CBT: the thread to centralize your feedback
-
And only after migrating the VM from a host to another, without changing its SR?
-
@olivierlambert Correct. The VM in question is on a NFS 4 SR. The next backup run will run without the error for as long as it stays on that host, however if i move it again the process repeats it self.
We are running paid XOA so if it helps i can enable a support tunnel for you guys to take a look at logs. However we have quite a few nightly backups now so not sure if the logs will have rotated. Either way its in our test environment so we can run the job anytime to generate fresh data.
-
That's weird, I'm using RPU in our prod so the VM are moving, but the VDI doesn't change. Anyway, another test to try internally
")
-
@olivierlambert we do not see this error in relation to migration, they just happen at a random situation. I have seen issues with cbt and multidisk vms, could it be that these are multi disk vms?
-
@rtjdamen Yes the VM i have been testing with above is a multi disk VM. I will do some testing with a single disk VM and see if that makes a difference.
-
@flakpyro this issues we saw were only happening on nfs and multidisk vms. The error was cbt was invalid if i am correct. This is not a xoa error but we saw it on my 3th party backup tool also using cbt
-
@rtjdamen After testing with both single disk VMs and multi disk i am seeing it on both. However it is much more common on multi disk VMs.
-
@flakpyro are u able to test it on iscsi?
-
@rtjdamen I dont not have any iscsi luns mapped to our hosts to test with. We went all in with NFS from iscsi as we moved from ESXi to XCP-NG.
-
After the CBT feature was added to the backup method, The error "VDI must be free or attached to exactly one VM" was occurring on our system. Today I upgraded XO to the e15f2a1 and tried taking full and delta backups with Continuous Replication. Now everything works fine.
NBD connection enabled, NBD+CBT backup enabled, XCP-ng 8.2, CR backup from FC storage to NFS storage. -
Great news! Other similar feedback in here?
-
@olivierlambert can’t check, running on xoa.
-
It will be available in 12 days then
-
@olivierlambert indeed haha, most things work like a charm, some issues but i know florent is still working on them.
-
Yes, as you can see in here, we are fixing most of the remaining issues to be ready on next week for our next release
-
So i have had good luck with NBD+CBT enabled for around the last week, however "Purge snapshot data when using CBT" causes me a number of issues unfortunately especially after a migration from one host to another with a shared SR as reported above. Hoping to see that fixed in the next release coming soon!
Recently I've discovered that it seems the coalesce process with "purge snapshot data" enabled does something our NFS storage array does not like. If a coalesce process with "Purge snapshot data when using CBT" enabled runs for too long of time the NFS server will start dropping connections. I have had this happen a few times last week and have not been able to explain it. Is the process quite different from the standard coalesce process? Trying to come up with something to explain why the array gets so angry!
I have a case open with our storage vendor and they pointed out that the client gets disconnected due to expired NFS leases when this happens. It might be a coincidence this happens during backup runs, if it continues to happen i plan to try NFS3 instead of NFS4.1 as well but something i thought i'd report!
-
i try to migrate VDIs to another storage. After 4 hours no one is migrated, new tasks run and close in loop.
-
I think a fix is coming very soon in master by @florent
-
Sadly the latest XOA update does not seem to resolve the "falling back to base" issue for me which occurs after migrating a VM from one host to another. (Using a shared NFS3 SR)
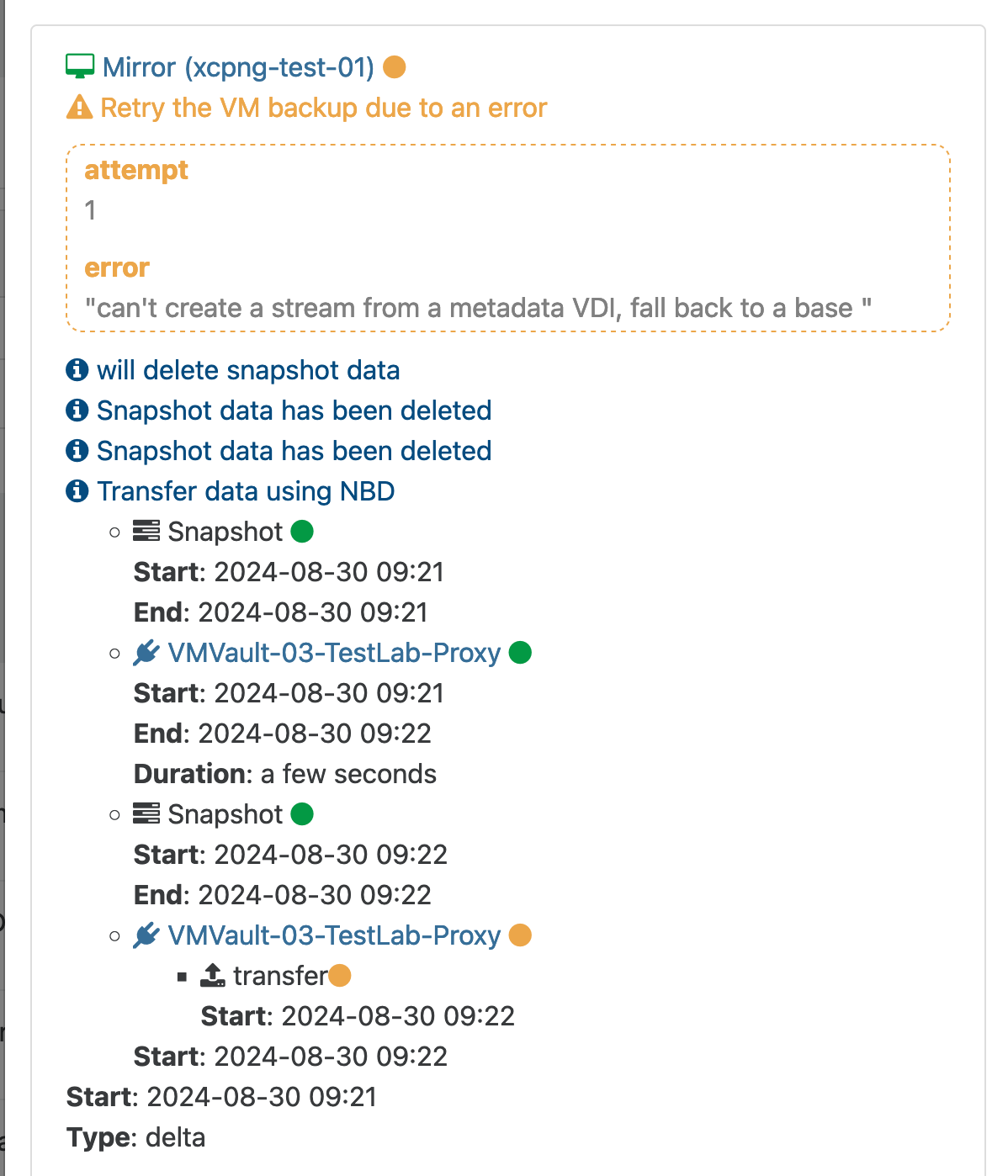
-
Can you bring the entire log please? We cannot reproduce the issue
 This should NOT happen if the VDI UUID is the same.
This should NOT happen if the VDI UUID is the same.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login