Backup through XO fails (VHD check error etc.)
-
Hi Guys,
since a few days, backup jobs on some VMs fail - all with different errors. It has worked before since ages and since some days - out of the blue -
The corresponding full log is this one:
2022-10-13T08_30_00.017Z - backup NG.txt
Another VM's log:
2022-10-13T15_00_00.030Z - backup NG.txt
I am using XO from the sources, xo-server 5.103.1, xo-web 5.104.0, commit 42a97.
Any help would be appreciated!
Thanks a lot and best wishes!
-
Adding @florent in the loop
-
@tanjix as long a sthe backup doesn't run till the end, it won't clean the repo
Have you got any performance issue on you XO ( like memory issue ) since the backup worker exits without any information ?
-
@florent said in Backup through XO fails (VHD check error etc.):
@tanjix as long a sthe backup doesn't run till the end, it won't clean the repo
Have you got any performance issue on you XO ( like memory issue ) since the backup worker exits without any information ?
Hello @florent,
no, there's plenty of CPU/RAM resources available. Hope that helps?
If you want me to provide additional info, let me know.
Thanks and best wishes!
-
@tanjix what is the remote type ? (nfs /local/s3) ? do you use
Store backup as multiple data blocks instead of a whole VHD file.? encryption? -
My remote is a NFS share on another host, connected via 10G SFP+.
The option "Store backup as multiple data blocks instead of a whole VHD file" is not in use. This is my remote settings in XO: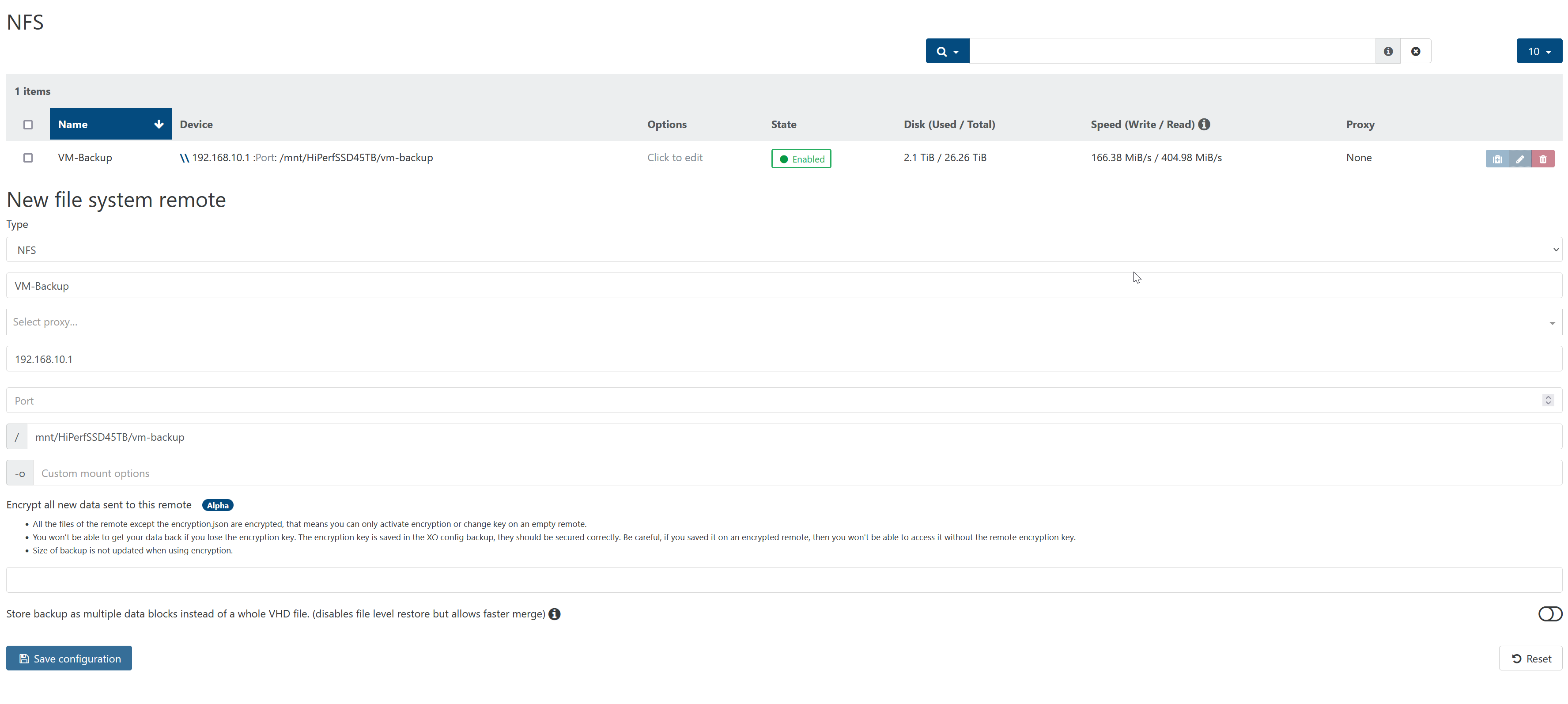
-
No idea if it helps: This issue is not on all backup jobs, only on some of them.
But I wasn't yet able to find out any similarities between those failing ones compared to those, that work fine. -
@tanjix I will look into it and tell you if I find any clue
-
@florent An observation / similiarity:
Problems occur on VMs with big disks. Could the backup run into a timeout (whyever?)?
