@stormi That is quite possible. I'll open a ticket for further investigation.
pkgw
@pkgw
Technical Lead of the IAU Minor Planet Center hosted at the Center for Astrophysics | Harvard & Smithsonian.
-
RE: Second (and final) Release Candidate for QCOW2 image format support
-
RE: Rolling Pool Update fails with HOST_NOT_ENOUGH_FREE_MEMORY, when it really ought to be fine
@andriy.sultanov Yes, I completely agree, which is why I brought up the narrower case. I'd put it like this:
- You can't just plan the process and blindly execute that plan, because the ground might shift underneath your feet.
- This implies to me that the individual steps of the RPUs (individual host evacuations, mainly) would benefit from being made more resilient
- But there's still value in trying to make a plan. First, there are different sequences of moves that might be more or less efficient, and you might as well try to be more efficient, even if you might have to change course midway through.
- And second, if you can't even come up with a plan that works in theory, you know that you have a real problem.
I'm pretty sure the gold-plated approach would be start with a plan, evacuate resiliently, reboot, re-plan based on the current ground truth, evacuate, reboot, etc. If you have the code to plan things out once, rerunning it after every step isn't too much extra (though it does need to learn to keep track of the dwindling number of hosts that need reboots).
-
RE: Rolling Pool Update fails with HOST_NOT_ENOUGH_FREE_MEMORY, when it really ought to be fine
@Danp No, it's not quite that. We don't use HA anywhere. But reading the source code I did notice exactly what's mentioned in that bug: in some HA cases, the xen-api code will throw a NOT_ENOUGH_FREE_MEMORY that is just absolutely misleading.
At the macro scale, I think that you could say that the issue I'm running into is that the RPU migrations aren't planned out across the entire process of the RPU. If you have VMs that take up a significant fraction of some hosts' memory, failure to plan the whole process at once can lead the system to get itself "wedged" where it's unable to evacuate one of the hosts.
More narrowly, you could say that the issue is that during an RPU the host evacuation code gives up more easily than it could. Say that you're trying to evacuate host A with a 64 GB VM, and you have two other hosts, B and C, with 60 GB free. It will give up, even if there are VMs that you could move from B to C (or vice versa) that would open up one of them to having 64 GB free. If the evacuation during the RPU was more resilient, then the macro-scale issue would be less of a problem. (Although with a more resilient evacuation command but no large-scale planning, you might end up with an RPU that succeeds but is wildly inefficient.)
-
RE: Rolling Pool Update fails with HOST_NOT_ENOUGH_FREE_MEMORY, when it really ought to be fine
OK, I've spent some time looking into this and have learned a few things worth mentioning.
First, there is pretty ample logging of the RPU planning step in the
/var/log/xensource.logfile. In my particular case it didn't end up being directly helpful, but it's a good resource to be aware of.Second, it looks like the Xen Orchestra half of the RPU implementation lives here on GitHub. In my case, the error was reported from inside the
host.assert_can_evacuateAPI call that's implemented here inside the xen-api repo.I don't know OCaml and haven't really grappled with the source code there in detail, but I believe what's happening is that the server is checking that each individual host can be evacuated, but only treating them individually — not taking into account the fact that VMs will be moving from one host to another as the evacuation proceeds in practice.
In my particular case, the logging seems to be saying that this analysis was failing because, as things currently stood, when it would come time to reboot my big-memory machine (mpcxenbackup9), there wouldn't be room to hold its VMs on the other hosts, treating the current VM layout as a given. It has two 64 GB VMs, and only one of the other hosts (the one with >50% memory free) can fit one.
This would be consistent, I think, with other failure modes I've experienced, where the RPU starts and gets partway done, but fails with a not-enough-memory error. In those cases, I think that the assert_can_evacuate checks are passing, but as the VMs reshuffle during the migration, it becomes impossible to migrate a large-memory VM.
