Delta backup fails for specific vm with VDI chain error
-
mbt,
How are you copying the VM? Are you using XC or XO and are you doing a fast clone or a full copy? If you have the same problem as I do at the moment, using fast clone will not help your situation as it will not create a new tree for the VHD.
It does not surprise me that you are seeing the SMGC kick in. Some operations will ask the SM to re-scan the SR and this will also cause the SMGC to start. If you previously had a stuck job that "Exceptioned" the GC will try again, and if the VM is shutdown, it will be able to do a offline coalesce.
See if you can get a tree view of your VDI's and look for something that has a lot of indents in it.. What type of SR do you use? iSCSI or NFS?
~Peg
-
Hi Peg:
I did a full copy in XO.Coalescing of the vm's vdis is blocking the backup again.

I can tell from the log, that SMGC ist doing something. In htop I can also see the "vhd-util check" running at 100% cpu, then stopping, then a "vhd-util coalesce" runs and does the reading / writing.
When I wrote here last week, there was always only a "vhd-util check", no coalesce, until I did the VM copy.May it be the "vhd-util check" is taking too long? This is what I see consuming most of the time. The actual coalescing of maybe 100MB, 200 MB is done in a splitsecond.
How do I get a tree view of my vdis?
The system is a brand new 2x Intel Xeon Silver 4110 8Core, 2.1GHz. The sr is a local LVM sr and sits on a 4x 1.9TB SATA SSD hardware RAID and 128 GB RAM. Both pool members are identical.
Here is a part of the log as example:
Aug 27 10:29:55 rigel SMGC: [11997] Num combined blocks = 154287 Aug 27 10:29:55 rigel SMGC: [11997] Coalesced size = 301.938G Aug 27 10:29:55 rigel SMGC: [11997] Leaf-coalesce candidate: 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) Aug 27 10:29:55 rigel SMGC: [11997] Leaf-coalescing 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) -> *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:29:55 rigel SMGC: [11997] Got other-config for 7ef76d55[VHD](500.000G/170.450M/500.984G|ao): {} Aug 27 10:29:55 rigel SMGC: [11997] Single-snapshotting 7ef76d55[VHD](500.000G/170.450M/500.984G|ao) Aug 27 10:29:58 rigel SMGC: [11997] Single-snapshot returned: OpaqueRef:12365b17-46e6-4808-adeb-538ef12eed73 Aug 27 10:29:58 rigel SMGC: [11997] Found new VDI when scanning: c220c902-8cf7-4899-b894-15c4723b5973 Aug 27 10:29:58 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 27 10:29:58 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 27 10:29:58 rigel SMGC: [11997] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 10:29:58 rigel SMGC: [11997] *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:29:58 rigel SMGC: [11997] *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:29:58 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:29:58 rigel SMGC: [11997] Aug 27 10:29:58 rigel SMGC: [11997] Coalescing parent *c220c902[VHD](500.000G//172.000M|ao)Where it says "10:29:58 Coalescing parent" is, when the "vhd-util check" runs. Around 90 seconds later:
Aug 27 10:31:28 rigel SMGC: [11997] Removed vhd-blocks from *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:28 rigel SMGC: [11997] Set vhd-blocks = eJzt2sttwkAUBVCDkGARKS6BEihh0klKeYsUQgkpIaWklAAmWTgKKP7wyOQce2Fbnrl3a/lFAwAAwJw2L9kNgMguALWL7AKMFtkFGC4yw5eZ4QAAAAAAAHCfnqLtLtpmldsk024R2RWoWskuANy55+wC01tHdgPgpuI8GxhjNnl8Hbz07XAcvY/JBxigZBe4yvg0AAAwjUjO3ybn75PzAcgR3y7g/9if/7/NYDHXxtQjUlLL1wTt8PxN777bqfRfW54e/Tixezm/9D+QVqezGwRuL/fjL4hfvl/b+PPn/Mk2tQUAtxYj15emeZigBgAAAABQoQ8pNhSV for *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:28 rigel SMGC: [11997] Set vhd-blocks = (lots of characters) for *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:28 rigel SMGC: [11997] Num combined blocks = 154287 Aug 27 10:31:28 rigel SMGC: [11997] Coalesced size = 301.938G Aug 27 10:31:28 rigel SMGC: [11997] Running VHD coalesce on *c220c902[VHD](500.000G//172.000M|ao) Aug 27 10:31:31 rigel SMGC: [11997] Child process completed successfully Aug 27 10:31:31 rigel SMGC: [11997] Set vhd-blocks = (lots of characters) for *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:32 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): no changes Aug 27 10:31:32 rigel SMGC: [11997] Relinking 7ef76d55[VHD](500.000G//500.984G|ao) from *c220c902[VHD](500.000G//172.000M|ao) to *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:32 rigel SMGC: [11997] Set vhd-parent = 775aa9af-f731-45e0-a649-045ab1983935 for 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:32 rigel SMGC: [11997] Updated the vhd-parent field for child 7ef76d55-683d-430f-91e6-39e5cceb9ec1 with 775aa9af-f731-45e0-a649-045ab1983935 Aug 27 10:31:32 rigel SMGC: [11997] Reloading VDI 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:33 rigel SMGC: [11997] Got other-config for 7ef76d55[VHD](500.000G/162.434M/500.984G|ao): {} Aug 27 10:31:33 rigel SMGC: [11997] Single-snapshotting 7ef76d55[VHD](500.000G/162.434M/500.984G|ao) Aug 27 10:31:36 rigel SMGC: [11997] Single-snapshot returned: OpaqueRef:47f3c5e9-8ddb-4f27-8e7c-295c89db3026 Aug 27 10:31:36 rigel SMGC: [11997] Found new VDI when scanning: 78ab27a9-92a4-4b02-94a7-261283fde7c9 Aug 27 10:31:36 rigel SMGC: [11997] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): showing only VHD trees that changed: Aug 27 10:31:36 rigel SMGC: [11997] *43454904[VHD](500.000G//500.949G|ao) Aug 27 10:31:36 rigel SMGC: [11997] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 10:31:36 rigel SMGC: [11997] *775aa9af[VHD](500.000G//301.938G|ao) Aug 27 10:31:36 rigel SMGC: [11997] *78ab27a9[VHD](500.000G//164.000M|ao) Aug 27 10:31:36 rigel SMGC: [11997] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 10:31:36 rigel SMGC: [11997] Aug 27 10:31:36 rigel SMGC: [11997] Coalescing parent *78ab27a9[VHD](500.000G//164.000M|ao)And so on...
So yes, it seems like Olivier said, that the system is not coalescing fast enough. The most time seems to be spent in "vhd-util check". I assume that is a process that checks for changed blocks?
What I am not getting is:
Why is it too slow?
Why now?The vm has no heavier usage compared to the past years. It's been running without such problems on SAS HDDs with XCP-ng 7.x and Xenserver using XO before.
Btw. I'm seeing exceptions again (they were gone last week after the vm copy):
Aug 27 10:41:21 rigel SM: [31806] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:42:55 rigel SM: [571] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:42:58 rigel SM: [924] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:43:00 rigel SM: [1512] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:35 rigel SM: [2833] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:36 rigel SM: [3083] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:44:38 rigel SM: [3641] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:12 rigel SM: [4876] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:13 rigel SM: [5083] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! Aug 27 10:46:15 rigel SM: [5636] Ignoring exception for LV check: /dev/VG_XenStorage-f951f048-dfcb-8bab-8339-463e9c9b708c/7ef76d55-683d-430f-91e6-39e5cceb9ec1.cbtlog ! -
Do you have the same issue on the other host on its local SR?
-
I moved the vm last week to the other host and checked if the delta job worked but it didn't. But I didn't give it time to maybe coalesce. I'll migrate the vm and check that out.
One question for my understanding:
The line "Coalesced size = xxx" - does it mean how much of the vhd size is coalesced right now?
I can see that number in the logs slowly increasing over time.For example:
Aug 27 04:03:13 rigel SMGC: [11997] Coalesced size = 276.902G Aug 27 05:16:01 rigel SMGC: [11997] Coalesced size = 276.906G Aug 27 06:01:39 rigel SMGC: [11997] Coalesced size = 276.910G Aug 27 07:05:36 rigel SMGC: [11997] Coalesced size = 292.246G Aug 27 08:03:28 rigel SMGC: [11997] Coalesced size = 298.625G Aug 27 09:00:06 rigel SMGC: [11997] Coalesced size = 301.609G Aug 27 10:01:26 rigel SMGC: [11997] Coalesced size = 301.770G Aug 27 10:56:06 rigel SMGC: [11997] Coalesced size = 301.938GAnd I got 475 entrys from 4 a.m until now (11 a.m.).
FYI: There's a total of 12 VMs on both pool members, including the XO vm.
