Backup jobs run twice after upgrade to 5.76.2
-
@tts Sounds like the backup job was still in the middle of the "merge" process when you stopped the service. You should investigate if your destination VM is intact or needs a full backup.
-
Normally, the job should have been finished hours ago, all of the CR jobs start at 2am and are mostly finished within an hour.
But this time, only half of the vms were backed up 7 hours later, restarting the 'hanging' CR job for this particular vm finished successfull within minutes.
But you could be right, the job status switched from running to interrupted after restarting xo-server.
The relevant portion of the logs:{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1582160400010", "jobId": "fd08162c-228a-4c49-908e-de3085f75e46", "jobName": "cr_daily", "message": "backup", "scheduleId": "cf34b5ae-cab6-41fa-88ed-9244c25a780e", "start": 1582160400010, "status": "interrupted", "infos": [ { "data": { "vms": [ "07927416-9ba4-ca82-e2ab-c14abe7a296d", "e6ea3663-f7ab-78fd-db68-6e832120548a", "3c0ee137-bbec-9691-d7d6-2a88383bca22", "d627892d-661c-9b7c-f733-8f52da7325e2", "ef1f5b2f-760c-da9f-b65f-6957d9be0dc9", "8100cda5-99c1-38c3-9aaf-97675e836fef", "30774025-8013-08ec-02a5-5f1bb1562072", "e809d9db-4bb2-4b62-d099-549608f05aef", "351edde8-1296-b740-b62b-264c6d0e7917", "a05534ee-50fd-bc25-302f-a9ca86a2fa6b", "be59cb1e-e78d-05ac-20e7-e9aac2f1c277", "6b74df0a-f1ff-44ef-94ac-f2b9fafe6013", "3f6974ef-cc56-668b-bd58-52a8a137cf86", "df3f4b56-e10a-b998-ddc2-3e0bd3b32393", "8c297add-cea0-bef0-a269-31414244940a", "4b5594f4-5998-ceac-9ed6-4869857e623d", "1e223aff-e5c6-64b7-031b-44a7d495cc6a", "1df2dcd4-e532-156a-722b-d5a35dd58ce6", "b2e89468-63a4-24d9-8e8b-497331b643a3", "55372728-8138-a381-94e8-65b1e07b0005", "30ecaf41-db76-a75a-d5df-63e8e6d34951", "97797f4a-1431-8f3a-c3e6-ff9b30ebac3e", "7a369593-6a26-e227-920e-4bc44ebbd851", "430ce5f3-ad52-943e-aa93-fc787c1542a9", "b6b63fab-bd5f-8640-305d-3565361b213f", "098c0250-7b22-0226-ada5-b848070055a7", "f6286af9-d853-7143-2783-3a0e54f32784", "703bca46-519a-f55c-7098-cb3b5c557091", "42f050df-10b0-8d7f-1669-995e4354656f", "6485c710-8131-a731-adb4-59e84d5f7747", "ecb1e319-b1a6-7c47-c00f-dcec90b6d07d", "8b7ecafc-0206-aa1a-f96b-0a104c46d9c5", "9640eda5-484d-aa25-31d6-47adcb494c27", "aa23f276-dc7b-263d-49ea-97d896644824" ] }, "message": "vms" } ], "tasks": [ [stripped successful backups] { "data": { "type": "VM", "id": "6b74df0a-f1ff-44ef-94ac-f2b9fafe6013" }, "id": "1582161536243:0", "message": "Starting backup of HALJenkins01. (fd08162c-228a-4c49-908e-de3085f75e46)", "start": 1582161536243, "status": "interrupted", "tasks": [ { "id": "1582161536246", "message": "snapshot", "start": 1582161536246, "status": "success", "end": 1582161541834, "result": "0df8d2a3-7811-49fe-baa0-5be4fec7a212" }, { "id": "1582161541836", "message": "add metadata to snapshot", "start": 1582161541836, "status": "success", "end": 1582161541845 }, { "id": "1582161557882", "message": "waiting for uptodate snapshot record", "start": 1582161557882, "status": "success", "end": 1582161558090 }, { "id": "1582161558098", "message": "start snapshot export", "start": 1582161558098, "status": "success", "end": 1582161558099 }, { "data": { "id": "ea4f9bd7-ccae-7a1f-c981-217565c8e08e", "isFull": false, "type": "SR" }, "id": "1582161558099:0", "message": "export", "start": 1582161558099, "status": "interrupted", "tasks": [ { "id": "1582161558117", "message": "transfer", "start": 1582161558117, "status": "interrupted" } ] } ] } ] }The VM was still running and usable at this time, also the SR for our CR backups did not show any problems.
