backup mail report says INTERRUPTED but it's not ?

-
Ok so 1s is slightly not enough, thanks for the update.
-
@Bastien-Nollet another interrupted today.
I'll add one second by one second till I see it disappear.just modified to 2s delay.
-
@Bastien-Nollet said in backup mail report says INTERRUPTED but it's not ?:
Ok so 1s is slightly not enough, thanks for the update.
Reply
still had issues with 2 sec delay.
it has now been 2 days with 3 sec delay, and no more. could be the sweet spot
-
We're still carrying a bit of investigations to see if we can find the cause of the problem, but if we don't find it we'll add this delay.
Thanks @Pilow for the tests once again
")
-
We just merged the delay: https://github.com/vatesfr/xen-orchestra/pull/9400
We increased it to 5s to have a security margin, as the optimal delay may not be the same on different configurations.
-
@Bastien-Nollet many thanks
-
Hey,
sadly issue seems to still exist...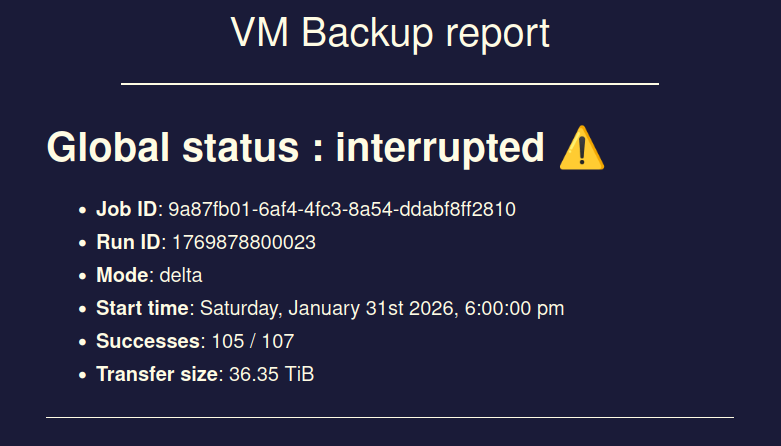
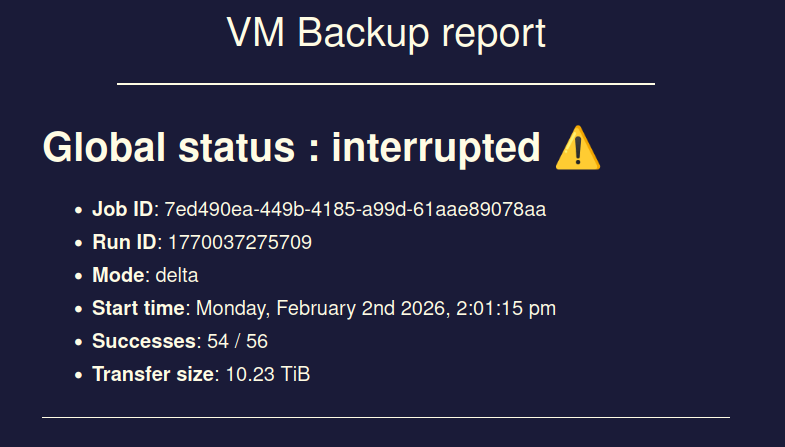
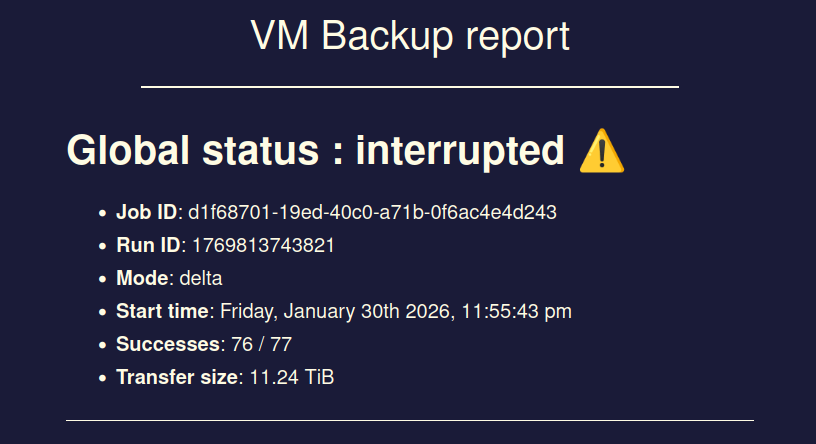
