Nvidia P40s with XCP-ng 8.3 for inference and light training


-
Being curious about Large Language Models (LLMs) and machine learning, I wanted to add GPUs to my XCP-ng homelab. Finding the right GPU in June 2024 was not easy, given the numerous options and constraints, including a limited budget. My primary setup consists of two HP ProDesk 600 G6 running my 24/7 XCP-ng cluster with shared storage. My secondary setup features a set of Dell R210 II and Dell R720 servers, which I use for memory-intensive tasks. The Dell R720 can hold up to two full-sized GPU which lead to my first requirement: a GPU must fit into the Dell R720.
With R720 compatibility as a requirement, gaming GPUs (RTX 2080, 3080/3090, 4080/4090) were not an option. Additionally, they are expensive and do not all come with a lot of VRAM memory. But I admit that those are more powerful compared to what I came up with.
Since I want to test different LLMs with various parameter sizes, my minimum memory size requirement was 24GB VRAM. That clearly reduced the GPU options again, even for compatible low power (~70W) GPUs like the Nvidia RTX A2000 (12GB) or the Nvidia Tesla T4 (16GB).
My budget limit for getting started was around €300 for one GPU. That narrowed down my search to the Nvidia Tesla P40, a Pascal architecture GPU that, when released in 2016, cost around $5,699. In Europe, the P40 is available on Ebay for around €300 to €500, and I was very lucky to get two P40s for around €510 in total. Seeing two P40s on Ebay in the US for $299 with no delivery option for Europe was a painful experience though.
However, I had to make two compromises with the P40, which may be a problem in the future. First, the P40 is lacking Tensor Cores, which are essential for deep learning training compared to FP32 training. Additionally, the P40 is limited by its CUDA compute capability of 6.1, which is lower than that of newer GPUs like the H100 (9.0). At some point, software tools might stop supporting the P40.
To install a second GPU I had to swap the Dell R720 riser card #3 from 2 PCIe x8 slots with a 150W power connector to a 1 PCIe x16 slot with a 225W power connector. Like the K80/M40/M60/P100 the P40 has a 8-pin EPS connector, so you need a special power cable that can be sourced from Ebay. Using the standard Dell general-purpose GPU cable risks damaging the GPU or motherboard. Yesterday, the last part arrived so today is install day.

The process of swapping riser #3, installing the two P40 GPUs, and connecting the power cables was straightforward.. During boot, the server checks PCI devices and updates the inventory, which might take some minutes. After the initial fan ramp-up, the fan speed dropped back to normal and the Dell R720 idles at about 126W with both GPUs installed.

Next step was installing and updating XCP-ng 8.3 beta, which was as easy as installing the GPUs. Adding the host to XO from source and activating the PCI pass-through in the hosts advanced view required a reboot, but after that I could setup an Ollama VM to run LLMs and another Open WebUI VM to chat with the LLMs. With 48 GB of VRAM, I can run
llama3-70bwith some headroom and about 6 tokens/sec whilellama3-8bis much smaller and answers with 23 tokens/sec on this setup.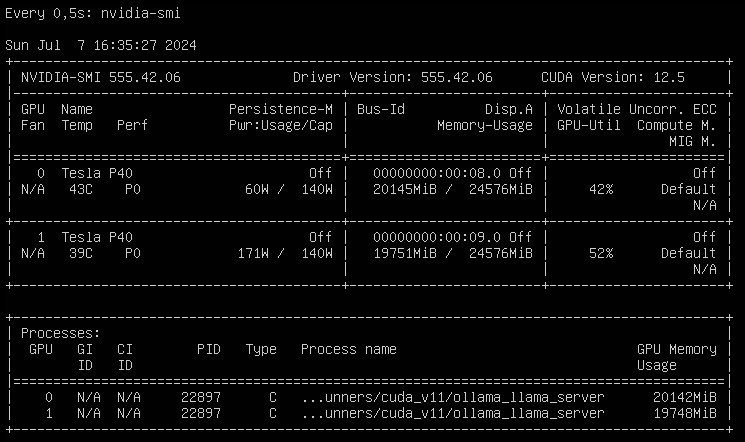
So what are the next steps? On one hand, I want to setup a development environment for
Phytonand API based usage of LLMs (not only local LLMs, but also cloud based LLMs like ChaGPT or Claude). That will be fun, since I have zero experience with that. On the other hand, I will setup more GPU supported services like Perplexica or AUTOMATIC1111 or whisper. Apart from that, I will also try to improve my prompt engineering skills and learn about LLM multi agent frameworks.The best thing on this setup is that XCP-ng 8.3 beta provides a robust foundation for running Large Language Models (LLMs) and other AI workloads on one machine. Looking forward to the release candidate!
-
@gskger Nice. I am curious too as there are some many opensource LLM available nowadays to test out.
-
Love this, planning to eventually do something similar, mostly running LLMs on my desktop right now but would much prefer to properly host them instead.
-
Nice setup! I played with Ollaama myself. I might try to use the UI and make it run for our company internally
")
-
I just added a P4 to one of my hosts for exactly this. My servers can only handle low-profile cards, so the P4 fits. Not the most powerful of GPU's but I can get my feet wet.
-
 G gskger referenced this topic on
G gskger referenced this topic on
-
G gskger referenced this topic on
-
G gskger referenced this topic on
-
Thank you gskger for this inspiring post.
With help of a dremel and gentle force it also is possible to have the same setup with Dell R720XD. Just need to remove the rear drive bays and "widen" the single PCI slot to dual and all is good.




