Delta backup fails for specific vm with VDI chain error
-
Yes, it's logical:
7ef76is the active disk, and it should be merged in8e77, then this last one should be merged in4345 -
But that never seems to happen. It's always just merging the little VHD in the middle:
Aug 28 10:00:22 rigel SMGC: [11997] SR f951 ('rigel: sr') (26 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 28 10:00:22 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 28 10:00:22 rigel SMGC: [11997] *3378a834[VHD](500.000G//1.520G|ao) Aug 28 10:00:22 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 28 10:00:22 rigel SMGC: [11997] Aug 28 10:00:22 rigel SMGC: [11997] Coalescing parent *3378a834[VHD](500.000G//1.520G|ao)├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ customer server 2017 0 - 3378a834-77d3-48e7-8532-ec107add3315 - 1.52 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiRight before this timestamp and probably just by chance I got this:
├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiBut still....
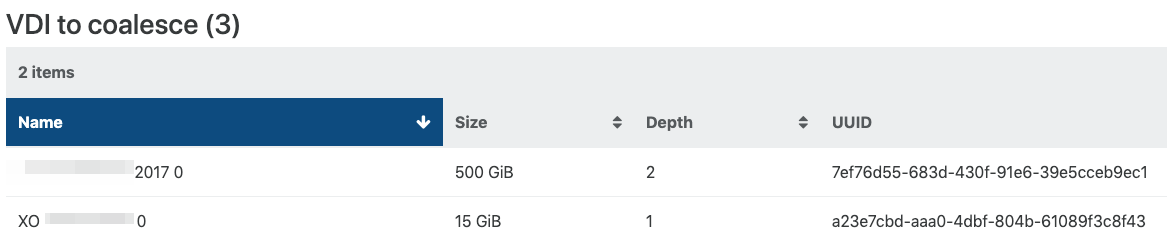
-
That's strange. The child is bigger than the parent. I wonder how it's possible but I forgot how the size is computed on LVM (I'm mainly using file backend).
You could try to do a
vhd-util repairon those disks. See https://support.citrix.com/article/CTX217757 -
The bigger number is equal to the configured virtual disk size.
The repair seems to work only if a disk is not in use - eq offline:
[10:24 rigel ~]# lvchange -ay /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 [10:26 rigel ~]# vhd-util repair -n /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 [10:27 rigel ~]# lvchange -an /dev/mapper/VG_XenStorage--f951f048--dfcb--8bab--8339--463e9c9b708c-VHD--7ef76d55--683d--430f--91e6--39e5cceb9ec1 Logical volume VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/VHD-7ef76d55-683d-430f-91e6-39e5cceb9ec1 in use. -
Have you tried:
- repair on both UUIDs in the chain?
- trying again when it's halted
-
I tried what I did last week: I made a copy.
So I had the VM with no snapshot in the state descibed in my last posts. I triggered a full copy with zstd compression to the other host in XO.
The system created a VM snapshot and is currently in the process of copying.
Meanwhile the gc did some stuff and now says
Aug 28 11:19:27 rigel SMGC: [11997] GC process exiting, no work left Aug 28 11:19:27 rigel SMGC: [11997] SR f951 ('rigel: sr') (25 VDIs in 9 VHD trees): no changesxapi-explore-sr says:
rigel: sr (25 VDIs) ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ ├── customer server 2017 0 - 16f83ba3-ef58-4ae0-9783-1399bb9dea51 - 0.01 Gi │ └─┬ customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 Gi │ └── customer server 2017 0 - 16f83ba3-ef58-4ae0-9783-1399bb9dea51 - 0.01 GiIs it okay for 16f83ba3 to appear twice?
The sr's advanced tab in XO is empty.
-
Sounds like the chain is fucked up in a way I never saw. But I'm not sure about what we see and what it's doing.
Ideally, can you reproduce this bug on a file level SR?
-
Hm.. I could move all vms on one host and add a couple of sas disks to the other, set up a file level sr and see how that's behaving. I just don't think I'll get it done this week.