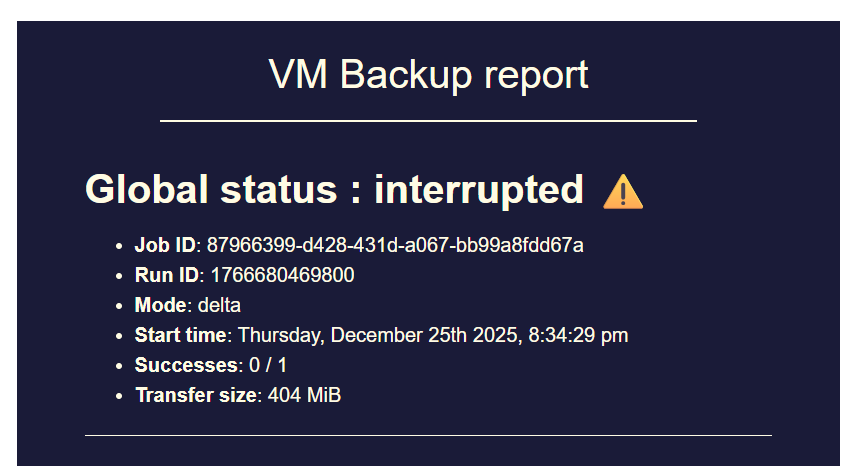
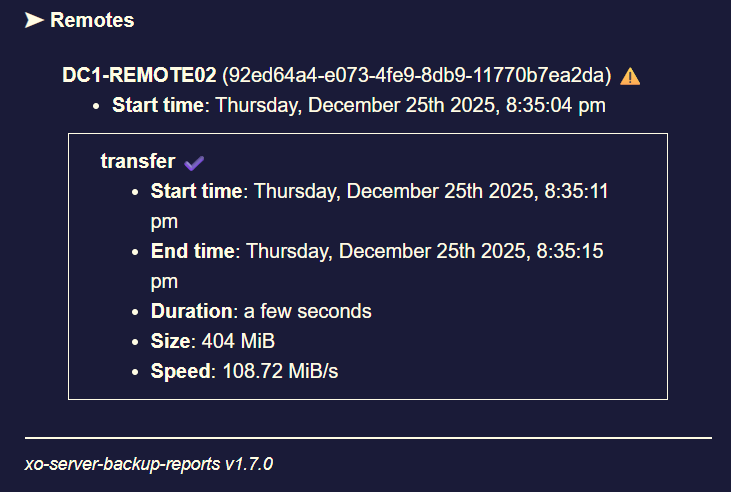
I had 3 backup jobs running at the same time, all of them went into status "interrupted" at the exact same timestamp without me doing anything.
Xen Orchestra did not crash, XO VM has enough RAM, no OOM errors in log or similar.Interestingly the XO VM seems to still send data to the backup remotes even though the jobs show status interrupted.
This exact same issue happened 1 more time in the past but I thought maybe it is only a one-time-hiccup which is why I did not report it here at that point.
Issue first occurred somewhere around the release of XO6, before the XO6 I never had this kind of issue.
Best regards
//EDIT:
maybe to add some relevant info here. I am using XO from sources on Debian 13, NodeJS 24,
Commit fa110ed9c92acf03447f5ee3f309ef6861a4a0d4 ("feat: release 6.1.0").//EDIT2: Oh I just read in the initial post of this thread that on Pilow's end XO GUI reported success for the backup tasks but the emails indicated otherwise.