I will check the jobs tomorrow morning to see if this happened again and maybe could be related to the latest upgrade. On previous version 5.41 we did not encounter any 'hanging' backupjobs.
-
Unfortunately, our CR jobs are not working properly after the upgrade. Some get backup successfully, some just facing randomly hanging jobs, not just pinned down to one particular VM as we thought first.
It looks like it suddenly stops transferring the deltas / importing the vdi. We noticed some strange backtrace errors in xensource.log, which are related to the point of time of backing up the VM.
xen02 xapi: [error|xen02|12074002 ||backtrace] Async.VM.snapshot_with_quiesce R:f6f758fd5e3f failed with exception Server_error(VM_SNAPSHOT_WITH_QUIESCE_NOT_SUPPORTED, [ OpaqueRef:80746e86-06bf-87e4-9b5f-e6bdb81094ae ]) xen02 xapi: [error|xen02|12074002 ||backtrace] Raised Server_error(VM_SNAPSHOT_WITH_QUIESCE_NOT_SUPPORTED, [ OpaqueRef:80746e86-06bf-87e4-9b5f-e6bdb81094ae ]) xen02 xapi: [error|xen02|12074002 ||backtrace] 1/1 xapi @ xen02 Raised at file (Thread 12074002 has no backtrace table. Was with_backtraces called?, line 0 xen02 xapi: [error|xen02|12074002 ||backtrace]xen02 xapi: [error|xen02|12074140 INET :::80|VDI.add_to_other_config D:d82237120feb|sql] Duplicate key in set or map: table VDI; field other_config; ref OpaqueRef:317a9b0c-3f1b-c88c-f5ff-13d92395fa67; key xo:copy_of xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] VDI.add_to_other_config D:d82237120feb failed with exception Db_exn.Duplicate_key("VDI", "other_config", "OpaqueRef:317a9b0c-3f1b-c88c-f5ff-13d92395fa67" xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] Raised Db_exn.Duplicate_key("VDI", "other_config", "OpaqueRef:317a9b0c-3f1b-c88c-f5ff-13d92395fa67", "xo:copy_of") xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 1/8 xapi @ xen02 Raised at file db_cache_impl.ml, line 263 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 2/8 xapi @ xen02 Called from file lib/pervasiveext.ml, line 22 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 3/8 xapi @ xen02 Called from file rbac.ml, line 236 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 4/8 xapi @ xen02 Called from file server_helpers.ml, line 80 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 5/8 xapi @ xen02 Called from file server_helpers.ml, line 99 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 6/8 xapi @ xen02 Called from file lib/pervasiveext.ml, line 22 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 7/8 xapi @ xen02 Called from file map.ml, line 117 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace] 8/8 xapi @ xen02 Called from file src/conv.ml, line 215 xen02 xapi: [error|xen02|12074140 INET :::80|dispatch:VDI.add_to_other_config D:7048d4831ced|backtrace]xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] VDI.get_by_uuid D:0438f795bf3a failed with exception Db_exn.Read_missing_uuid("VDI", "", "OLD_8693f679-6023-4776-accb-c4d2488d367b") xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] Raised Db_exn.Read_missing_uuid("VDI", "", "OLD_8693f679-6023-4776-accb-c4d2488d367b") xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 1/9 xapi @ xen02 Raised at file db_cache_impl.ml, line 211 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 2/9 xapi @ xen02 Called from file db_actions.ml, line 14838 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 3/9 xapi @ xen02 Called from file rbac.ml, line 227 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 4/9 xapi @ xen02 Called from file rbac.ml, line 236 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 5/9 xapi @ xen02 Called from file server_helpers.ml, line 80 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 6/9 xapi @ xen02 Called from file server_helpers.ml, line 99 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 7/9 xapi @ xen02 Called from file lib/pervasiveext.ml, line 22 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 8/9 xapi @ xen02 Called from file map.ml, line 117 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace] 9/9 xapi @ xen02 Called from file src/conv.ml, line 215 xen02 xapi: [error|xen02|12074217 UNIX /var/lib/xcp/xapi|dispatch:VDI.get_by_uuid D:357c7a87bcbf|backtrace]The hanging backup-job is still displayed as running in XO when this happens and can not be canceled in the webinterface. The only way to get out of this state is restarting xo-server.