P.S.: 16f83ba3 shows up only once in xapi-explore-sr, but twice in xapi-explore-sr --full
-
FYI, in the meantime the copy has finished, XO deleted the snapshot and now we're back at the start again:

xapi-explore-sr (--full doesn't work at the moment wit "maximum call stack size exceeded" error):
├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ └─┬ customer server 2017 0 - 57b0bec0-7491-472b-b9fe-e3a66d48e1b0 - 0.2 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 GiP.S.:
Whilst migrating:
Aug 28 13:45:33 rigel SMGC: [5663] No work, exiting Aug 28 13:45:33 rigel SMGC: [5663] GC process exiting, no work left Aug 28 13:45:33 rigel SMGC: [5663] SR f951 ('rigel: sr') (25 VDIs in 9 VHD trees): no changesSo, yeah, foobar
")
-
Migrated the vm to the other host, waited and watched the logs, etc.
The behaviour stays the same. It's constantly coalescing but never gets to an end. Depth in the advanced tab stays at 2.So I guess the next step will be to setup an additional ext3 sr.
P.S.:
You said "file level sr". So I could also use NFS, right?
Setting up NFS on the 10GE SSD NAS would indeed be easier than adding drives to a host... -
mbt,
That is the weirdest thing I have seen (and I think i hold the record of causing storage related problems 8-) ).
Look, I know this is going to sound weird, but try making a copy of the VM not by using the "copy" function. Create a disaster recovery backup job to copy the VM. The reason why I am suggesting this is because the it appears that XO creates a "stream" and effectively exports and imports the VM at the same time. I believe the copy function is handled very differently in XAPI. This should break all association between the old "borked" VDI and the new.
I would be really interested to see if that fixes the problem for you
~Peg
-
Hi Peg,
believe me, I'd rather not be after your record
Disaster recovery does not work for this vm: "Job canceled to protect the VDI chain"
My guess: as long as XO checks the VDI chain for potential problems before each VM's backup, no backup-ng mechanism will backup this vm. -
We have an option to force it, but this is a protection and that just display in plain sight your issue with this SR.
I still don't know the root cause, I think it will be hard to know more without accessing the host myself remotely and do a lot of digging.
-
I now have migrated the VM's disk to NFS.
xapi-explore-sr looks like this (--full not working most of the time):
NASa-sr (3 VDIs) └─┬ customer server 2017 0 - 6d1b49d2-51e1-4ad4-9a3b-95012e356aa3 - 500.94 Gi └─┬ customer server 2017 0 - f2def08c-cf2e-4a85-bed8-f90bd11dd585 - 43.05 Gi └── customer server 2017 0 - 9ad7e1c4-b7cb-4a1b-bb74-6395444da2b7 - 43.04 Gi
On the NFS it looks like this:
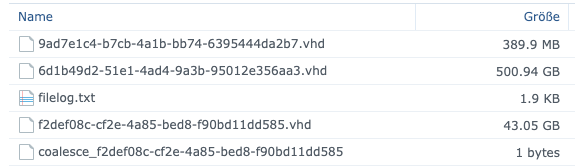
I'll wait a second for a coalesce job that is currently in progress...
OK, the job has finished. No VDIs to coalesce in the advanced tab.
NFS looks like this:
xapi-explore-sr --full says:
NASa-sr (1 VDIs) └── Customer server 2017 0 - 9ad7e1c4-b7cb-4a1b-bb74-6395444da2b7 - 43.04 Gi -
So coalesce is working as expected on the NFS SR. For some reason, your original LVM SR can't make a proper coalesce.
-
But only for this vm, all the others are running (and backupping) fine.
How are my chances that coalesce will work fine again if I migrate the disk back to local lvm sr? -
Try again now you got a clean chain
")
-
@olivierlambert Could this patch be the solution?
