-
We're running out of free space on our of our remotes. The remote itself has 30TB of storage, and our collective pool for VM's doesn't reach 15-16TB's
Looking at the files, we can see some of the files on the remote has very old timestamps and seems like they were duplicated at some point (some of the files was last touched in July and we have weekly backups)
How can I determine whether some of these files are possibly orphaned files we can delete? Worth noting the backup "health" does not show these backups as orphaned.
Note that although we have a paid for version of XO, our backups are still running on a legacy / community version until Feb when we will be moving onto a combined XCP / XO bundle, hence why I am asking the question on the forum and not opening a ticket.
-
Question for @florent I suppose

-
 O olivierlambert moved this topic from Xen Orchestra on
O olivierlambert moved this topic from Xen Orchestra on
-
@mauzilla Are you using full backup ( one xva file per backup) or delta differential ?
delta can really reduce the space requirerementthere can be some older cache.json.gz files, but they shouldn't take much space. If the backup aren't showing in the health panel as orphaned, either there is a bug (always possible, but we didn't change too much recently there) or you have some backup job with a long retention
the main space usage should be in *.xva and *.vhd files. Can you make a query like
# find / -type f -size +20G -name "*.xva"(adjust the size if necessary) , and then the same one with vhd ?Also, a remote can be mounted on multiple XO at once. Can you add the remote to the new XOA and open a ticket ?
-
@florent Good morning @florent
I once again have to thank you guys for your amazing support (even in a case like this). I have added the 2 remotes to our paid enterprise version (it's added verbatim as per our community version).
Other info:
- Backups are setup as incremental
- Backups run either daily or weekly (2 backup jobs) but both configured the same
- 1 concurrent backup
- 2 Backup retention
I will open a ticket now, thank you!
-
@mauzilla the problem was with stales
cache.json.gzfile
we clean everything up with @Bastien-Nollet , and now you can see the old backups in the UI. 5 of your vm take the most room, it should be easy to clean themThen we'll add a an additional cache cleaning task as a last line of defense against
the dark artsbroken cache -
@florent you guys are absolute geniuses, there isn't a company in the world that matches your quality support.
I have a question though, say I have my backup set with 2 retentions on delta, and we do a full backup say each 20 backups. Am I right to assume that when the full backup occurs (so after 20 backups), in theory, there will be 2 full sets on the backup storage?
Example
Day 19: Full.vhd delta.vhd On day 20: oldfull.vhd (which is a merge of the day 19 full + delta) newfull.vhd (which is the new VM) Day 21: full.vhd (which is now the old newfull.vhd) delta.vhd (delta for day 21)If so, that means that if we have large VM's (some are 2.5TB in size), there will come a time that that VM will use up double it's size on the backup storage.
Lastly, as we will be moving to XCP Pro + support in January, we want to move our backups from the now historical / community edition to the new one. I know at some point I saw you had moved to NBD backups and there is also an option to "test" the backups. Would this then make periodical full backups irrelevant as there would be no need to worry about backup corruption over time?
-
@mauzilla thanks
that was also the first ticket of @Bastien-NolletYes, when you make a key backup (full) it will take the double the space till we can delete the older key one.
Maybe you could use an advanced feature of healthcheck : https://xen-orchestra.com/docs/backups.html#backup-health-check
It means you will need more space on a host ( can be a spare/low performance), but it will restore the VM and launch a script to check integrity. That way you could be confident in not enforcing a key backupWhen you move your backups job, you should use a export and import config, that way the uuid will stay the same, and it won't force full backups
NBD backup have some advantages (performance, CPU usage during backup), but it's not safer, since we are already confident on the legacy export, but sometimes, network, disk or even memory are lying.
-
I'm back on this one, we've setup a test bench with a similar card, and can confirm we dont even see the interface anymore upon booting, and during boot we get the following:
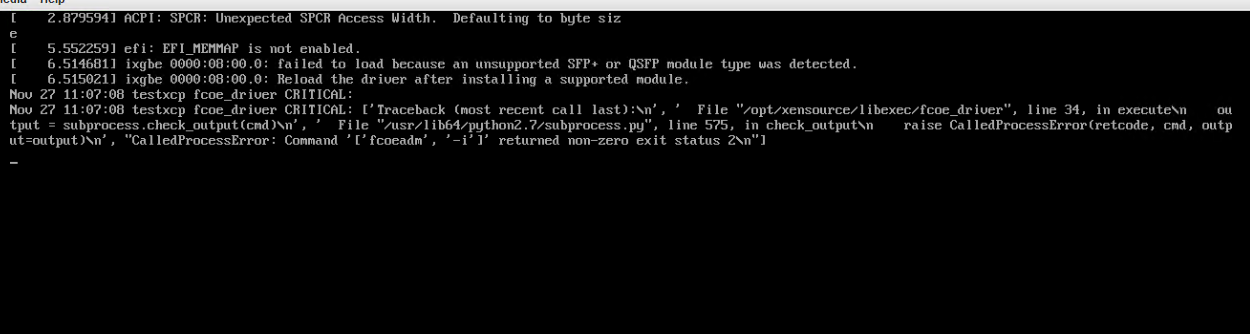
As there is a flag we can set, I am following this guide but not sure if this is applicable to the filesystem of XCP (for one there is no /etc/default/grub file)
https://www.serveradminz.com/blog/unsupported-sfp-linux/
Anyone able to assist in which file I would need to set the "Fix the issue permanently" part?
-
@mauzilla Is this message intended for this topic ?
-
Sounds off-topic indeed
")
-
@olivierlambert whoops! Well spotted
Will post in the real one
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login