Then the job switches to interrupted. If we start the backup again (restart failed or restart whole backup-job) the problematic VM eventually will back up successfully but the job will get stuck again, while backing up another randomly VM, leading to the same errors in the logs.
Please help, I am absolutely out of any ideas how to solve this. The remaining backups (delta, snapshot) are working as expected, only CR is now problematic.
-
Try with XOA to see if you can reproduce the issue there.
-
Additional to the above errors, we noticed a lot 'VDI_IO_ERROR' errors during the running jobs.
I remember there was a similar problem with CR which got fixed using the 'guessVhdSizeOnImport: true' option. Did anything change since then?
I will try with XOA trial when I have some spare time.
EDIT:
Can we import the config from our XO from sources to XOA or should we setup everything from scratch? -
Some addional info that might be relevant to this issue:
When stopping / starting xo-server after a hanging job, the summary sent as report is interesting as it states that the SR and VM isn't available / not found - which is obviously wrong..
## Global status: interrupted - **Job ID**: fd08162c-228a-4c49-908e-de3085f75e46 - **Run ID**: 1582618375292 - **mode**: delta - **Start time**: Tuesday, February 25th 2020, 9:12:55 am - **Successes**: 13 / 32 --- ## 19 Interrupted ### VM not found - **UUID**: d627892d-661c-9b7c-f733-8f52da7325e2 - **Start time**: Tuesday, February 25th 2020, 9:12:55 am - **Snapshot** ✔ - **Start time**: Tuesday, February 25th 2020, 9:12:55 am - **End time**: Tuesday, February 25th 2020, 9:12:56 am - **Duration**: a few seconds - **SRs** - **SR Not found** (ea4f9bd7-ccae-7a1f-c981-217565c8e08e) ⚠️ - **Start time**: Tuesday, February 25th 2020, 9:14:26 am - **transfer** ⚠️ - **Start time**: Tuesday, February 25th 2020, 9:14:26 am [snip] -
@tts said in Backup jobs run twice after upgrade to 5.76.2:
Can we import the config from our XO from sources to XOA or should we setup everything from scratch?
Today I got XOA trial ready and imported config from XO-from-sources. Manually started CR jobs are working. Will test it with scheduled CR next couple of days.
-
Right now one of my CR jobs are stuck, symptoms are the same as with XO from sources.