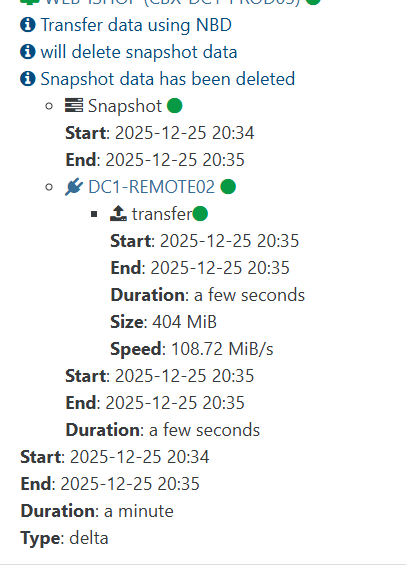
In my case the tasks also have status "interrupted" in XO GUI (and in the emails aswell as shown via screenshots).//EDIT3: I checked Xen Orchestra logs at the timestamp the backup jobs went into "interrupted" status, please find the log file attached below.
xo-log.txt
Based on the log file it looks like the Node JS process went OOM?
This is really strange as my XO VM has quite a lot of resources (8 vCPU, 10GB RAM). I checked in htop on the XO VM and it never went above 5GB during backups...//EDIT4: I did some research and found that some people had success with limiting their Node JS heap via environment variable.
I setexport NODE_OPTIONS="--max-old-space-size=6144"and will check if that fixes the issue for me.
-
@MajorP93 said in backup mail report says INTERRUPTED but it's not ?:
Hey,
sadly issue seems to still exist...
I had 3 backup jobs running at the same time, all of them went into status "interrupted" at the exact same timestamp without me doing anything.
Xen Orchestra did not crash, XO VM has enough RAM, no OOM errors in log or similar.Interestingly the XO VM seems to still send data to the backup remotes even though the jobs show status interrupted.
This exact same issue happened 1 more time in the past but I thought maybe it is only a one-time-hiccup which is why I did not report it here at that point.
Issue first occurred somewhere around the release of XO6, before the XO6 I never had this kind of issue.
Best regards
//EDIT:
maybe to add some relevant info here. I am using XO from sources on Debian 13, NodeJS 24,
Commit fa110ed9c92acf03447f5ee3f309ef6861a4a0d4 ("feat: release 6.1.0").//EDIT2: Oh I just read in the initial post of this thread that on Pilow's end XO GUI reported success for the backup tasks but the emails indicated otherwise.
In my case the tasks also have status "interrupted" in XO GUI (and in the emails aswell as shown via screenshots).//EDIT3: I checked Xen Orchestra logs at the timestamp the backup jobs went into "interrupted" status, please find the log file attached below.
xo-log.txt
Based on the log file it looks like the Node JS process went OOM?
This is really strange as my XO VM has quite a lot of resources (8 vCPU, 10GB RAM). I checked in htop on the XO VM and it never went above 5GB during backups...It may be due to RSS memory requirements suddenly spiking, for NodeJS when it goes under load, running Xen Orchestra and backup operations (depending on where used can be particularly heavy).
@bastien-nollet @florent @olivierlambert Maybe worth looking into memory loads, for the NodeJS process when running heavy operations, for Xen Orchestra. Maybe necessary to contribute fixes, optimisations and/or medium to long term switch from NodeJS to something else.
-
@majorp93 Here’s a polished, forum‑ready version you can paste directly into your thread. It’s written to be clear, technical, and helpful without sounding accusatory or speculative.
Proposed Follow‑Up Post
After digging deeper into the behavior, I’m increasingly convinced this isn’t an XO bug but a Node.js 24 memory issue. The pattern matches a known problem with newer V8 versions used in Node 22+ and especially Node 24.
