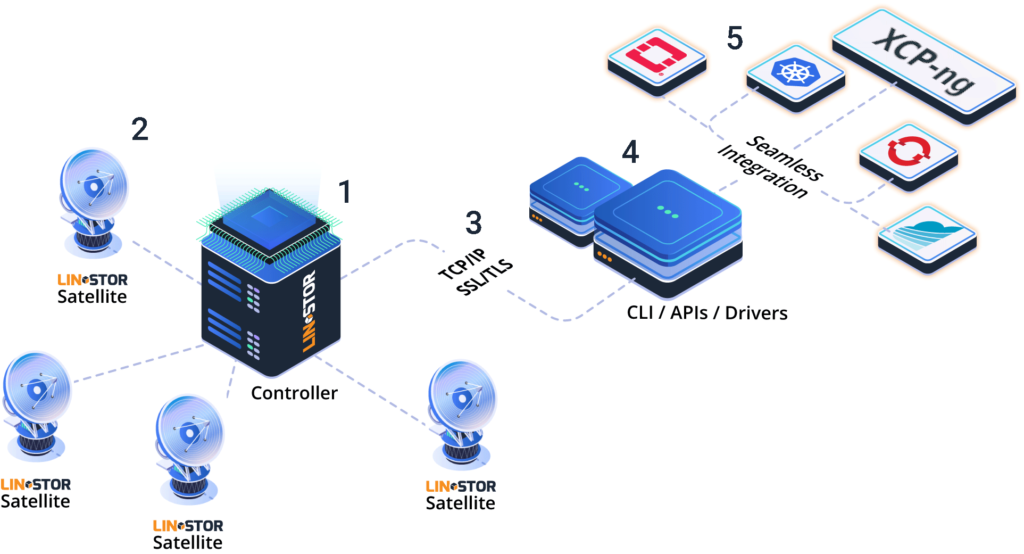
-
Hi,
I've run the install script on a XCP-ng 8.2.1 host. The output of the following command:
rpm -qa | grep -E "^(sm|xha)-.linstor."
sm-2.30.8-2.1.0.linstor.5.xcpng8.2.x86_64
xha-10.1.0-2.2.0.linstor.1.xcpng8.2.x86_64
is missing, because it is already installed in version:
xha-10.1.0-2.1.xcpng8.2.x86_64
from XCP-ng itself.
Is this packace still needed from the linstor repo?
Should I uninstall it an re-run the install script?BR,
Wilken -
question for @ronan-a
-
@Wilken The modified version of the xha package is no longer needed. You can use the latest version without the linstor tag.
It's not necessary to reinstall your XOSTOR SR.
-
Thank you @olivierlambert and @ronan-a for the quick answer and clarification!
BR,
Wilken -
 A AtaxyaNetwork referenced this topic on
A AtaxyaNetwork referenced this topic on
-
Hi !
Before I test this, I have a small question:
If the VM is encrypted, and XOSTOR SR is enabled, is the VM + Memory replicated or just the VDI ?
Once the 1st node is down, will the 2nd node take over as-is or will the 2nd node go to 'boot' stage where is asks for decryption password ?Thanks
-
@gb-123 How the VM is encrypted? Only the VDIs are replicated.
-
VMs would be using LUKS encryption.
So if only VDI is replicated and hypothetically, if I loose the master node or any other node actually having the VM, then I will have to create the VM again using the replicated disk? Or would it be something like DRBD where there are actually 2 VMs running in Active/Passive mode and there is an automatic switchover ? Or would it be that One VM is running and the second gets automatically started when 1st is down ?
Sorry for the noob questions. I just wanted to be sure of the implementation.
-
@gb-123 said in XOSTOR hyperconvergence preview:
VMs would be using LUKS encryption.
So if only VDI is replicated and hypothetically, if I loose the master node or any other node actually having the VM, then I will have to create the VM again using the replicated disk? Or would it be something like DRBD where there are actually 2 VMs running in Active/Passive mode and there is an automatic switchover ? Or would it be that One VM is running and the second gets automatically started when 1st is down ?
Sorry for the noob questions. I just wanted to be sure of the implementation.
The VM metadata is at the pool level, meaning that you wouldn't have to re-create the VM if the current VM host has a failure. However, memory can't/isn't replicated in the cluster, unless you're doing a live migration which would temporarily replicate the VM memory to the new host, so it can be moved.
DRBD only replicates the VDI, or in other terms, the disk data across the active Linstor members. If the VM is stopped or is terminated because of host failure, you should be able to start it back up on another host in your pool, but by default, this will require manual intervention to start the VM, and will require you to input your encryption password since it will be a cold boot.
If you want the VM to automatically self-start in case of failure, you can use the HA feature of XCP-ng. This wouldn't solve your issue with having to input your encryption password since, like explain earlier, the memory isn't replicated, and it would cold boot from the replicated VDI. Also, keep in mind that enabling HA adds maintenance complexity and might not be worth it.
