Internal error: Not_found after Vinchin backup
-
You shouldn't be nervous for a home lab
") You have backups right?
You have backups right?It means there's 34 VDIs that will be coalesced in the future. You can check if coalesce is working by looking at that number 34 and checks if it goes down.
If it doesn't, check the SM log to understand what's going on. Also, does a SR scan works?
-
@olivierlambert So the count has gone down to 25. The host that all of these servers were on of course disconnected from the SR again. Is there a way to run the Garbage Collection and/or Coalesce on one host only? I was thinking if I move the VMs one at a time over to a host that has nothing else on it I could run that against a powered off VM to clean it up. Then move it to another host and power it back on. Then to the next and next until it's all cleaned up. Does that make sense?
-
The number is going down: excellent news! Just be patient now
I would advise just to let it run, trying to outsmart the storage stack almost never works

-
@olivierlambert What entry would I look for to see a successful and/or failed Coalesce? I'm looking at the SMlog.
-
Usually "grep -i exception" on
/var/log/SMlogwill report failures. But as long you see the number going down, it's OK. -
@olivierlambert Thank you. It's just that the host that some of these VMs are on is disconnecting the SR from the host. So I have been shutting them down and moving them to another host and powering back on. I was just hoping I could finish the coalesce for them manually to prevent unknown downtimes.
-
@olivierlambert Should I not worry about deleting any more of the extra 0B disk listed on the SR page Disks tab and just watch the number on this page?
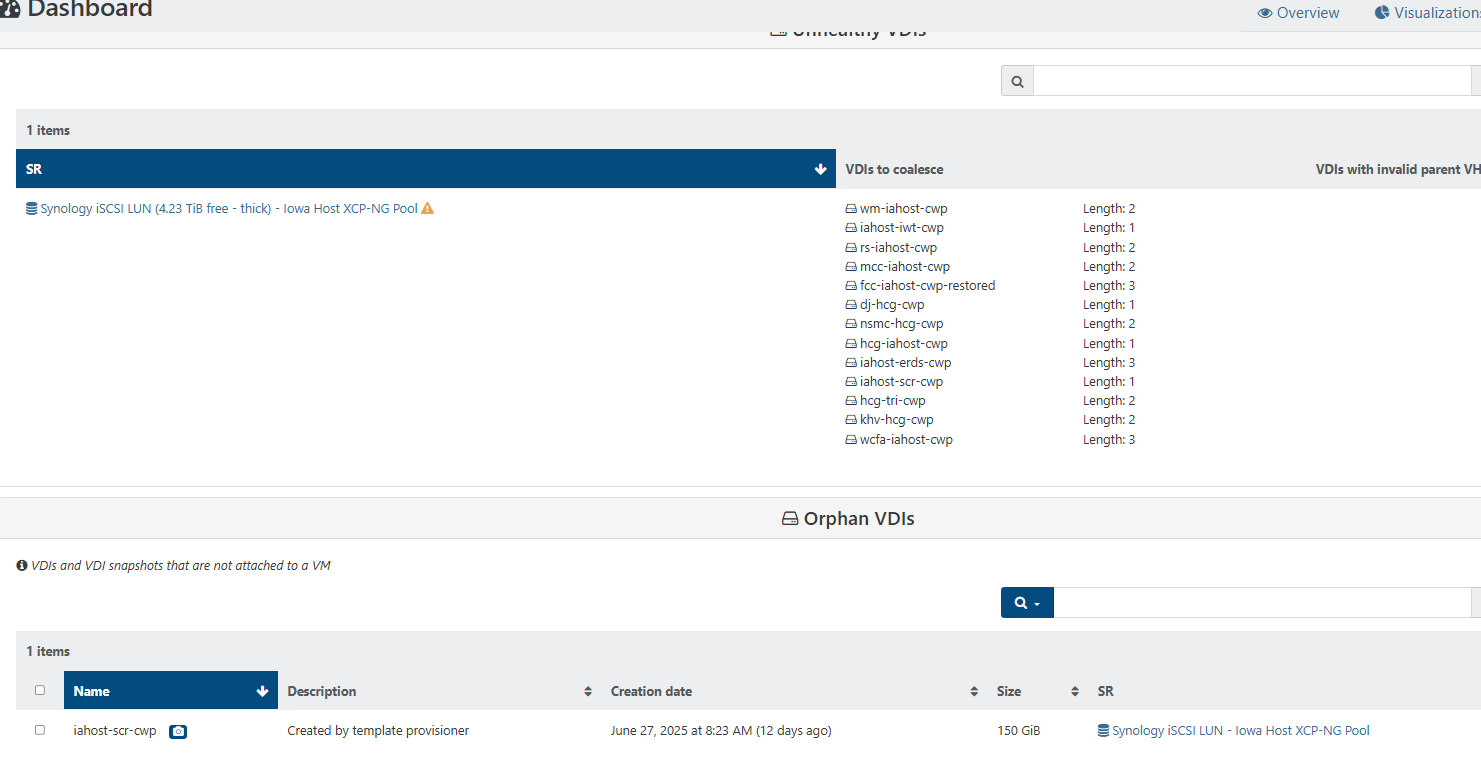
-
You have a rather long chain now, but it should coalesce anyway
-
Well I have not had any issues since the 9th which is when I disabled Vinchin Backups. However, my count did not go down since then either.
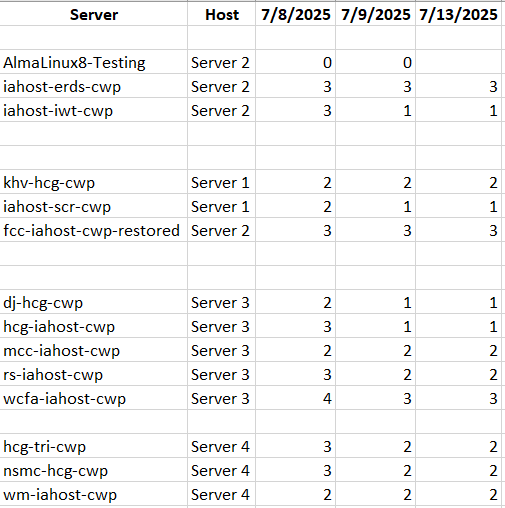
-
So you have to dig in the SMlog to check what's going on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login