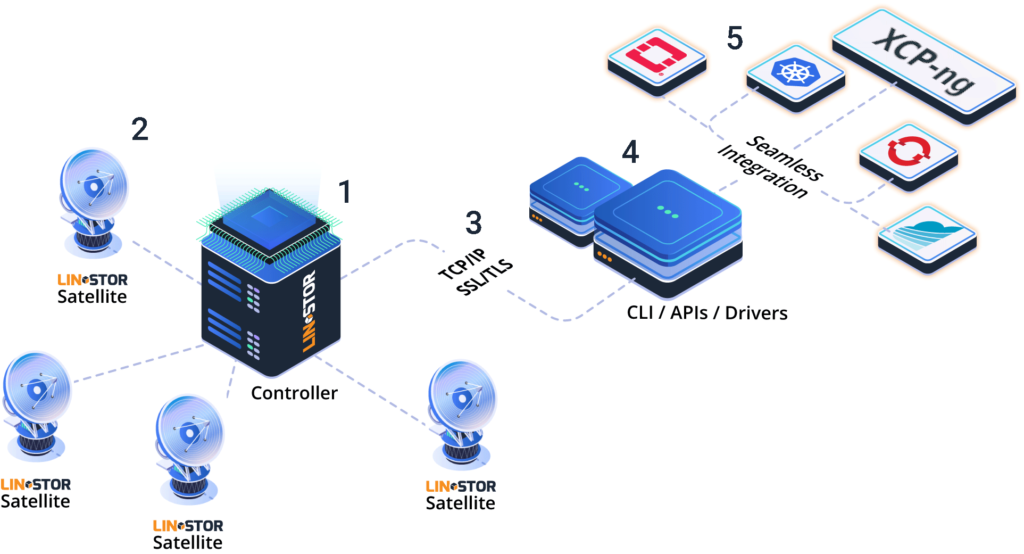
-
@ronan-a I was running a replication count of 2 with a 3 nodes cluster, all with disks. You see I wrote "was". I am reinstalling the cluster as I write this, because I got into a state where I was unable to even stop am VM on it.
Do I understand it correctly that I can use a replication count of 2 within a 3-node cluster and my data will be replicated 2 times so on 2 nodes? Or do I need to use a replication count of 3 on a 3-node cluster to be ablet o let my VMs running on all nodes and be able to do a live migration to all nodes?
-
@Swen Do I understand it correctly that I can use a replication count of 2 within a 3-node cluster and my data will be replicated 2 times so on 2 nodes?
Yes. Each VDI will be replicated two times on different nodes.
")
Or do I need to use a replication count of 3 on a 3-node cluster to be ablet o let my VMs running on all nodes and be able to do a live migration to all nodes?
You can start a VM on any node with a replication count of 2. In this case diskful or diskless volume is used. Of course in this last case, the performance can be impacted by the network.
-
@ronan-a do you know anything about nic bandwidth limitations of xcp-ng? It looks like I am unable to use the full bandwidth of the 10Gbit connection between the nodes. I get 125 MBps which is the maximum of a 1Gbit NIC if I calulate correctly.
If I do the test n 2 VMs on the storage the max bandwidth stays the same. -
I've observed a similar issue, when I was testing the driver for the 2.5GBit/s USB3 NIC, while the system was running on a 1Gbit connection normally: somehow
iperf3gave me Gbit results even when I was clearly talking to the IP of the 2.5GBit port, whichethtoolconfirmed to be running at 2.5Gbit/s speed.Well except when I took the Gbit interface down to make sure nothing fishy was going on, the "2.5Gbit" connection went down with it.
My explanation is that in fact it was talking to the Gbit port, which is configured as promiscous by Xcp-ng and 'hijacked' traffic to both IPs, so I didn't really reach the 2.5Gbit port.
I can easily imagine something similar going on in your case.
I haven't had time to test further, but I'm pretty sure you'll have to make the 10Gbit port fully known to Xcp to avoid issues with the promiscuity of the management interface or perhaps you can try with separated switches (or a cross connect cable) for the 10Gbit part, just to confirm the diagnose.
-
@abufrejoval thx for your feedback. I need to investigate this further. We already using a different switch for the 10Gbit interfaces with another IP subnet.
-
@ronan-a I was unable to find some limitations regardings the bandwidth of an interface. Do you know anything about it?
-
How do you measure? Do you measure disk I/O e.g. via Jens Axboe's wounderful
fiotool or do you measure at the network level e.g. viaiperf3first?I've gotten around 300MB/s write speeds inside a Windows VM using Crystal Disk Mark with 4-way LINSTOR replication using Xcp-ng running nested under VMware Workstation on Windows (Ryzen 9 5950X 16-core with plenty of RAM all NVMe storage).
Iperf3 between these virtual Xcp-ng hosts will only yield around 5Gbit/s, so 300MB/s is rather better than I'd expect, given that each block is replicated 4 times. Reads on Crystal Disk Mark are better than 1.3GB/s as they don't suffer from write amplification and could actually be done round-robin (and it seems they are, too).
But that's a nested virtualization setup, which is really just meant for functional failure testing, not for meaningful benchmarking.
I haven't gotten around to using LINSTOR yet on my physical NUC8/10/11 cluster using 10Gbit NICs, but they give me close to 10Gbit/s with
iperf3, while a Xeon-D 1542 based host only reaches about 5-6Gbit/s with budget Aquantia ACC107 NICs all around, that don't support much in terms of offload capabilities.On oVirt I used an MTU of 9000 to reach full 10Gbit bandwidth on all machines, but I haven't found any documentation on how to increase the MTU on the physical NICs in Xcp-ng yet.