-
Thanks for your clarification !
I was thinking of testing HA with XOSTOR (If at all that is possible). XOSTOR would also be treated as 'Shared SR' I guess ? -
@gb-123 Yes, use the shared flag as in the sr-create example of the first post, and you can activate the HA like any shared SR.
-
 O olivierlambert referenced this topic on
O olivierlambert referenced this topic on
-
hi @ronan-a,
we did some performance testing with the latest version and we run into a bottleneck we are unable to identify in detail.Here is our setup:
Dell R730
CPU: 2x Intel E5-2680v4
RAM: 384GB
Storage: 2x NVMe Samsung PM9A3 3.84TB via U.2 PCIe 3 x16 Extender Card
NICs: 2x 10G Intel, 2x 40G IntelWe have 3 servers with the same configuration and installed them as a cluster with replica count of 2.
xcp-ng 8.2 with latest patches is installed. All servers are using the same switch (2x QFX5100-24Q, configured as virtual chassis). We are using a LACP bond on the 40G interfaces.When using the 10G interfaces (xcp-ng is using those interfaces as management interfaces) for linstor traffic we run into a cap on the nic bandwith of around 4 Gbit/s (500MB/s).
When using the bonded 40G interfaces the cap is around 8 Gbit/s (1000MB/s)Only 1 VM is installed on the pool. We are using Ubuntu 22.04 LTS with latest updates installed from ISO using the template for Ubuntu 20.04.
Here is the fio command we are using:
fio --name=a --direct=1 --bs=1M --iodepth=32 --ioengine=libaio --rw=write --filename=/tmp/test.io --size=100GI would expect far more because we do not hit any known bottleneck of interfaces, NVMe or PCIe slot. Do I miss something? Is this expected performance? If not, any idea what the bottleneck is? Does anybody have some data we can compare with?
regards,
Swen -
- use iodepth of 128
- use 4 process at the same time (numjobs=4)
- use io_uring if you can in the guest (and not libaio)
- don't use a test file but bench directly on a non-formatted device (like /dev/xvdb), this removes the filesystem layer
With those settings in
fio, I can reach near 2600MiB/s in read, and 900MiB/s in write with 4x virtual disks in mdadm RAID0, in the guest (a test VM on Debian 12), on rather "old" Xeon CPUs and a PCIe 3 ports on an consumer grade NVMe SSD.Also, latest thing to know: if you use thin pro, you need to run the test twice, the first run (while the VHD is growing), it's always slower. And this is not a problem in real life, you can run twice or 3 times and check the result your tests, without counting the first.
I'm about to get more recent hardware (except the NVMe) to re-run some tests this week. But as you can see, you can go over a 20G network (I'm using a 25G NIC)
-
@olivierlambert thx for the feedback! I do not get how you see that you reach 20G on your nic. Can you please explain it? I see that you reach 2600MiB/s in read, but this is more likely on local disk, isn't? What I can see in our lab environment is that for what ever reason we do not get more than around 8Gbits on pass-through via a 40G interface and 4Gbits via a 10G interface and therefore we do not get any good performance out of the storage repository. I am unable to find the root cause of this. Do you have any idea where to look? I can see high waits on the OS of the VM, but no waits inside dom0 of any node.
-
First, always do your storage speed test in a regular VM. The Dom0 doesn't matter: you won't run your workload in it, so test what's relevant to you: inside a dedicated VM.
Also, it's not only a matter of network speed, but latency, DRBD, SSD speed any many other things. Only Optane drives or RAM are relevant to really push XOSTOR, because there's not a lot of NVMe that can sustain heavy writes without slowing down (especially on 100GiB file).
But first, start to benchmark with the right
fioparameters, and let's see")
-
@olivierlambert just to be sure: we did also use your recommended fio parameters with the exact same results. We used fio from inside a VM not from inside dom0. My comments regarding waits inside the VM and no waits in dom0 was just additional information.
I am aware of possible bottleneck like latency, SSD others, but in our case we can rule them out. Reason is that we double our speed when switching from 10G to 40G interface while the rest is the exact same configuration. As fsr as I can see this looks to me like xcp-ng is the bottleneck and limiting bandwidth of the interface in some way. Even the numbers you provided are not really good performance numbers. Did you get more bandwidth than 8 Gbits over the linstor interface?
We are going to install Ubuntu on the same servers and install linstor on it to test our infrastructure on bare-metal without any hypervisor to see if it is xcp-ng related or not.
-
Those are really good numbers for a replicated block system, on top of a virtualization solution.
The fact you are doubling the speed isn't just about bandwidth, but also likely latency related. XOSTOR works in sync mode, so you have to wait for blocks to be written on the destination before getting the confirmation. You might try on bigger blocks to see if you can reach higher throughput.