-
@Peg:
Not sure if this is the vdi tree you mentioned, but I get this when triggering a sr rescan in the log:
Aug 27 11:04:52 rigel SMGC: [28194] SR f951 ('rigel: sr') (28 VDIs in 9 VHD trees): Aug 27 11:04:52 rigel SMGC: [28194] 03035c65[VHD](40.000G//40.086G|n) Aug 27 11:04:52 rigel SMGC: [28194] 03190d28[VHD](10.000G//10.027G|n) Aug 27 11:04:52 rigel SMGC: [28194] *f74fa838[VHD](15.000G//14.633G|ao) Aug 27 11:04:52 rigel SMGC: [28194] a23e7cbd[VHD](15.000G//15.035G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *62feee6c[VHD](50.000G//36.227G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 667cf6a9[VHD](50.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 19333817[VHD](50.000G//50.105G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *43454904[VHD](500.000G//500.949G|ao) Aug 27 11:04:52 rigel SMGC: [28194] dcdef81b[VHD](500.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *775aa9af[VHD](500.000G//301.961G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *894dbc3a[VHD](500.000G//21.406G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 7ef76d55[VHD](500.000G//500.984G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *cb9ff226[VHD](40.000G//34.605G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *2a99181e[VHD](40.000G//4.238G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 6371a662[VHD](40.000G//40.086G|ao) Aug 27 11:04:52 rigel SMGC: [28194] e5af497f[VHD](40.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] b70f6e7f[VHD](40.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *0494da11[VHD](100.000G//2.207G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 63b37e30[VHD](100.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 2ca68323[VHD](100.000G//100.203G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *d80f9f3d[VHD](70.000G//28.410G|ao) Aug 27 11:04:52 rigel SMGC: [28194] bfb778e9[VHD](70.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] *f56b9b4e[VHD](70.000G//716.000M|ao) Aug 27 11:04:52 rigel SMGC: [28194] 3978cd9a[VHD](70.000G//8.000M|n) Aug 27 11:04:52 rigel SMGC: [28194] 1c6e7b14[VHD](70.000G//70.145G|ao) Aug 27 11:04:52 rigel SMGC: [28194] *971a59b8[VHD](10.000G//5.859G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 48edb7f4[VHD](10.000G//10.027G|ao) Aug 27 11:04:52 rigel SMGC: [28194] 5dddf827[VHD](10.000G//8.000M|n) -
I wonder why it's so slow. What's your load average on the dom0?
It could worth to investigate about the SR speed, coalesce is doing a lot of small random read/writes. You have a bottleneck somewhere.
-
Hi Olivier!
[11:09 rigel ~]# uptime 11:09:41 up 28 days, 21:18, 3 users, load average: 1,13, 1,28, 1,29As I mentioned, usually it is "vhd-util scan" running 100% on a single core with no disk read / write at all according to htop. Then comes "vhd-util coalesce" with e.g. 270 M/s read / 120 M/s write
I'm not sure what the sr stats in XO are showing as I sometimes see the coalescing i/o in htop without anything going on in the stats. Currently it looks like this:
