Dev diaries #1: Analyzing storage perf (SMAPIv3)
-
SMAPIv3: results and analyze
After some investigation, it was discovered that the SMAPIv3 is not THE perfect storage interface. Here are some charts to analyze:
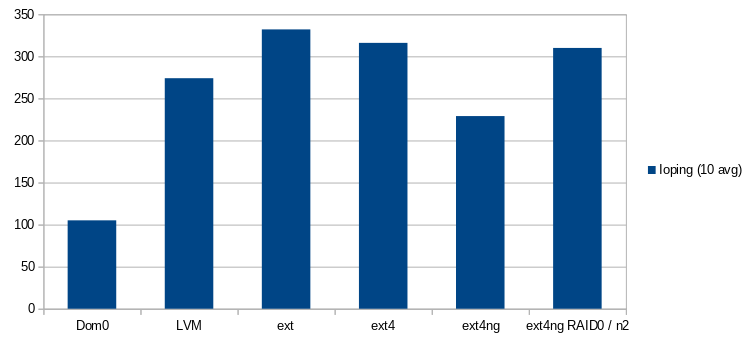
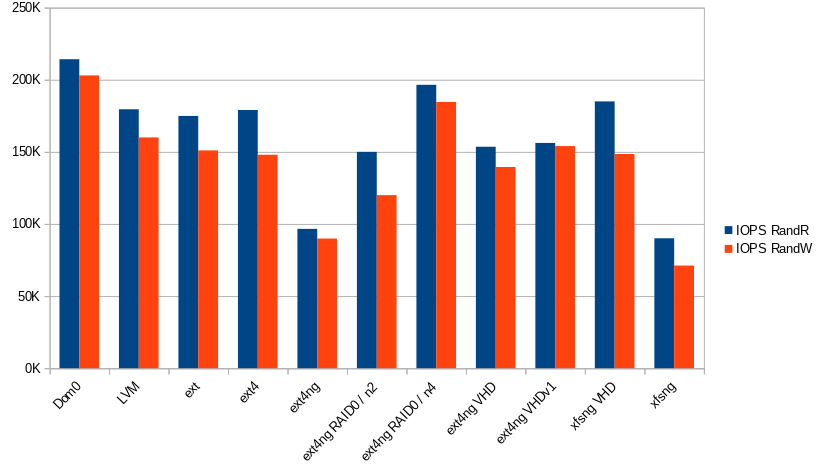
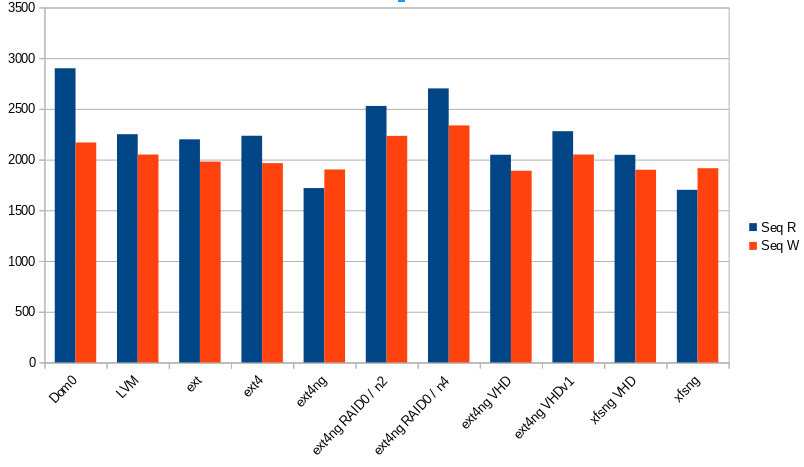
Yeah, there are many storage types:
- lvm, ext (well known)
- ext4 (storage type added on SMAPIv1)
- ext4-ng (a new storage type added on SMAPIv3 for this benchmark and surely available in the future)
- xfs-ng (same idea but for XFS)
You can notice the usage of RAID0 with ext4-ng, but it's not important for the moment.
Let's focus on the performance of ext4-ng/xfs-ng! How can we explain these poor results?! By default the SMAPIv3 plugins like gfs2/filebased added by Citrix use qemu-dp. It is a fork of qemu, it's also a substitute of the tapdisk/VHD environment used to improve performance and remove some limitations like the maximum size supported by the VHD format (2TB). QEMU supports QCow images to break this limitation.
So, the performance problem of the SMAPIv3 seems related to qemu-dp. And yes... You can see the results of the ext4-ng VHD and ext4-ng VHDv1 plugins, they are very close to the SMAPIv1 measurements:
- The ext4-ng VHDv1 plugin uses the O_DIRECT flag + a timeout like the SMAPIv1 implementation.