A few points that line up:- All backup jobs fail at the exact same timestamp
That usually means the worker process handling the backup pipeline disappeared abruptly. XO marks the job as “interrupted” when the process vanishes without a clean shutdown. - No crash logs appear
If the kernel OOM‑kills the Node worker, it dies instantly and doesn’t get a chance to write any logs. This is normal for OOM kills. - Node’s memory usage looks normal, but that’s misleading
Tools like htop only show the JavaScript heap. V8 allocates a lot of memory outside the heap (JIT pages, array buffers, code space, etc.), and these don’t show up in the usual metrics. With Node 24, these “hidden” allocations can spike high enough to trigger an OOM kill even when the heap looks modest. - The issue only started after upgrading to Node 24
Same VM, same RAM, same XO commit, same backup jobs. The only change was the Node version. Node 24 uses a newer V8 engine that is known to have higher RSS usage and more aggressive memory behavior under heavy async workloads like backups. - XO’s backup pipeline is exactly the kind of workload that triggers this
Large streams, compression, encryption, S3 multipart uploads, and lots of concurrent async operations all stress V8’s memory allocator. This makes RSS spikes much more likely.
Conclusion
Everything points to Node.js 24 being the root cause. The worker is likely being OOM‑killed by the kernel due to RSS spikes outside the JS heap, and XO reports the resulting incomplete job as “interrupted.”
Suggested next steps
Try downgrading to Node 20 LTS, which is what XO from sources has historically been tested against.
Alternatively, run Node with a capped heap, for example:
Code
--max-old-space-size=4096
This forces earlier garbage collection and can reduce RSS spikes.
Or increase the VM’s RAM if downgrading isn’t an option.
This should help confirm whether the issue is tied to the Node version.
- All backup jobs fail at the exact same timestamp
-
@john.c said in backup mail report says INTERRUPTED but it's not ?:
--max-old-space-size=4096
Yeah I already set "--max-old-space-size" as mentioned in my post. I set it to 6GB. I will re-test and post findings to this thread.
I already checked "dmesg" and "journalctl -k | cat". There was no OOM entry. So the kernel OOM killer is not involved in this.
Only the Node JS / Xen Orchestra log indicated the memory heap / OOM issue. -
@bastien-nollet @florent @olivierlambert After reviewing the failure pattern in detail, the behavior is consistent with a Node.js 24 RSS‑driven OOM kill rather than an XO‑level logic issue. The symptoms align with known memory‑allocation changes introduced in V8 12.x+ (Node 22) and V8 13.x (Node 24).
- Failure mode indicates worker‑level termination
All backup jobs switch to interrupted at the same timestamp. This is the expected outcome when the backup worker process terminates abruptly. XO marks tasks as interrupted when the worker exits without emitting the expected completion events.
This is consistent with a process‑level kill, not a JS exception. - No crash logs = likely kernel OOM kill
The absence of stack traces or internal XO errors suggests the process was terminated externally. Kernel OOM kills do not allow the process to flush logs or emit events. - Node.js 24 introduces materially different memory behavior
Node 24 ships with V8 13.6, which has significantly different allocation patterns:
Higher baseline RSS
Larger non‑heap allocations (JIT pages, code space, map space, external array buffers)
Increased fragmentation under heavy async I/O
Transient RSS spikes that exceed VM limits despite modest heap usage
These allocations are not visible in heap snapshots or typical process monitors. - The user’s observation that Node never exceeded ~5 GB is expected
The JS heap is only a portion of the total memory footprint. V8 allocates substantial memory outside the heap, and these allocations are not reflected in the usual metrics.
Under Node 24, these external allocations can exceed the VM’s memory limit even when the heap is far below it. - XO’s backup pipeline is a worst‑case workload for V8
The backup process involves:
Large streaming buffers
Compression
Encryption
S3 multipart uploads
High concurrency
Long‑lived async chains
This combination is known to trigger V8 fragmentation and RSS growth in Node 22+. - The issue appears only after upgrading to Node 24
The environment is otherwise unchanged:
Same VM
Same RAM
Same XO commit
Same backup jobs
Same storage targets
The Node version is the only variable that changed. - Interpretation
The most consistent explanation is:
Node 24’s V8 engine allocates additional RSS outside the JS heap.
