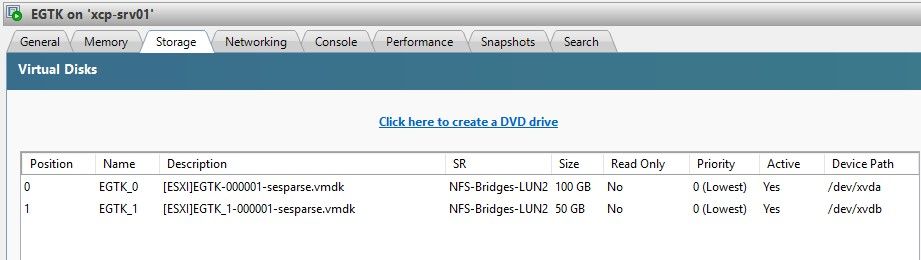
When i open a VM in XenOrchestra, resident on an a single node, i see the VM Disks in xo and similar in XCP-ng Center.
When i open a VM in the same XenOrchestra resident on the pool (no matter if disks are on nfs shared storage or local storage of a Host), i dont see the disks in XenOrchestra (looks like no disks attached).
But in XCP-ng Center the disks are there and the VMs are running fine.
I did a full update today of XenOrchestra to actual commit and also upgraded the pool today (rebootet master first, then slave).
But the issue is still the same.
Is there anyone who has the same issue?
Screenshots of one of the VMs on the Pool:
in XenOrchestra
in XCP-ng Center
Hi @all,
sorry for my late reply, but i was on site at a customer yesterday.
I can confirm its working again as expected.
Not only this, but it also cleaned up all the additional Replikas now.
Great work and thanks for all your efforts.
Kind regards
Alex
@probain
I have a similar, even not the same Problem right now.
Maybe there is the same root-cause, so im linkin it here.
https://xcp-ng.org/forum/topic/11540/continuous-replication-isnt-deleting-old-replikas-anymore-since-update
Kind Regards
Alex
Hi @all,
running XO from source - (Commit fa020) on a fully update XCP-NG 8.2.
I have 2 CR Jobs on 2 XCP-Hosts, replicating all running VMs vice versa with a retention of 2 three times a day.
This worked for Months flawlessly, so i always have on srv01 2 replikas of each running VM on srv02 and vice versa.
Since Friday (did an Update of XenOrchestra that day), replication is still running fine but the old replikas are not deleted anymore, resulting in 12 existing replikas today.
I've tried to delete the old schedule and re-create it.
I've tried to delete the replication-job, and re-create it.
I've tried adjusting the retetion
I deleted all Replikas and startet the jobs from scratch.
None of the above have had any discernable affect.
Any Idea where to start investigating?
I searched the forum, but could not find any existing topic like this, except one similar, but not the same Problem.
https://xcp-ng.org/forum/topic/11539/snapshots-are-no-longer-being-pruned-commit-58f02
Maybe it could be the same root cause, so i am linking it here.
Thanks for suggestions in advance!
Alex
crosstestet with XOA
All working fine as expected.
So it seems that first Host has some Problems and is not providing any useful data when it comes to exporting the first delta snapshot.
Unfortunately i have to change to customer support right now and have to stop my testings for today.
I will keep going tomorrow.
Thx for your support so far.
ok, so i tested with XOA.
fully new (empty) NFS-Export mounted as remote in XOA.
i will crosstest now with a VM on the working Host.
its a 12-Disk Synology-NAS with btrfs.
On that NFS-Storage are multiple folders exported as remotes in my XOfs Installations.
As i said. All other Hosts/XOfs Installations work fine on that NFS-Storage.
Only this one specific XCP-ng Host has these Problems. So i think its not XenOrchestra related. It seems to be a problem with XCP-ng on this specific Host, but the identical second Host does not have this Problem.