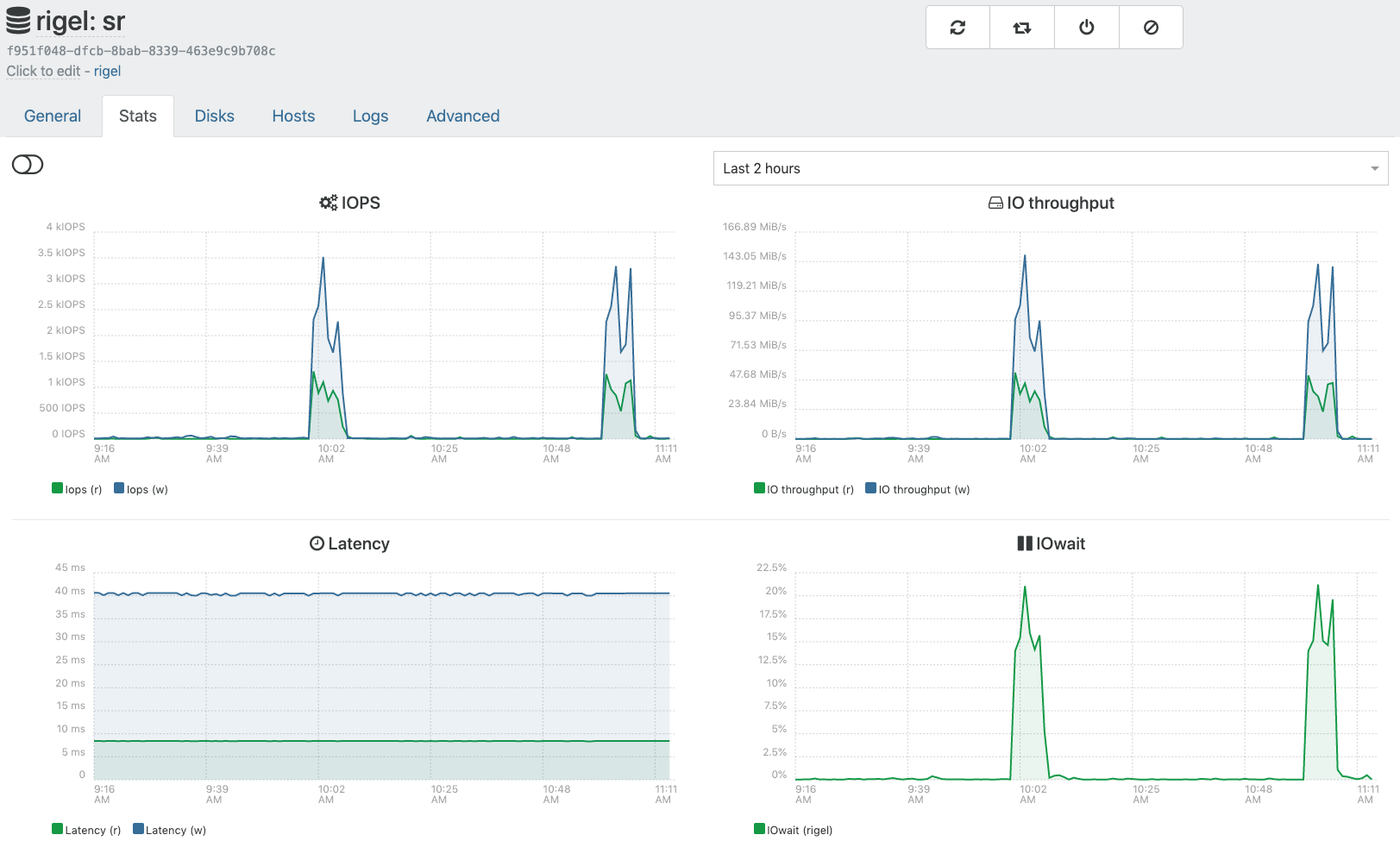
-
How long is your chain in XO SR view/Advanced tab
-
Usually looks like this:
Sometimes the 500 GB vdi depth goes down to 1 for a couple of seconds max.
-
Can you do a
xapi-explore-srso I can see the whole chain in details? -
rigel: sr (28 VDIs) ├── HDD - 03190d28-19b7-4f99-b9b1-d0cace96eeca - 10.03 Gi ├── customer Web Dev: Boot - 03035c65-2e11-47c5-bc0c-c796937fc91d - 40.09 Gi ├─┬ customer server 2017 0 - 43454904-e56b-4375-b2fb-40691ab28e12 - 500.95 Gi │ ├── customer server 2017 0 - dcdef81b-ec1a-481f-9c66-ea8a9f46b0c8 - 0.01 Gi │ └─┬ base copy - 775aa9af-f731-45e0-a649-045ab1983935 - 301.96 Gi │ └─┬ customer server 2017 0 - 31869c7f-b0b6-4deb-9a8e-95aad0baee4c - 0.15 Gi │ └── customer server 2017 0 - 7ef76d55-683d-430f-91e6-39e5cceb9ec1 - 500.98 Gi ├─┬ base copy - 0494da11-f89a-436c-b1d0-e1a1f54bcc90 - 2.21 Gi │ ├── customer yyy - 63b37e30-d9e8-4b54-9fae-780b5e134d79 - 0.01 Gi │ └── customer yyy - 2ca68323-29c8-4a7a-807c-7302a0ba361a - 100.2 Gi ├─┬ base copy - 62feee6c-3aab-471e-89ae-184c5daf2c44 - 36.23 Gi │ ├── customer aaa 2017 0 - 667cf6a9-7e63-4902-9fde-bbe9ef9926ce - 0.01 Gi │ └── customer aaa 2017 0 - 19333817-ce9d-4825-9cd6-eab5bb9f3af7 - 50.11 Gi ├─┬ base copy - 971a59b8-1017-4d2f-8c08-68f0a0ec36e9 - 5.86 Gi │ ├── customer zzz - 5dddf827-1c84-4807-aa1d-3506da0c8927 - 0.01 Gi │ └── customer zzz - 48edb7f4-d8d4-4125-b9a5-829ef139b45c - 10.03 Gi ├─┬ base copy - cb9ff226-bbf6-4865-beb9-7c5028304576 - 34.61 Gi │ ├── System - b70f6e7f-928a-4a65-ae68-0f80e0cd7955 - 0.01 Gi │ └─┬ base copy - 2a99181e-09f0-4991-be44-19a8f9fbe2e6 - 4.24 Gi │ ├── System - e5af497f-9dad-46cd-8233-bacf361ceed9 - 0.01 Gi │ └── System - 6371a662-499f-4a21-a875-1b74ed304454 - 40.09 Gi ├─┬ base copy - d80f9f3d-314d-4842-80e2-847022c5a22c - 28.41 Gi │ ├── Data - bfb778e9-414f-4283-bc72-e552fa24851a - 0.01 Gi │ └─┬ base copy - f56b9b4e-4bbd-4336-88c0-9ce7758cc195 - 0.7 Gi │ ├── Data - 3978cd9a-419d-4016-8f60-3621f8cacdd0 - 0.01 Gi │ └── Data - 1c6e7b14-8cb8-4568-9be7-a22983a2ab1c - 70.14 Gi └─┬ base copy - f74fa838-499a-4a1b-b9eb-87f65525f591 - 14.63 Gi └── XO customer 0 - a23e7cbd-aaa0-4dbf-804b-61089f3c8f43 - 15.04 Gi -
Thanks! So here is the logic: leaf coalesce will (or should
 ) merge a
) merge a base copyand its child ONLY if thisbase copyget only one child.Also, here is a good read: https://support.citrix.com/article/CTX201296
You can check if your SR got leaf coalesce enabled, there's no reason to not have it, but still a check to do.
-
GC is an architectural problem in XenServer | CH. I've been fighting about this with Citrix for a long time and I never see this problem being in fact solved or a documentation of a troubleshooting that really works.
For Enterprise Support | Premium, the procedure to be executed is always the FULL COPY of the VM, which is unfeasible in most cases for a problem that is so recurring.