- The ext4-ng VHD plugin does not use the O_DIRECT flag.
Next, to validate a potential bottleneck in the qemu-dp process, two RAID0 have been set up (one with 2 disks and an other with 4), and it seems interesting to see a good usage of the physical disk! There is one qemu process for each disk in our VM, and the disk usage is similar of the performance observed in the Dom0.
For the future
The SMAPIv3/qemu-dp tuple is not totally a problem:
- A good scale is visible with the RAID0 benchmark.
- It's easy to add a new storage type in the SMAPIv3. (Two plugin types: Volume and Datapath automatically detected when added in this system. See: https://xapi-project.github.io/xapi-storage/#learn-architecture)
- The QCow2 format is a good alternative to break the size limitation of the VHD images.
- A RAID0 on the SMAPIv1 does not improve the I/O performance contrary to qemu-dp.
Next steps:
- Understand how qemu-dp is called (context, parameters, ...).
- Find the bottleneck in the qemu-dp.
- Find a solution to improve the performance.
-
qemu-dp: context and parameters
Here are some new charts. Make sure you understand the global QCOW2 image structure. (See: https://events.static.linuxfound.org/sites/events/files/slides/kvm-forum-2017-slides.pdf)
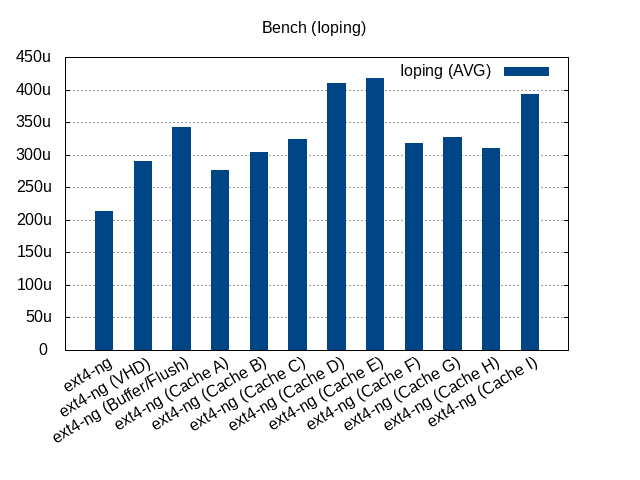
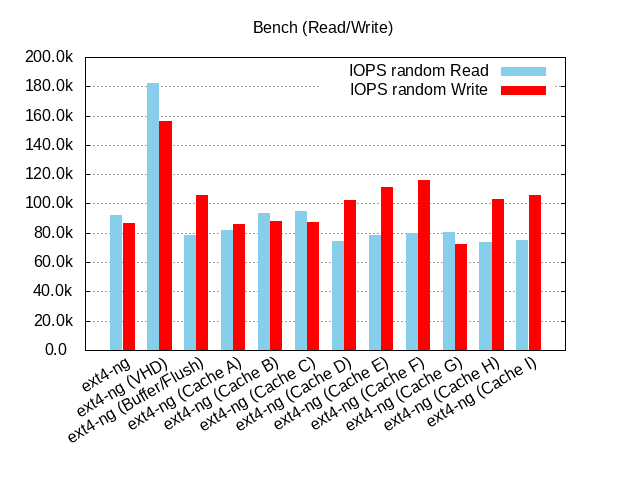
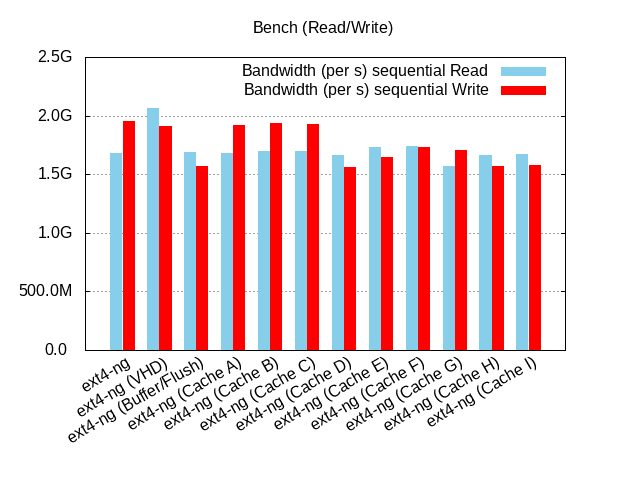
More explicit labels
 :
:- ext4-ng: qemu-dp with default parameters (O_DIRECT and no-flush)
- ext4-ng (VHD): tapdisk with VHD (no O_DIRECT + timeout)
- ext4-ng (Buffer/Flush): no O_DIRECT + flush allowed
- Cache A: L2-Cache=3MiB
- Cache B: L2-Cache=6.25MiB
- Cache C: Entry-Size=8KiB
- Cache D: Entry-Size=64KiB + no O_DIRECT + flush allowed
- Cache E: L2-Cache=8MiB + Entry-size=8KiB + no O_DIRECT + flush allowed
- Cache F: L2-Cache=8MiB + Entry-size=8KiB + no O_DIRECT
- Cache G: L2-Cache=8MiB + Entry-size=8KiB
- Cache H: L2-Cache=8MiB + Entry-size=16KiB + no O_DIRECT
- Cache I: L2-Cache=16MiB + Entry-size=8KiB + no O_DIRECT
These results where obtained with an optane (nvme). We can see a better random write performance with the F configuration instead of using the default qemu-dp parameters and the ioping is not so bad. But it's not sufficient compared to tapdisk.