-
@abufrejoval I am using dd on Ubuntu20 VMs on 3 ProLiant D360 servers with SSDs. I mounted 1 SSD directly to XCP-ng and 3 to linstor on each server. When I do a
dd if=/dev/zero of=benchfile bs=4k count=2000000 && sync; rm benchfileon a VM using local storage I get around 185MB/s
when I do the same on 1 VM on linstor storage I get around 125MB/s
but when I do the test on 2 VM on linstor storage on the same XCP-ng host I get around 60MB/s each.
Do me it looks like the NIC is the bottleneck, but please correct me if I am wrong.
-
@ronan-a another thing I found is that it linstor occupies more storage than expected. I created the sr with option 'thin'. I created 2 VMs each with 50GB disk. XCP-ng cente ris shoing me
238.7 GB used of 2.6 TB total (150 GB allocated)I would not expected that! I would expected less than 100 GB used and allocated.
-
@Swen Could you list the VDIs of your linstor SR please?
-
@ronan-a sure, do you mean the output of xe vdi-list?
-
@Swen Yes, because this allocation value is indeed surprising.
-
[16:30 xcp-test1 ~]# xe vdi-list sr-uuid=77e5097a-c971-34e4-9506-7386a1e640b8 uuid ( RO) : 23876ae4-27b3-4f2f-8c8b-eb623b2dc2e4 name-label ( RW): base copy name-description ( RW): sr-uuid ( RO): 77e5097a-c971-34e4-9506-7386a1e640b8 virtual-size ( RO): 53687091200 sharable ( RO): false read-only ( RO): true uuid ( RO) : 3a2ab3da-5507-4c7e-aa07-497c65b18ec1 name-label ( RW): ubuntu20-linstor 0 name-description ( RW): Created by template provisioner sr-uuid ( RO): 77e5097a-c971-34e4-9506-7386a1e640b8 virtual-size ( RO): 53687091200 sharable ( RO): false read-only ( RO): false uuid ( RO) : 13a8fa52-9aa3-490b-86e0-eedb101128f9 name-label ( RW): ubuntu20-linstor 0 name-description ( RW): Created by template provisioner sr-uuid ( RO): 77e5097a-c971-34e4-9506-7386a1e640b8 virtual-size ( RO): 53687091200 sharable ( RO): false read-only ( RO): falseok, the third vdi makes sense, cause I used storage-level fast disk clone to duplicate the VM. This explains the allocated value I guess, but not the used one.
Did you see my other question? Are you aware of any NIC constraints regarding throughput?
-
@ronan-a Wait a sec, maybe I found the root cause. I created a snapshot of a VM and deleted it. It created another base copy vdi and allocated space is now 200GB. MAybe I need to wait for the celanup job to take care of this?
-
@Swen The 150GiB are related to the base copy VDI yes.
")
Of course this value is just the maximum amount of data used because you use the thin LVM plugin. (It's not the real used data.)Regarding NIC, I didn't encounter any problems during my tests. The best way to measure the DRBD performance is to use
fiodirectly in a VM and also on the host with a DRBD volume.The difference between local storage and DRBD is not a surprise:
- DRBD must sync the data between nodes
- DRBD is on top of LVM
-
@Swen
Writing zeros should result in nothing written with thin allocation (or dedup and compression): that's why I am hesitant to use /dev/zero as a source.Of course /dev/random could require to much of an overhead, depending on the quality and implementation which is why I like to use
fio: a bit of initial effort to know and understand the tool, but much better control, especially when it comes to dealing with an OS that tries to be smart. -
@ronan-a did you use 10Gbit interfaces for linstor traffic? I am aware that there is a difference between local storage and DRBD, but if this difference is that high, linstor is not really interesting for high performance workloads. I need to be sure that the root cause it not related to my setup.
@ronan-a @abufrejoval which exact fio params are you using to test your environment and can you copy some numbers, so we can compare them?
-
We mostly use those displayed in this blog post: https://smcleod.net/tech/2016/04/29/benchmarking-io/
edit: depending on the storage, iodepth can be increased.
-
There is obviously tons of variations....
I've used this fio file a lot to quickly gain an understanding of how a bit of storage performs.
Basically it only uses a small 100MB file, but tells the OS to avoid buffering and then goes over that with a mix of reads and writes, mostly transitioning between block size, essentially going from super random to almost sequential in a single run.
It's helped me find issues with Gluster, identify network bandwidth issues or even find deteriorated RAIDs with a bad BBU. Creates the test file in the working directiory unless changed.
[global] filename=fio.file ioengine=libaio rw=randrw size=100m norandommap direct=1 iodepth=1 time_based runtime=10 [B512] bs=512 stonewall [B1k] bs=1k stonewall [B2k] bs=2k stonewall [b4k] bs=4k stonewall [b8k] bs=8k stonewall [b16k] bs=16k stonewall [b32k] bs=32k [b64k] bs=64k stonewall [b512k] bs=512k stonewall [b1m] bs=1m stonewallNumbers: It should approach the network bandwidth towards the end (potentially divided by write amplification).
-
@ronan-a Hi,
I tested your branch and now the new added hosts to the pool are now attached to the XOSTOR. This is nice !
I have looked at the code, but I'm not sure if in the current state of your branch we can add a disk on the new host and update the replication ? I think not... but just to be sure.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login