Normally, the job should have been finished hours ago, all of the CR jobs start at 2am and are mostly finished within an hour.
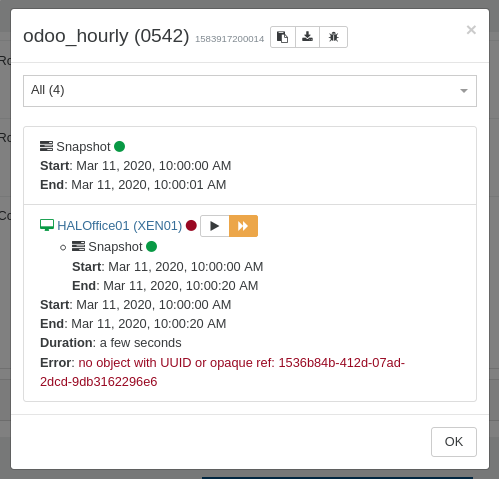
But this time, only half of the vms were backed up 7 hours later, restarting the 'hanging' CR job for this particular vm finished successfull within minutes.
But you could be right, the job status switched from running to interrupted after restarting xo-server.
The relevant portion of the logs:
{
"data": {
"mode": "delta",
"reportWhen": "failure"
},
"id": "1582160400010",
"jobId": "fd08162c-228a-4c49-908e-de3085f75e46",
"jobName": "cr_daily",
"message": "backup",
"scheduleId": "cf34b5ae-cab6-41fa-88ed-9244c25a780e",
"start": 1582160400010,
"status": "interrupted",
"infos": [
{
"data": {
"vms": [
"07927416-9ba4-ca82-e2ab-c14abe7a296d",
"e6ea3663-f7ab-78fd-db68-6e832120548a",
"3c0ee137-bbec-9691-d7d6-2a88383bca22",
"d627892d-661c-9b7c-f733-8f52da7325e2",
"ef1f5b2f-760c-da9f-b65f-6957d9be0dc9",
"8100cda5-99c1-38c3-9aaf-97675e836fef",
"30774025-8013-08ec-02a5-5f1bb1562072",
"e809d9db-4bb2-4b62-d099-549608f05aef",
"351edde8-1296-b740-b62b-264c6d0e7917",
"a05534ee-50fd-bc25-302f-a9ca86a2fa6b",
"be59cb1e-e78d-05ac-20e7-e9aac2f1c277",
"6b74df0a-f1ff-44ef-94ac-f2b9fafe6013",
"3f6974ef-cc56-668b-bd58-52a8a137cf86",
"df3f4b56-e10a-b998-ddc2-3e0bd3b32393",
"8c297add-cea0-bef0-a269-31414244940a",
"4b5594f4-5998-ceac-9ed6-4869857e623d",
"1e223aff-e5c6-64b7-031b-44a7d495cc6a",
"1df2dcd4-e532-156a-722b-d5a35dd58ce6",
"b2e89468-63a4-24d9-8e8b-497331b643a3",
"55372728-8138-a381-94e8-65b1e07b0005",
"30ecaf41-db76-a75a-d5df-63e8e6d34951",
"97797f4a-1431-8f3a-c3e6-ff9b30ebac3e",
"7a369593-6a26-e227-920e-4bc44ebbd851",
"430ce5f3-ad52-943e-aa93-fc787c1542a9",
"b6b63fab-bd5f-8640-305d-3565361b213f",
"098c0250-7b22-0226-ada5-b848070055a7",
"f6286af9-d853-7143-2783-3a0e54f32784",
"703bca46-519a-f55c-7098-cb3b5c557091",
"42f050df-10b0-8d7f-1669-995e4354656f",
"6485c710-8131-a731-adb4-59e84d5f7747",
"ecb1e319-b1a6-7c47-c00f-dcec90b6d07d",
"8b7ecafc-0206-aa1a-f96b-0a104c46d9c5",
"9640eda5-484d-aa25-31d6-47adcb494c27",
"aa23f276-dc7b-263d-49ea-97d896644824"
]
},
"message": "vms"
}
],
"tasks": [
[stripped successful backups]
{
"data": {
"type": "VM",
"id": "6b74df0a-f1ff-44ef-94ac-f2b9fafe6013"
},
"id": "1582161536243:0",
"message": "Starting backup of HALJenkins01. (fd08162c-228a-4c49-908e-de3085f75e46)",
"start": 1582161536243,
"status": "interrupted",
"tasks": [
{
"id": "1582161536246",
"message": "snapshot",
"start": 1582161536246,
"status": "success",
"end": 1582161541834,
"result": "0df8d2a3-7811-49fe-baa0-5be4fec7a212"
},
{
"id": "1582161541836",
"message": "add metadata to snapshot",
"start": 1582161541836,
"status": "success",
"end": 1582161541845
},
{
"id": "1582161557882",
"message": "waiting for uptodate snapshot record",
"start": 1582161557882,
"status": "success",
"end": 1582161558090
},
{
"id": "1582161558098",
"message": "start snapshot export",
"start": 1582161558098,
"status": "success",
"end": 1582161558099
},
{
"data": {
"id": "ea4f9bd7-ccae-7a1f-c981-217565c8e08e",
"isFull": false,
"type": "SR"
},
"id": "1582161558099:0",
"message": "export",
"start": 1582161558099,
"status": "interrupted",
"tasks": [
{
"id": "1582161558117",
"message": "transfer",
"start": 1582161558117,
"status": "interrupted"
}
]
}
]
}
]
}
The VM was still running and usable at this time, also the SR for our CR backups did not show any problems.
I will check the jobs tomorrow morning to see if this happened again and maybe could be related to the latest upgrade. On previous version 5.41 we did not encounter any 'hanging' backupjobs.