In CH8 (updated) I have the same problems and I started to have problem in other Pools 7.1 CU2 after installing XS71ECU2009. Until then the process came "stable for a while ", after installing I went back to having problems and unfortunately reinstalling and doing a rollback is not feasible... We opted to upgrade to CH8, but the problem remained...
-
Yeah that's why we are focusing on SMAPIv3 instead of trying to "fix" something that's probably flawed by design on SR with slow speed (in general, it works relatively well on SSDs)
-
@olivierlambert said in Delta backup fails for specific vm with VDI chain error:
SMAPIv3
But @olivierlambert, in other posts, even with a FULL SSD disk (SC5020F) we have failed the coalesce process ... when you talk about SMAPIv3 is this something to be implemented exclusively in XCP or will it be inherited from CH 8.x?
-
@_danielgurgel if you have failed coalesce even on SSD, you should have something that cause the issue. Majority of users don't have this problem, so I suppose the thing is to find what could cause it.
SMAPIv3 is done by Citrix, but we are doing stuff on our side (upstream as possible, harder since Citrix closed some sources). As soon we have something that people could test, we'll push it into testing
")
-
@olivierlambert said in Delta backup fails for specific vm with VDI chain error:
Thanks! So here is the logic: leaf coalesce will (or should
) merge a base copyand its child ONLY if thisbase copyget only one child.Also, here is a good read: https://support.citrix.com/article/CTX201296
You can check if your SR got leaf coalesce enabled, there's no reason to not have it, but still a check to do.
With "only one child" you mean no nested child (aka grandchild)?
As I understand leaf-coalesce can be turned off explicitly and otherwise is on implicitely. It wasn't turned off.
Only thing I could do (I guess) was turn it on explicitely - just to make sure.[15:31 rigel ~]# xe sr-param-get uuid=f951f048-dfcb-8bab-8339-463e9c9b708c param-name=other-config param-key=leaf-coalesce trueNothing has changed so far, so I guess I should go on and see what happens this time if I migrate the vm to the other host?
-
Okay so it wasn't disabled, as it should.
To trigger a coalesce, you need to delete a snapshot. So it's trivial to test: create a snapshot, then remove it. Then you'll see a VDI that must be coalesce in Xen Orchestra.
To answer the question: doesn't matter if the child got child too. As long there is only one direct child, it means coalesce should be triggered.
-
That doesn't seem to have an effect in the behaviour other then a bunch of new messages in the log.
I'll check in a couple of hours. If the behaviour persists I'll migrate the vm and we'll see how it behaves on the other host.
-
Create a snap, display the chain with
xapi-explore-sr. Then remove the snap, and check again. Something should have changed
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login