XOA 5.43.2 (xo-server and xo-web 5.56.2)
Hosts where VM is running and where it is replicated to, both XenServer 7.0
Backup log:{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1582750800014", "jobId": "b5c85bb9-6ba7-4665-af60-f86a8a21503d", "jobName": "web1", "message": "backup", "scheduleId": "6204a834-1145-4278-9170-63a9fc9d5b2b", "start": 1582750800014, "status": "pending", "tasks": [ { "data": { "type": "VM", "id": "04430f5e-f0db-72b6-2b73-cc49433a2e14" }, "id": "1582750800016", "message": "Starting backup of web1. (b5c85bb9-6ba7-4665-af60-f86a8a21503d)", "start": 1582750800016, "status": "pending", "tasks": [ { "id": "1582750800018", "message": "snapshot", "start": 1582750800018, "status": "success", "end": 1582750808307, "result": "6e6c19e2-104c-1dcf-a355-563348d5a11f" }, { "id": "1582750808314", "message": "add metadata to snapshot", "start": 1582750808314, "status": "success", "end": 1582750808325 }, { "id": "1582750808517", "message": "waiting for uptodate snapshot record", "start": 1582750808517, "status": "success", "end": 1582750808729 }, { "id": "1582750808735", "message": "start snapshot export", "start": 1582750808735, "status": "success", "end": 1582750808735 }, { "data": { "id": "4a7d1f0f-4bb6-ff77-58df-67dde7fa98a0", "isFull": false, "type": "SR" }, "id": "1582750808736", "message": "export", "start": 1582750808736, "status": "pending", "tasks": [ { "id": "1582750808751", "message": "transfer", "start": 1582750808751, "status": "pending" } ] } ] } ] }Perhaps there is something with my environment but then why it is working with older XO versions.
-
Ping @julien-f
-
There is probably a problem in XO regarding this because we have received multiple similar reports, we are investigating.
-
@karlisi I've been unable to reproduce the issue so far, can you tell me which version of XO has the issue and which one does not?
Also, if you could provide me with your job configuration it would be nice
")
-
@julien-f said in Backup jobs run twice after upgrade to 5.76.2:
@karlisi I've been unable to reproduce the issue so far, can you tell me which version of XO has the issue and which one does not?
Also, if you could provide me with your job configuration it would be nice
Can I send it to you in PM?
-
In this case, it's better that you open a ticket on xen-orchestra.com
-
@olivierlambert Done
-
Thanks a lot for this great ticket with all the context, this is really helpful!

-
Hi,
I can give a little update on our issues, but our 'workaround' is really time consuming.
Besides the problem of randomly stuck CR jobs, which could be fixed mostly by:
stop xo-server/ start xo-server (sometimes needed to restart xo-vm) and restart the interrupted jobs again and again until all VM are successfully backed up.
Now without changing anything the jobs are again started twice again most of the time, but not always.
I can not find a correlation to this.
Somehow it looked that this could be fixed by dis/enabling the backup jobs, but as of now this doesn't make any difference.
-Toni
-
@tts Are You on latest XOA version?
-
It wasn't XOA, we used xo-server from sources.
I planned to test with XOA but Olivier yesterday wrote that it's probably fixed upstream.
So I updated our installation to xo-server 5.57.3 / xo-web 5.57.1 and will see if it's fixed.
fingers crossed
-
Maybe there are additional problems. I just noticed one of our rolling-snapshot task started twice again.
This time it's even more weird, both jobs are listed as successfull.

The first job displays just nothing in the detail window:
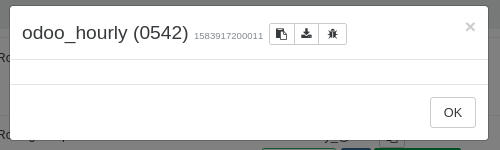