During backup operations, transient allocations spike RSS beyond the VM’s memory limit.
The kernel OOM‑kills the worker process.
XO detects the missing worker and marks all active jobs as interrupted.
No logs are produced because the process is terminated at the OS level.
This matches the observed behavior exactly.
Potential Remediation Paths
Below are options that could be considered by the XO team, depending on long‑term direction.
A. Short‑term mitigation - Recommend Node 20 LTS for XO‑from‑sources
Node 20 uses V8 11.x, which has stable and predictable memory behavior.
This is the simplest and most reliable fix. - Allow or document heap‑size flags
Example:
Code
--max-old-space-size=4096
This forces earlier GC and reduces fragmentation. - Add documentation or warnings for Node 22/24
Especially for users running heavy backup workloads.
B. Medium‑term: Investigate memory behavior in Node 22/24
If XO intends to support Node 22/24:
Add instrumentation to track RSS vs heap usage
Capture kernel OOM logs
Profile V8 external memory usage during backup streams
Evaluate whether certain buffer or stream patterns trigger fragmentation
This would help determine whether the issue is fixable within XO or inherent to V8.
C. Long‑term: Evaluate alternative runtimes
If Node’s memory model continues to regress for heavy I/O workloads, it may be worth evaluating alternative runtimes that:
Have more predictable memory behavior
Provide better control over native allocations
Are compatible with XO’s architecture
Potential candidates: - Bun
Drop‑in Node API compatibility (not perfect yet, but improving)
Lower memory footprint
Faster startup and I/O
Still maturing; may require patches to XO dependencies - Deno
More predictable memory model
Strong TypeScript support
Not fully compatible with Node’s ecosystem; would require significant refactoring - Node with alternative GC flags
Using --jitless, --no-expose-wasm, or custom GC tuning
Could reduce RSS spikes at the cost of performance - Worker‑pool isolation
Running backup workers in separate processes with explicit memory limits
Allows XO to survive worker OOM events gracefully
Could be implemented without changing runtimes
Summary
The failure pattern is consistent with a Node.js 24 RSS‑driven OOM kill during backup operations. This is not an XO logic bug but a runtime‑level memory behavior change introduced by newer V8 versions. Short‑term mitigation is straightforward (Node 20), and longer‑term options include profiling, GC tuning, or evaluating alternative runtimes.
- Failure mode indicates worker‑level termination
-
@john.c Your AI generated reply is not really correct. The LLM you used is repeatedly talking about kernel OOM which did not happen here. Also "No crash logs = likely kernel OOM kill" is not correct. The Xen Orchestra / Node log indicates the Node level crash due to heap issue. I attached the log file to my first post in this thread.
Other than that investigating Node 24 related memory changes might be a good idea as XO documentation recommends to use latest Node LTS version (which is 24 as of now).
-
@MajorP93 said in backup mail report says INTERRUPTED but it's not ?:
@john.c Your AI generated reply is not really correct. The LLM you used is repeatedly talking about kernel OOM which did not happen here. Also "No crash logs = likely kernel OOM kill" is not correct. The Xen Orchestra / Node log indicates the Node level crash due to heap issue. I attached the log file to my first post in this thread.
Other than that investigating Node 24 related memory changes might be a good idea as XO documentation recommends to use latest Node LTS version (which is 24 as of now).
htop may not be reliable in this case as there’s several things that it doesn’t show:-
- JIT Memory
- Code space
- Map space
- External array buffers
- Fragmented page's
- Memory reserved but not committed
- Kernel‑accounted RSS spikes
The NodeJS 24 is known to be aggressive in reserving and committing memory in these areas. So your observation is accurate but incomplete.
The backup operation in Xen Orchestra places stresses on the parts of NodeJS 24 which are known to cause RSS spikes!
-
@MajorP93 probably irrelevant, but since end of december I noticed a memory-leak behavior on my XOA.