I think the solution would be that the planning and execution algorithm needs to be smarter and understand how VMs will move around over the course of the migration; plus I think it has weaknesses in deciding where to send VMs during the process. My system has five 64 GB VMs, which a smart enough packing algorithm should be able to fit at all times no matter which host is offline. But if the algorithm just assigns each VM to the first host that will fit it (in some broad sense), it can get itself wedged later in the process.
(FWIW, my intuition is that, if you only think worry about memory, there will always be a successful plan that migrates VMs a minimal number of times, but that might not be correct. Factoring in other constraints like SRs and networks, you probably need to try a bunch of different solutions with randomization to have higher confidence in finding a fully working migration plan.)
-
Rolling Pool Update fails with HOST_NOT_ENOUGH_FREE_MEMORY, when it really ought to be fine
I've had problems on and off with the RPU (Rolling Pool Update) feature for a while now. Usually, it mostly works for me, but runs into a problem figuring out how to move my VMs around and ends up quitting in the middle. Often this has to do with available memory.
With one of my pools right now, if I launch the RPU it instantly fails with an error like this:
CANNOT_EVACUATE_HOST(HOST_NOT_ENOUGH_FREE_MEMORY,OpaqueRef:...)Here's a screenshot of the pool host summary, where the horizontal bars show the RAM usage:
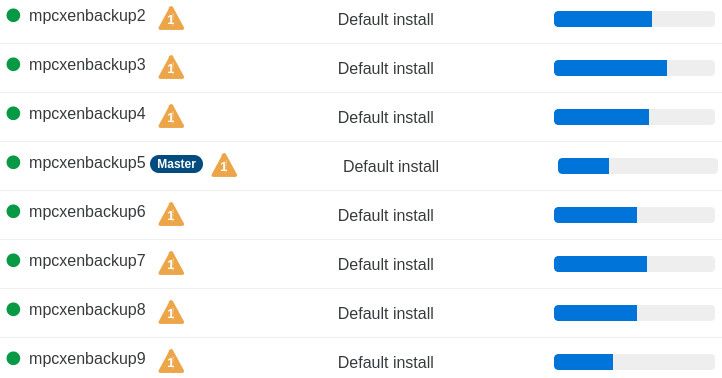
The first 7 hosts have 128 GB RAM but the last host is a big box with 1 TB RAM total, and 650 GB of RAM free. This pool hosts a set of VMs that use 64 GB of memory, so they are hard to fit on the smaller hosts, but they could all easily fit on the big host at once. We're not using dynamic memory or any host affinities.
So it really seems to me like the RPU algorithm should be able to figure out how to make this work. Are there any settings I can adjust that might help here? Are there surprising constraints that the algorithm applies that might explain why it's failing here?
(Semi-side note: often when an RPU fails, I do updates manually with
xe host-evacuate, and that command seems to work fine when the RPU algorithm fails.) -
RE: Second (and final) Release Candidate for QCOW2 image format support
@bogikornel I've also found that the I/O performance is somewhat lower in general.
Some of my profiling made it seem like the VHD backends were doing their low-level I/O with much bigger blocks than QCOW2 ... would that depend on the cluster size?
-
RE: Second (and final) Release Candidate for QCOW2 image format support
@stormi That is quite possible. I'll open a ticket for further investigation.
-
RE: Second (and final) Release Candidate for QCOW2 image format support
After upgrading from the QCOW2 beta to this set of packages, I'm running into a pretty severe bug: my QCOW2 disks still exist and are available, but have largely disappeared from the XO UI and many of the lower-level tools.