json:{ "data": { "mode": "full", "reportWhen": "failure" }, "id": "1583917200011", "jobId": "22050542-f6ec-4437-a031-0600260197d7", "jobName": "odoo_hourly", "message": "backup", "scheduleId": "ab9468b4-9b8a-44a0-83a8-fc6b84fe8a95", "start": 1583917200011, "status": "success", "end": 1583917207066 }The second job shows 4? VMs but only consists of one VM which failed, but is displayed as successful
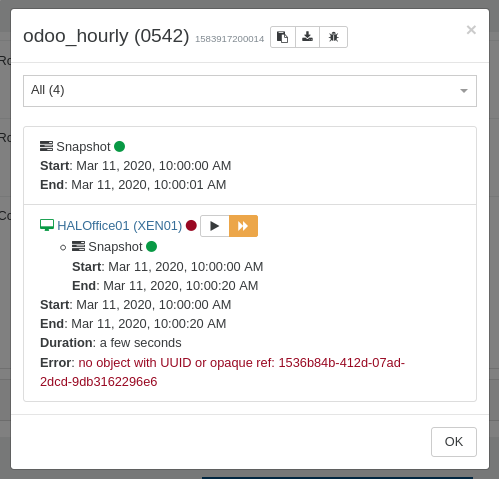
json:{ "data": { "mode": "full", "reportWhen": "failure" }, "id": "1583917200014", "jobId": "22050542-f6ec-4437-a031-0600260197d7", "jobName": "odoo_hourly", "message": "backup", "scheduleId": "ab9468b4-9b8a-44a0-83a8-fc6b84fe8a95", "start": 1583917200014, "status": "success", "tasks": [ { "id": "1583917200019", "message": "snapshot", "start": 1583917200019, "status": "success", "end": 1583917201773, "result": "32ba0201-26bd-6f29-c507-0416129058b4" }, { "id": "1583917201780", "message": "add metadata to snapshot", "start": 1583917201780, "status": "success", "end": 1583917201791 }, { "id": "1583917206856", "message": "waiting for uptodate snapshot record", "start": 1583917206856, "status": "success", "end": 1583917207064 }, { "data": { "type": "VM", "id": "b6b63fab-bd5f-8640-305d-3565361b213f" }, "id": "1583917200022", "message": "Starting backup of HALOffice01. (22050542-f6ec-4437-a031-0600260197d7)", "start": 1583917200022, "status": "failure", "tasks": [ { "id": "1583917200028", "message": "snapshot", "start": 1583917200028, "status": "success", "end": 1583917220144, "result": "62e06abc-6fca-9564-aad7-7933dec90ba3" }, { "id": "1583917220148", "message": "add metadata to snapshot", "start": 1583917220148, "status": "success", "end": 1583917220167 } ], "end": 1583917220405, "result": { "message": "no object with UUID or opaque ref: 1536b84b-412d-07ad-2dcd-9db3162296e6", "name": "Error", "stack": "Error: no object with UUID or opaque ref: 1536b84b-412d-07ad-2dcd-9db3162296e6\n at Xapi.apply (/opt/xen-orchestra/packages/xen-api/src/index.js:573:11)\n at Xapi.getObject (/opt/xen-orchestra/packages/xo-server/src/xapi/index.js:128:24)\n at Xapi.deleteVm (/opt/xen-orchestra/packages/xo-server/src/xapi/index.js:692:12)\n at iteratee (/opt/xen-orchestra/packages/xo-server/src/xo-mixins/backups-ng/index.js:1268:23)\n at /opt/xen-orchestra/@xen-orchestra/async-map/src/index.js:32:17\n at Promise._execute (/opt/xen-orchestra/node_modules/bluebird/js/release/debuggability.js:384:9)\n at Promise._resolveFromExecutor (/opt/xen-orchestra/node_modules/bluebird/js/release/promise.js:518:18)\n at new Promise (/opt/xen-orchestra/node_modules/bluebird/js/release/promise.js:103:10)\n at /opt/xen-orchestra/@xen-orchestra/async-map/src/index.js:31:7\n at arrayMap (/opt/xen-orchestra/node_modules/lodash/_arrayMap.js:16:21)\n at map (/opt/xen-orchestra/node_modules/lodash/map.js:50:10)\n at asyncMap (/opt/xen-orchestra/@xen-orchestra/async-map/src/index.js:30:5)\n at BackupNg._backupVm (/opt/xen-orchestra/packages/xo-server/src/xo-mixins/backups-ng/index.js:1265:13)\n at runMicrotasks (<anonymous>)\n at processTicksAndRejections (internal/process/task_queues.js:97:5)\n at handleVm (/opt/xen-orchestra/packages/xo-server/src/xo-mixins/backups-ng/index.js:734:13)" } } ], "end": 1583917207065 }So the results are clearly wrong, job is ran twice, this time at the same point in time.
Would it help to delete and recreate all of the backup jobs?
What extra information I could offer to get this issue fixed?Already thinking about setting up another new xo-server from scratch now.
please help and advice,
thanks Toni -
Please try with XOA and report if you have the same problem.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login