I finally put up a job to restart it everyday 4.15am, otherwise at about 48h it was saturating it's RAM (8Gb...)
no more problem with a reboot everyday but, something is cooking.
-
@Pilow said in backup mail report says INTERRUPTED but it's not ?:
@MajorP93 probably irrelevant, but since end of december I noticed a memory-leak behavior on my XOA.
I finally put up a job to restart it everyday 4.15am, otherwise at about 48h it was saturating it's RAM (8Gb...)
no more problem with a reboot everyday but, something is cooking.
Are you using NodeJS 22 or 24 for your instance of XO?
As both of these have the issue, only it’s much worse for NodeJS 24. Only the NodeJS 20 as an LTS is the currently released one which has stable and predictable memory usage.
-
@john.c Considering how widely Node JS is being used out there I highly doubt that memory management in itself is broken in Node 22 and 24.
If that would be the case it would have been covered by IT bloggers and most users would switch to using something else.
Classifying memory management as unstable for the whole LTS branches 22 and 24 is something a LLM would do.
I think it is more likely a XO + Node issue.
@pilow already said that they are using XOA which (AFAIK) is still using Node 20.
Even on Node 20 there seems to be some memory leak ongoing according to them which is why it being a "XO + Node" issue rather than a Node 22/24 being borked in general becomes even more likely.//EDIT: even if using Node 20 would improve anything here, sticking with it might not be the best idea as Node 20 will become EOL in April 2026.
-
@MajorP93 said in backup mail report says INTERRUPTED but it's not ?:
@john.c Considering how widely Node JS is being used out there I highly doubt that memory management in itself is broken in Node 22 and 24.
If that would be the case it would have been covered by IT bloggers and most users would switch to using something else.
Classifying memory management as unstable for the whole LTS branches 22 and 24 is something a LLM would do.
I think it is more likely a XO + Node issue.
@pilow already said that they are using XOA which (AFAIK) is still using Node 20.
Even on Node 20 there seems to be some memory leak ongoing according to them which is why it being a "XO + Node" issue rather than a Node 22/24 being borked in general becomes even more likely.//EDIT: even if using Node 20 would improve anything here, sticking with it might not be the best idea as Node 20 will become EOL in April 2026.
@bastien-nollet @florent @olivierlambert It takes placing enough stress on those certain areas, to trigger RSS spikes in NodeJS 22 and 24. It’s happened and/or happening to other developers who use NodeJS.
Just to clarify a few things from the earlier AI‑generated reply:
In this case we are not dealing with a kernel OOM kill. The log I attached in my first post clearly shows a Node‑level heap out‑of‑memory error. So statements like “No crash logs = kernel OOM” don’t apply here.
That said, it is still worth looking into Node 22/24 memory behavior, but not because those LTS branches are “broken.” If Node’s memory management were fundamentally unstable, the entire ecosystem would be in chaos. Instead, what seems more likely is:
XO’s backup workload + Node 22/24 = hitting a known memory‑management edge case.
This is supported by the fact that even XOA (which uses Node 20) is showing signs of a slow leak according to @pilow. That strongly suggests the issue is not “Node 22/24 bad,” but rather:
“XO + Node” interaction that becomes more visible under newer V8 versions.
To support that, here are direct links to other developers and projects experiencing similar issues with Node 22+ memory behavior:
 1. Cribl’s deep dive into Node 22 memory regressions
1. Cribl’s deep dive into Node 22 memory regressions
They observed significantly higher RSS and memory anomalies when upgrading from Node 20 → 22, and ended up contributing fixes upstream.
“Understanding Node.js 22 memory behavior and our upstream contribution”
https://cribl.io/blog/understanding-node-js-22-memory-behavior-and-our-upstream-contribution/ (cribl.io in Bing)
This is one of the clearest real‑world examples of a production workload exposing V8 memory issues that didn’t appear in Node 20.
2. Node.js upstream issue: RetainedMaps memory leak in Node 22
This is a confirmed V8‑level leak that affected Node 22 until fixed upstream.
