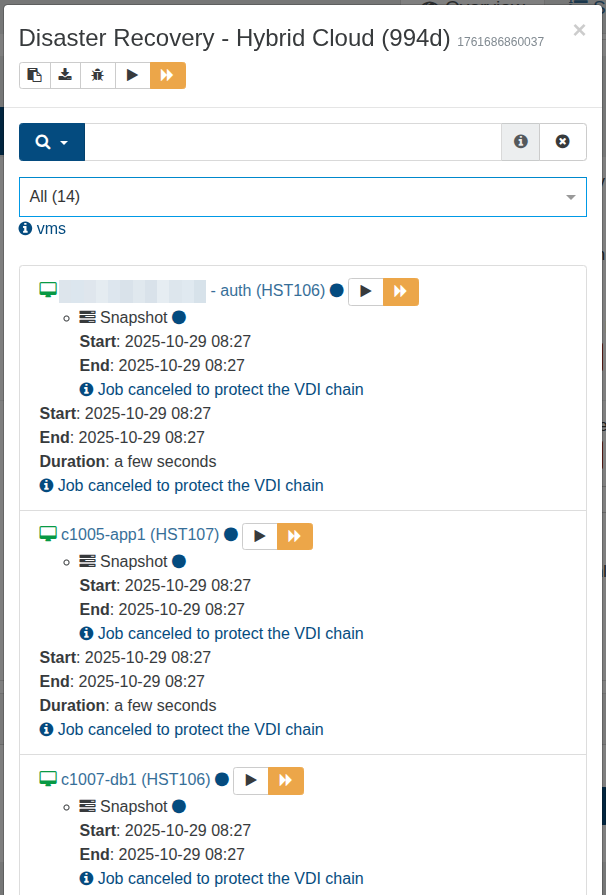
Job canceled to protect the VDI chain


-
I spoke too soon. The backups started working however the problem has returned.
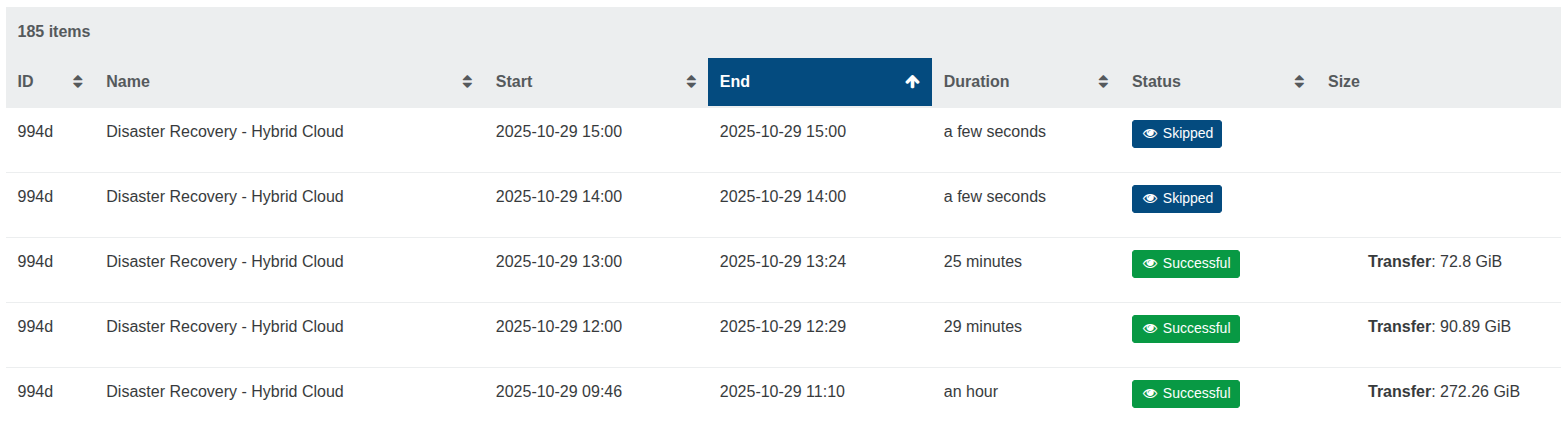
I do see 44 items waiting to coalesce. This is new as these would coalesce faster previously without causing this issue.
Is there a reason the coalesce is taking longer now or is there a way I can add resources to speed up the process?
-
I have the following entry in the logs, over and over. Not sure if this is a problem:
Oct 29 15:25:08 HST106 SMGC: [1009624] Found 1 orphaned vdis Oct 29 15:25:08 HST106 SM: [1009624] lock: tried lock /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/sr, acquired: True (exists: True) Oct 29 15:25:08 HST106 SMGC: [1009624] Found 1 VDIs for deletion: Oct 29 15:25:08 HST106 SMGC: [1009624] *d4a17b38(100.000G/21.652G?) Oct 29 15:25:08 HST106 SMGC: [1009624] Deleting unlinked VDI *d4a17b38(100.000G/21.652G?) Oct 29 15:25:08 HST106 SMGC: [1009624] Checking with slave: ('OpaqueRef:16797af5-c5d1-08d5-0e26-e17149c2807b', 'nfs-on-slave', 'check', {'path': '/var/run/sr-mount/be743b1c-7803-1943-0a70-baf5fcbfeaaf/d4a17b38-5a3c-438a-b394-fcbb64784499.vhd'}) Oct 29 15:25:08 HST106 SM: [1009624] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/sr Oct 29 15:25:08 HST106 SM: [1009624] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/running Oct 29 15:25:08 HST106 SMGC: [1009624] GC process exiting, no work left Oct 29 15:25:08 HST106 SM: [1009624] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/gc_active Oct 29 15:25:08 HST106 SMGC: [1009624] In cleanup Oct 29 15:25:08 HST106 SMGC: [1009624] SR be74 ('Shared NAS002') (166 VDIs in 27 VHD trees): no changes Oct 29 15:25:08 HST106 SM: [1009624] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/running Oct 29 15:25:08 HST106 SM: [1009624] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/gc_active Oct 29 15:25:08 HST106 SM: [1009624] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/sr -
How long roughly before coalesce is done? Coalesce is a storage task directly done by XCP-ng, XO is just witnessing it.