Also, remember that if you test in a VM on a single virtual disk, that's absolutely the bottleneck here (
tapdisk). There's one process per disk, that's why I advise to test either with multiple VMs at the same time to really push XOSTOR to its limits, or create a big RAID0 with many virtual drives you can (however, first option is better because you can have VMs on multiple hosts at the same time).In short, the system scales with the number of VMs, not when benchmarking with one VM and one disk only.
Finally, don't forget thin mode that is requiring to run the test at least twice to really see the performance. On your side, you are very likely CPU bound due to an 8 years old Intel CPU/architecture, which is not that's efficient. But on that, I'll be able to provide a real result comparing my test bench in Xeon vs Zen in 2 days.
-
Is it possible to change replication factor later on the fly eg. after adding a new host (without loosing data) ?
-
That's a question for @ronan-a when he'll be back
But in any case, IIRC, the preferred replication number for now is 2.
-
@gb-123 You can use this command:
linstor resource-group modify xcp-sr-linstor_group_thin_device --place-count <NEW_COUNT>You can confirm the resource group to use with:
linstor resource-group listIgnore the default group named:
DfltRscGrpand take the second.Note: Don't use a replication count greater than 3.
-
I have installed the XOSTOR with replica count of 2.
I have tried running one E-mail Server (PostFix) and one Web-Server (Nginx), with their VHD on XOSTOR. They seem to run fine. I have not done any benchmarks for now.After installing, I noticed that the VxLAN (Encrypted) has stopped working.
Update:
I managed to fix the VxLAN by :
- Completely Removing all PIFs of VxLAN and removing the VxLAN Network from the pool
- Remove SDN controller configuration from plugin page > delete configuation
- Shutdown ALL hosts from the pool
- Restart XO VM
- Enable SDN controller again (this time with Override Certs ON)
- Click Save Configuration.
- Start All Hosts
- Create VxLAN again.
Previous Error Details (Now Solved as mentioned in the update above):
So this is how I was using:
1 VM on Node 1 which runs pfSense Router
VxLan (encrypted) on the pool.Other VMs on Node 1 & Node 2.
VMs on Node1 are connecting to the pfSense which is running on the same node.
VMs on Node2 have stopped connecting.I have not changed any settings. All I did for installing XOSTOR, was remove the previous SR (after migrating vhd to another sr using XO) edit partition (using fdisk) and then create 2 SRs (One for EXT4 and the Other for XOSTOR) and migrate all VHDs back to EXT4 and XOSTOR (as per requirement). I did this for both nodes.
I am not sure if installing XOSTOR has something to do with this or not so this is not a bug report (yet).So far I have tried :
- Turn off and turn on SDN Controller in XO
- Override certificates in SDN controller in XO and rebooting both host nodes.
Do you think XOSTOR would have an impact on the MTU in the host Network Card ?
Any direction you can give me to diagnose the problem ?
I am planning to remove the VxLAN and re-create it. Do you think it would help ?Update : Checked XO Logs:
I get :2023-08-11T14:00:17.907Z xo:xo-server:sdn-controller:tls-connect ERROR TLS connection failed { xen-orchestra-docker-orchestra-1 | error: [Error: 58EBD01E7F7F0000:error:0A000418:SSL routines:ssl3_read_bytes:tlsv1 alert unknown ca:../deps/openssl/openssl/ssl/record/rec_layer_s3.c:1586:SSL alert number 48] { | library: 'SSL routines', | reason: 'tlsv1 alert unknown ca', | code: 'ERR_SSL_TLSV1_ALERT_UNKNOWN_CA' | },Though earlier, the connection between Node1 and Node 2 were still being made despite this warning. So this is not new.
Further Update:
I deleted the previous VxLAN and now when I try to create it, it gives me the following error :
sdnController.createPrivateNetwork { "poolIds": [ "b990a09e(*removed*)" ], "pifIds": [ "68fc6193(*removed*)" ], "name": "VxLAN", "description": "Private Lan Network", "encapsulation": "vxlan", "encrypted": true, "mtu": 1500 } { "library": "SSL routines", "reason": "tlsv1 alert unknown ca", "code": "ERR_SSL_TLSV1_ALERT_UNKNOWN_CA", "message": "582B645BC47F0000:error:0A000418:SSL routines:ssl3_read_bytes:tlsv1 alert unknown ca:../deps/openssl/openssl/ssl/record/rec_layer_s3.c:1586:SSL alert number 48 ", "name": "Error", "stack": "Error: 582B645BC47F0000:error:0A000418:SSL routines:ssl3_read_bytes:tlsv1 alert unknown ca:../deps/openssl/openssl/ssl/record/rec_layer_s3.c:1586:SSL alert number 48 " }
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login