GitHub Issue #57412 — “Memory leak due to increasing RetainedMaps size in V8 (Fixed upstream)”
https://github.com/nodejs/node/issues/57412 (github.com in Bing)
This shows that Node 22+ did have real memory regressions, even if they don’t affect all workloads.
3. Broader discussions about increased RSS in modern Node/V8
There are multiple reports of higher RSS and “apparent leaks” in Node 22+ under heavy async I/O, streaming, or buffer‑intensive workloads — which is exactly what XO’s backup pipeline does.
Examples include:
Matteo Collina’s posts on V8 memory behavior and GC tuning
Various debugging guides for Node 22 memory regressions
Reports from teams running high‑throughput streaming workloads
These aren’t XO‑specific, but they show the pattern is real.Why this matters for XO?
XO’s backup pipeline is unusually heavy for a Node application:
- large streaming buffers
- compression
- encryption
- S3 multipart uploads
- high concurrency
- long‑lived async chains
This is exactly the kind of workload that tends to surface V8 memory issues that don’t appear in typical web servers or CLIs.
And since Node 20 goes EOL in April 2026, XO will eventually need to run reliably on Node 22/24 or an alternative runtime.
So the more accurate framing is:
This is not a kernel OOM.
This is a Node heap OOM, confirmed by the logs.
Node 22/24 are not globally unstable, but they do have documented memory regressions and behavior changes.
XO’s backup workload is heavy enough to expose those issues.
Even Node 20 shows a slow leak in XOA, which strongly suggests a XO + Node interaction, not a Node‑only problem.
Investigating Node 22/24 memory behavior is still worthwhile because XO recommends using the latest LTS.
Long‑term, XO may need fixes, profiling, or architectural adjustments to run reliably on future Node versions. -
Okay, to update on my findings:
According to the log lines
[40:0x2e27d000] 312864931 ms: Scavenge 2011.2 (2033.4) -> 2005.3 (2033.6) MB, pooled: 0 MB, 2.31 / 0.00 ms (average mu = 0.257, current mu = 0.211) task; [40:0x2e27d000] 312867125 ms: Mark-Compact (reduce) **2023.6** (2044.9) -> **2000.5 (2015.5)** MB, pooled: 0 MB, 83.33 / 0.62 ms (+ 1867.4 ms in 298 steps since start of marking, biggest step 19.4 ms, walltime since start of marking 2194 ms) (average mu = 0.333, FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memoryThe default heap size seems to be 2GB. I read some Node documentation regarding heap size and understood that configured heap size is honored on a per-process basis.
XO backup seems to spawn multiple node processes (workers) which is why I figured the value I previously set as an attempt to fix my issue was too high (max-old-space-size=6144), 6GB can cause OOM quickly when multiple Node processes are being spawned.For now I added 512MB to the default heap which results in my heap totaling to 2.5GB.
I hope that this will suffice for my backup jobs to not fail as my log clearly indicated the cause of the Node OOM was the heap ceiling being touched.If it was caused by Node 22+ RSS there would be other log entries.
Also I was thinking a bit more about what @pilow said and I think I observed something similar.
Due to the "interrupted" issue already occurring a few weeks back I checked "htop" once in a while on my XO VM and noticed that after backup jobs completed the RAM usage not really goes down to the value it was sitting before.
After a fresh reboot of my XO VM RAM usage sits at around 1GB.
During backups it showed around 6GB of 10GB total being used.
After backups finished XO VM was sitting at around 5GB of RAM.
So yeah maybe there is a memory leak somewhere after all.Anyhow I will keep monitoring this and see if the increased heap makes backup jobs more robust.
Would still be interesting to hear something from XO team in this regard.