Just two notes which are important : The pinout of Dell riser card power connector is different from the Tesla P40 power input connector. But the connector on the power cable has two same ends. If you connect wrong way then the system will refuse to start and PSUs will blink in yellow/amber color because there is a short circuit (thank you dell for having this security integrated). See picture below. The end with 5x black(GND) is riser card side, the end with 4x black is Tesla side.

Next thing you might consider is creating a small docker system for controling the fans so there is no heat issue. (see https://github.com/Gibletron/Docker-iDrac-Fan-Control)
Next thing I will try to setup is "NVIDIA Container Toolkit" so it will be possible to share the GPUs along Plex, Ollama, Frigate NVR.
-
@Vinylrider Cool modification, but definitely not for the faint-hearted. Is it difficult to cut through the metal? Interestingly, in your setup, the end with the 4x black wires connects to the riser card. With my setup / cable, it's the 5x black wire end that plugs into the riser card. Mh, I saw that on youtube but never gave it much thought until now.
Since my R720s can’t natively monitor GPU temperatures of this GPUs to adjust fan speeds, I’m planning to create a script that reads both CPU and GPU temperatures and dynamically controls the fan speed through iDRAC. My R720s, equipped with two Intel Xeon CPU E5-2640 v2 processors (TDP of 95W), don’t typically run too hot though, even under load.
Here’s a quick temperature chart I’ve put together for my setup, showing CPU and GPU temperatures at various fan speeds (adjusted via iDRAC) - both at idle and under load:
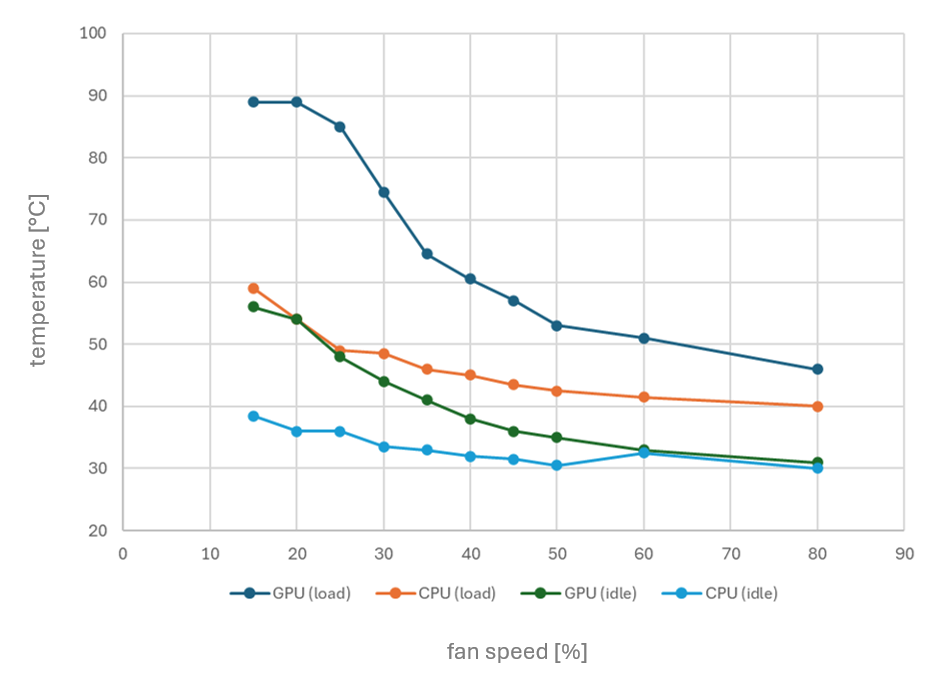
With the automatic fan control at 45%, both CPU and GPU temperatures remain comfortably below 60°C, even under load.
-
Thank you for your review. You are right. 5x black is the riser side. I have corrected my post!
The modification was actually easier to do than expected. It took 3 hours to shut down the system, open everything, exchange the full-size USB hub PCIe and LAN card with low-profile ones, do the modification work, insert the Teslas, and start up the system again. My biggest worry was whether I would have to remove the mainboard, but luckily I didn't have to. For the metal drive cage part, you just need to hammer away 3 rivets with a screwdriver (and a hammer). Then this metal part can be bent up. Just move it left/right approximately 50 times so the metal gets weak and finally breaks off completely from the case. The dremel work was just a few cuts and was done in seconds because the metal is not really hard. I just had to ensure the mainboard/server was protected with layers of foil and carpet and have a vacuum cleaner to immediately remove all metal dust to prevent problems later on. But even if a problem occurred, the Dell parts are so indecently cheap to get on eBay. A whole R720 or R720XD server for 150 EUR. Also, I replaced the 750W PSUs with 2x 1100W ones for just 42 EUR (including shipping) and added a surplus 32GB RAM for 30 EUR. These servers truly give you the best bang for the buck.
Your temperature observations are very interesting. I also already wondered how to make fan speed dependent on GPU temperature. Please publish your script once ready! I also do not think there might be much of a heat problem with standard daily workload. But what will happen if you train stuff with, e.g., PrivateGPT for some days with full load?
-
Update :
The cards only started working after enabling I/O Memory mapping above 4G in BIOS. And it was not possible to use GPU-Passthrough of XCP-NG because it seems to be limited to just one card. Instead I enabled PCI passthrough for both PCI devices to a virtual machine. And there you can use Nvidia Container Toolkit to have a docker environment which shares the GPU(s) among each other. Also tested latest LLama 3.3 70b model already which works very good. -
@Vinylrider Lol i like this
getting stuff done customized haha! Great pictures.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login