It's normal to have disks to coalesce after snapshot removal.
-
@olivierlambert if its at XCP level, is there a ratio where storage access performance should be especially monitored ?
i guess that 500 VMs desnapshoted on 1 host is managed differently than 500VMs on 50 hosts.
but if all hosts are on same shared storage... performance constraint ?
-
Coalescing is indeed generating some IOPS, latency is in general the most visible impact on it. However, it's managed per storage, regardless the number of VDIs, they are coalesced one by one.
-
@olivierlambert sor for high number of VMs, there is a point in time where you should be aware of not doing DR too frequently to let coalesce proceed.
50VMs in a DR job, every hour, if coalesce takes 2min by VM, it didnt finish when the next DR is starting ?i'm looking for the edge case
-
This is entirely dependent of your setup, there's no universal rule. But thanks to XO skipping the job, you can adapt your configuration to reduce the number of times it happens.
-
As per yesterday, the backups are still being "Skipped". Checking the logs I see the following message being repeated:
Oct 30 08:30:09 HST106 SMGC: [1866514] Found 1 orphaned vdis Oct 30 08:30:09 HST106 SM: [1866514] lock: tried lock /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/sr, acquired: True (exists: True) Oct 30 08:30:09 HST106 SMGC: [1866514] Found 1 VDIs for deletion: Oct 30 08:30:09 HST106 SMGC: [1866514] *d4a17b38(100.000G/21.652G?) Oct 30 08:30:09 HST106 SMGC: [1866514] Deleting unlinked VDI *d4a17b38(100.000G/21.652G?) Oct 30 08:30:09 HST106 SMGC: [1866514] Checking with slave: ('OpaqueRef:16797af5-c5d1-08d5-0e26-e17149c2807b', 'nfs-on-slave', 'check', {'path': '/var/run/sr-mount/be743b1c-7803-1943-0a70-baf5fcbfeaaf/d4a17b38-5a3c-438a-b394-fcbb64784499.vhd'}) Oct 30 08:30:09 HST106 SM: [1866514] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/sr Oct 30 08:30:09 HST106 SM: [1866514] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/running Oct 30 08:30:09 HST106 SMGC: [1866514] GC process exiting, no work left Oct 30 08:30:09 HST106 SM: [1866514] lock: released /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/gc_active Oct 30 08:30:09 HST106 SMGC: [1866514] In cleanup Oct 30 08:30:09 HST106 SMGC: [1866514] SR be74 ('Shared NAS002') (166 VDIs in 27 VHD trees): no changes Oct 30 08:30:09 HST106 SM: [1866514] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/running Oct 30 08:30:09 HST106 SM: [1866514] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/gc_active Oct 30 08:30:09 HST106 SM: [1866514] lock: closed /var/lock/sm/be743b1c-7803-1943-0a70-baf5fcbfeaaf/srIt appears the unlinked VDI is never deleted. Could this be blocking and should this be deleted manually?
Deleting unlinked VDI *d4a17b38(100.000G/21.652G?)In regards to the following line, I can identify the VM UUID however is the 2nd UUID a snapshot? (d4a17b38-5a3c-438a-b394-fcbb64784499.vhd)
Oct 30 08:30:09 HST106 SMGC: [1866514] Checking with slave: ('OpaqueRef:16797af5-c5d1-08d5-0e26-e17149c2807b', 'nfs-on-slave', 'check', {'path': '/var/run/sr-mount/be743b1c-7803-1943-0a70-baf5fcbfeaaf/d4a17b38-5a3c-438a-b394-fcbb64784499.vhd'}) -
Appears to be the same as:
https://xcp-ng.org/forum/topic/1751/smgc-stuck-with-xcp-ng-8-0?_=1761802212787It appears this snapshot is locked by a slave host that is currently offline.
Oct 30 08:30:09 HST106 SMGC: [1866514] Checking with slave: ('OpaqueRef:16797af5-c5d1-08d5-0e26-e17149c2807b', 'nfs-on-slave', 'check'When using shared storage how does a snapshot become locked by a host?
Is the scenario where a slave host is offline how can this lock be cleared?
-
Can you start this host? If it's online, XAPI can't tell if it's really off or maybe disconnected from the management but still connected to the shared storage and creating a potential data corruption.
-
Host started and issue resolved.
-
 O olivierlambert marked this topic as a question on
O olivierlambert marked this topic as a question on
-
O olivierlambert has marked this topic as solved on
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login