So like said in the previous message, it's the moment to find the bottleneck in the qemu-dp process.
-
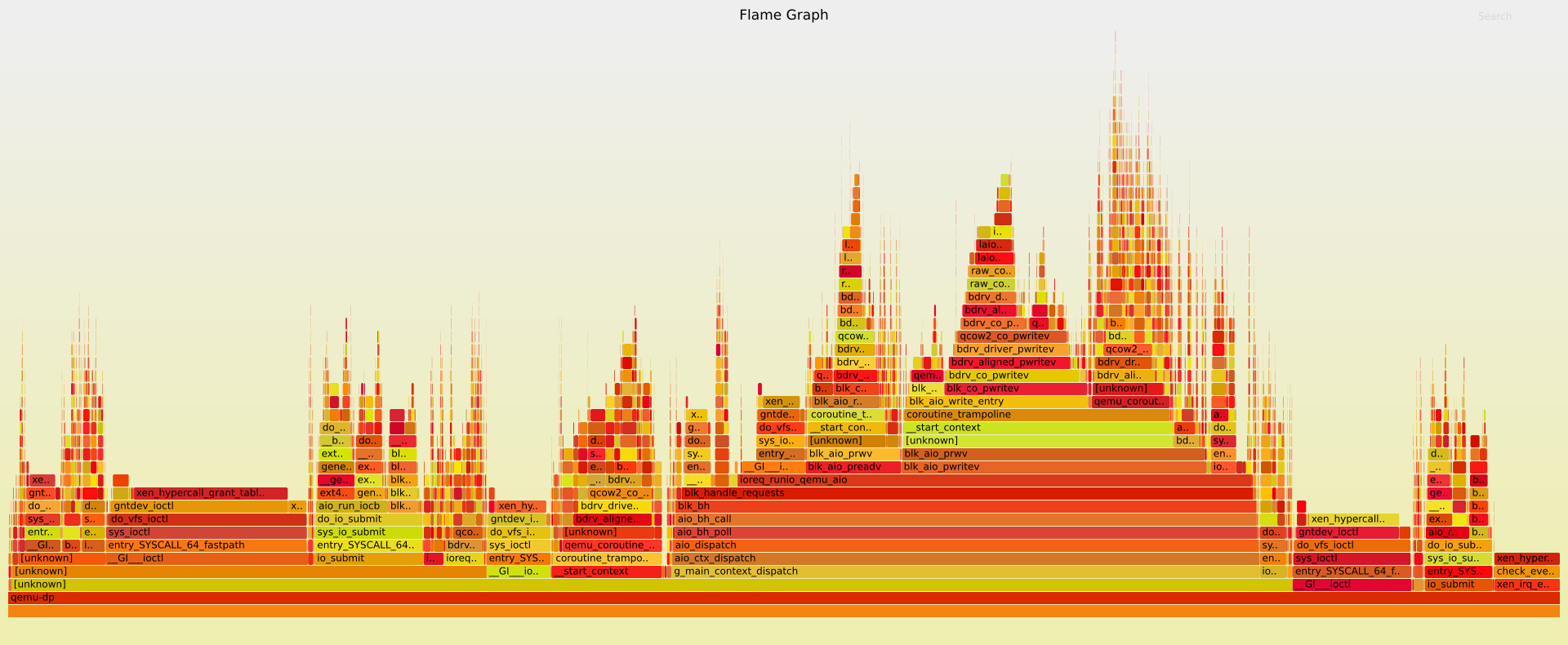
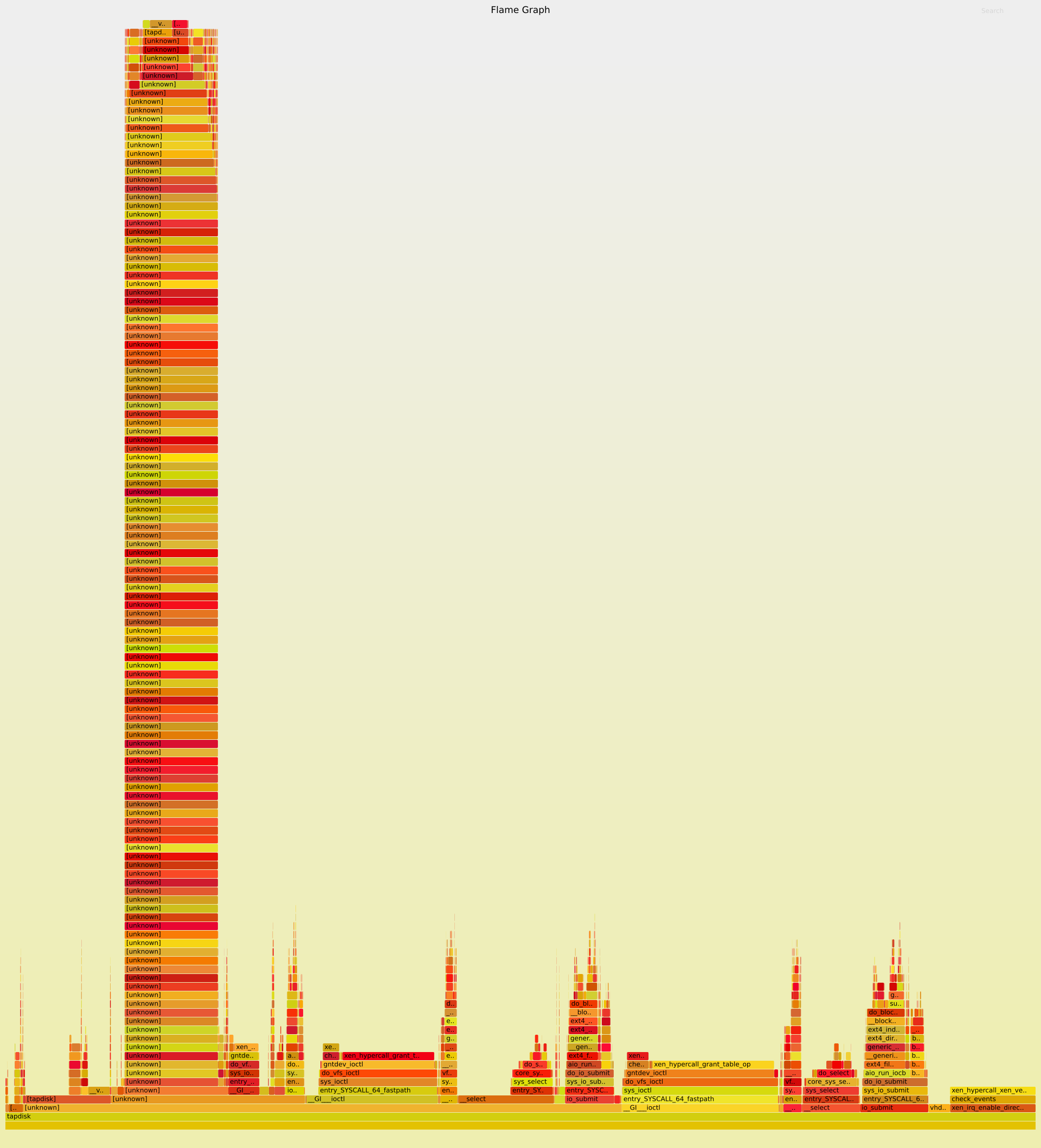
qemu-dp/tapdisk and CPU Usage per function call
Thank you to flamegraph.
") (See: http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html)
(See: http://www.brendangregg.com/FlameGraphs/cpuflamegraphs.html)
Analysis and improvements in a future message!qemu
tapdisk
-
Wow... however I got lost.
This is far too high to my knowledge.However... are you comparing local disk with local disk (in order to avoid networks related bottleneck)?
-
All tests are done with a local NVMe Optane drive, no network anywhere.
-
@ronan-a what call is causing such a deep call stack in tapdisk? All of them look to be "unknown," including its direct parent after tapdisk itself.
-
Tapdisk is just palin not good as a storage control mechanism, IMO. There's only so much you can pull out of it.
-
@Kalloritis I'm not sure about that. You see a stack of "unknown" functions because the tapdisk binary was not compiled with all debug symbols, contrary to qemu-dp.
And I'm waiting for the next XenServer release before continuing this diary.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login