I am backing up all my VMs using a "delta backup" on an hourly basis, all scheduled at different times within the hour (like :15 for VM1, :30 for VM2 etc.). -
@tanjix as long as the size is under 2To, it should be ok. Also timeout are generally shown in the error log . I am still searching
-
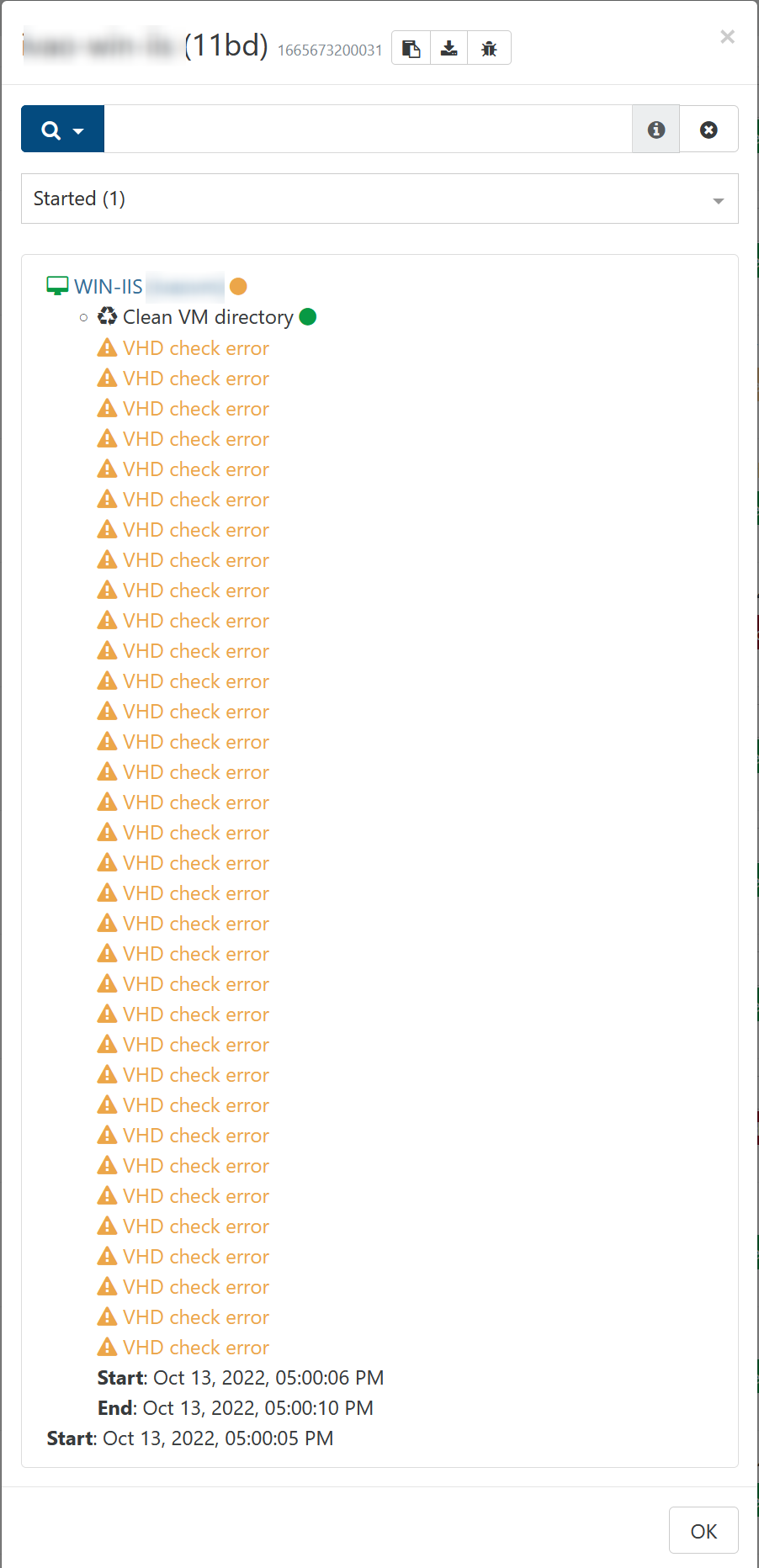
@florent the size of the VMs, where this problem exists, is below 2TB:
I observed this behaviour on 5 VMs, 3 of them on the same host, where 2 of them are Windows ones
- Win-DB = 100GB (on NFS-Storage with plenty of free space available)
- Win-IIS = 100GB (on NFS-Storage with plenty of free space available)
- srv02 = 55GB (sys) and 75GB (data) (both on NFS-Storage with plenty of free space available)
- vps01 = 10GB (sys) and 500GB (data) (both on NFS-Storage with plenty of free space available)
- vps02 = 10GB (sys) and 500GB (data) (both on NFS-Storage with plenty of free space available)
If I can provide anything additional, let me know.
Thanks!
-
@tanjix I found the cause of the error messages ENOTDIR (a side effect of encryption )
but it won't explain why the backup fails ( worker exited with code null ) I'm still looking for a cause
-
@florent Hi florent, great news! I'm just wondering, which encryption you mean? On my end, I am not encrypting anything.
-
@tanjix nope it was with the changes we made to plug encryption on the data pipeline
but it's not the cause of the backup falingdo you have some logs on the xenserver side ?
can you monitor available memory on XO during a backup ?
-
@florent Apologies for my late response.
Which log exactly would you be looking for? the SMlog under /var/log on the XCP host?
-
@florent I reverted back to:
xo-server 5.100.0
xo-web 5.101.0
commit 26e7eand I'm facing the same issues. If you can tell me, which logs you need, I can surely provide them.
Thanks!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login