It would validate if this would really fix the problem.[XSO-887](https://bugs.xenserver.org/browse/XSO-887?focusedCommentId=17173&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel) -
This patch then:
--- /opt/xensource/sm/cleanup.py.orig 2018-08-17 17:19:16.947351689 +0200 +++ /opt/xensource/sm/cleanup.py 2018-10-05 09:30:15.689685864 +0200 @@ -1173,16 +1173,24 @@ def _doCoalesce(self): """LVHD parents must first be activated, inflated, and made writable""" + self.sr.lock() + acquired = True try: self._activateChain() self.sr.lvmCache.setReadonly(self.parent.fileName, False) self.parent.validate() + self.sr.unlock() + acquired = False self.inflateParentForCoalesce() VDI._doCoalesce(self) finally: + if acquired: + self.sr.unlock() self.parent._loadInfoSizeVHD() self.parent.deflate() + self.sr.lock() self.sr.lvmCache.setReadonly(self.parent.fileName, True) + self.sr.unlock() def _setParent(self, parent): self._activate() @@ -1724,33 +1732,41 @@ # need to finish relinking and/or refreshing the children Util.log("==> Coalesce apparently already done: skipping") else: - # JRN_COALESCE is used to check which VDI is being coalesced in - # order to decide whether to abort the coalesce. We remove the - # journal as soon as the VHD coalesce step is done, because we - # don't expect the rest of the process to take long - self.journaler.create(vdi.JRN_COALESCE, vdi.uuid, "1") - vdi._doCoalesce() - self.journaler.remove(vdi.JRN_COALESCE, vdi.uuid) + self.lock() + try: + # JRN_COALESCE is used to check which VDI is being coalesced in + # order to decide whether to abort the coalesce. We remove the + # journal as soon as the VHD coalesce step is done, because we + # don't expect the rest of the process to take long + self.journaler.create(vdi.JRN_COALESCE, vdi.uuid, "1") + finally: + self.unlock() - util.fistpoint.activate("LVHDRT_before_create_relink_journal",self.uuid) + vdi._doCoalesce() - # we now need to relink the children: lock the SR to prevent ops - # like SM.clone from manipulating the VDIs we'll be relinking and - # rescan the SR first in case the children changed since the last - # scan - self.journaler.create(vdi.JRN_RELINK, vdi.uuid, "1") + self.lock() + try: + self.journaler.remove(vdi.JRN_COALESCE, vdi.uuid) + util.fistpoint.activate("LVHDRT_before_create_relink_journal",self.uuid) + # we now need to relink the children: lock the SR to prevent ops + # like SM.clone from manipulating the VDIs we'll be relinking and + # rescan the SR first in case the children changed since the last + # scan + self.journaler.create(vdi.JRN_RELINK, vdi.uuid, "1") + finally: + self.unlock() self.lock() try: self.scan() vdi._relinkSkip() + + vdi.parent._reloadChildren(vdi) + self.journaler.remove(vdi.JRN_RELINK, vdi.uuid) + self.deleteVDI(vdi) finally: self.unlock() - vdi.parent._reloadChildren(vdi) - self.journaler.remove(vdi.JRN_RELINK, vdi.uuid) - self.deleteVDI(vdi) - def _coalesceLeaf(self, vdi): """Leaf-coalesce VDI vdi. Return true if we succeed, false if we cannot complete due to external changes, namely vdi_delete and vdi_snapshotWell, I haven't read it in details, you can try to see if it's easy to apply and then restart toolstack.
-
I migrated the disk back to the local lvm sr.
Guess what...

rigel: sr (25 VDIs) ├─┬ customer server 2017 0 - 972ef16c-8d47-43f9-866e-138a6a7693a8 - 500.98 Gi │ └─┬ customer server 2017 0 - 4e61f49f-6598-4ef8-8ffa-e496f2532d0f - 0.33 Gi │ └── customer server 2017 0 - 66ab0cf5-ff10-4a3d-9f87-62b1e7be7f91 - 500.98 Gi
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login