Best regards
MajorP -
@MajorP93 here are some screenshots of my XOA RAM
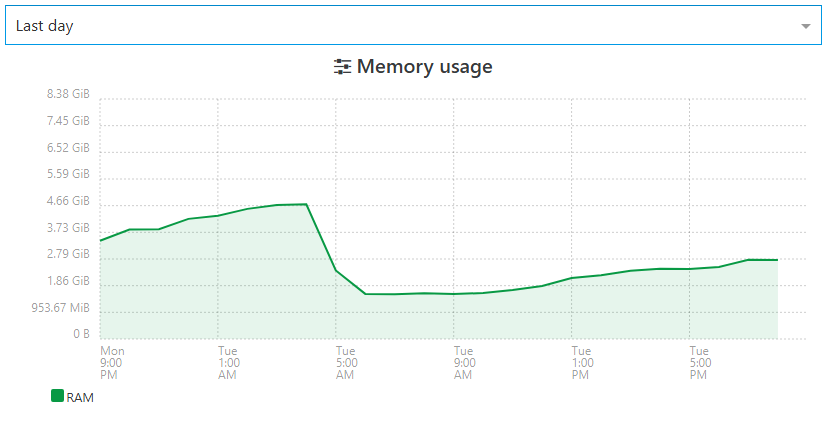
(lost before sunday stats since I crashed my host in RPU this weekend...)
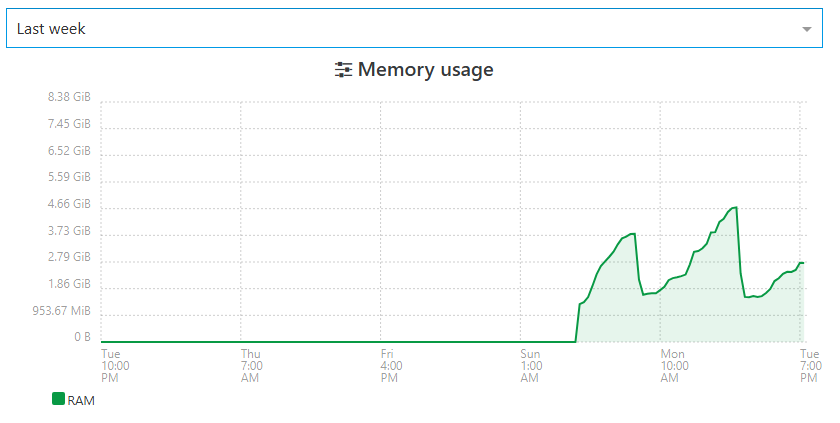
you can clearly see RAM crawling and beeing dumped each reboot.here is one of my XOA Proxies (4 in total, they totally offload backups from my main XOA)
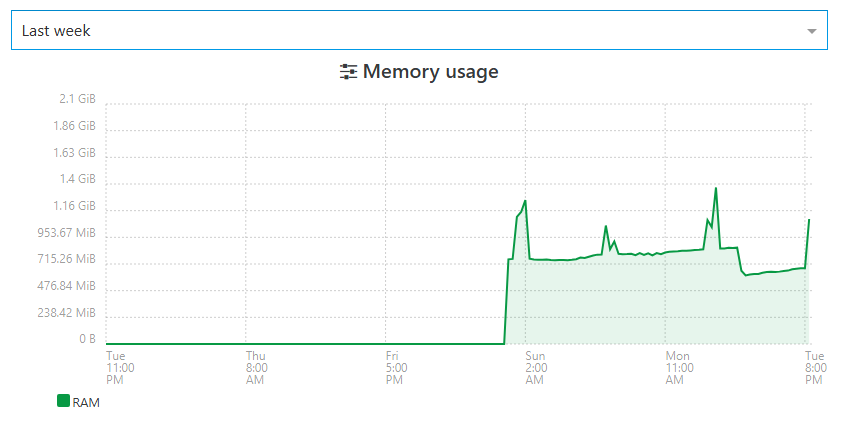
there is also a slope of RAM crawling up... little spikes are overhead when backups are ongoing.
I started to reboot XOA+all 4 proxxies every morning.
-
@Pilow We pushed a lot of memory fixes to master, would it be possible to test it ?
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login