In the XO5 storage UI, the disks appear, but their names and descriptions are lost, and even though they are currently attached to running VMs, the system doesn't recognize this:
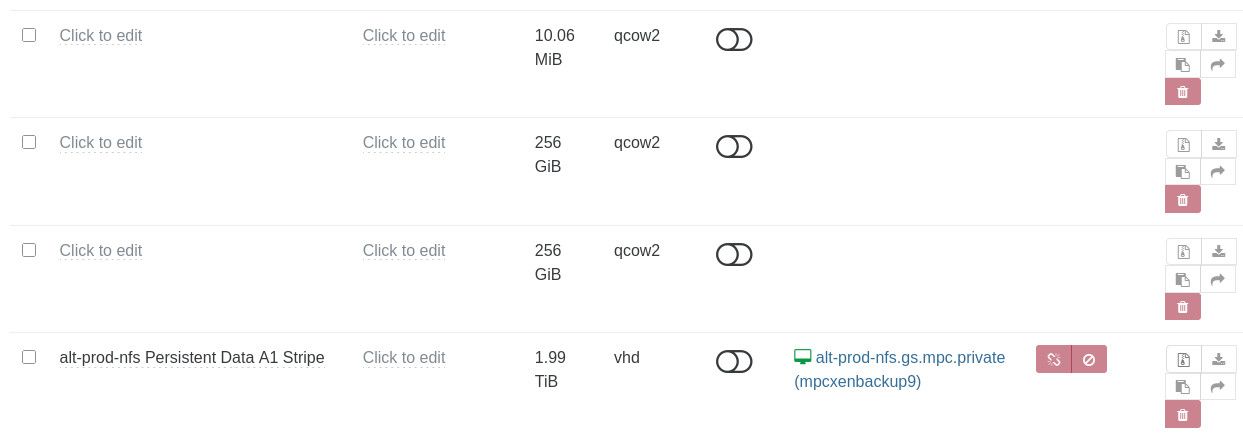
If I try to assign a new name to one of the VDIs as an experiment, I get a "VDI does not exist" error, even though
xe vdi-listdoes show all of these VDIs.On the other hand, I have running VMs where QCOW2 VDIs are attached and mounted, but the
xe vm-disk-listcommand doesn't show them.I see that there's a new batch of updates from a few days ago — any chance they will address this?
-
RE: Rolling pool update failure: not enough PCPUs even though all should fit (dom0 culprit?)
Of course, just after posting, I think I figured out what's happening.
It looks like the relevant parameter isn't the current number of allowed vCPUs set via the UI (
VCPUs-number), but the maximum number of vCPUs (VCPUs-max). One of the VMs in my cluster hadVCPUs-max = 16. After powering it off, I could reduce this number, and now the RPU appears to be proceeding. -
Rolling pool update failure: not enough PCPUs even though all should fit (dom0 culprit?)
Hi,
I have a small test VM cluster that I'm trying to apply a rolling pool update to. There are three physical hosts, with 32, 32, and 12 CPUs, respectively. When I try to initiate the update, it insta-fails with the error:
"CANNOT_EVACUATE_HOST(HOST_NOT_ENOUGH_PCPUS,16,12)"My understanding is that this means that the updater needs to move a VM requiring 16 vCPUs onto the machine with 12 pCPUs.
The mystery is that none of my VMs need nearly that many CPUs! I've dialed them all down to 2 vCPUs, and the error message is the same.
Looking at the
xe vm-listoutput, I do see that two of theControl domain on host: ...VMs do want 16 vCPUs. Are those potentially the culprit, here? What would be the recommended way to dial down their CPU allocations? I've seen some messages about using thehost-cpu-tunecommand and I could try playing around withxe, but I'm a little hesitant to fiddle around with these parts of the infrastructure without really knowing what I'm doing. -
RE: Migrating an offline VM disk between two local SRs is slow
@olivierlambert This is all offline. Unfortunately I can't describe exactly what was done, since someone else was doing the work and they were trying a bunch of different things all in a row. I suspect that the apparently fast migration is a red herring (maybe a previous attempt left a copy of the disk on the destination SR, and the system noticed that and avoided the actual I/O?) but if there turned out to be a magical fast path, I wouldn't complain!