Alert: Control Domain Memory Usage
-
@borzel I wish comparing kernel-alt and base kernel was easy to catch this... I'm sure that the tapdisk IO code is same in kernel and kernel-alt.
Also the 2 patches mentioned earlier are also present in base kernel of xcp-ng 8.2 as well as kernel-alt 4.19.142. They are also present for xcp-ng 8.1 base kernel, however they are not present in xcp-ng 8.1 kernel-alt.
Can you confirm your kernel-alt version?
-
@borzel Also, I somehow need to be able to reproduce the issue at lab. If you can give more details about how do you do backup, may be I can simulate something.
-
@r1 If it helps at all, I have seen this more often on the pool master than in other pool hosts. We are using XO delta backup on 125 VMs in this pool daily. So, the master is busy doing a lot of snapshot coalesce operations (lots of iSCSI storage IO) compared to other hosts. The other host that has hit 95% control domain memory use is also IO heavy (it has some database server VMs).
-
@r1 our complete setup:
[FreeNAS NFS] <----shared-storage----> [Pool of 2 servers (xen22 + xen23)] ----XAPI---> [XO from sources] -----remote----> [FreeNAS NFS]
All [servers] are real hardware servers, no VMs involved.
Same chain of servers for xen19, execpt there are more pool members (and VMs).
-
[02:27 xen19 ~]# uname -a Linux xen19 4.19.142 #1 SMP Tue Nov 3 11:27:36 CET 2020 x86_64 x86_64 x86_64 GNU/Linux[02:30 xen19 ~]# yum list installed | grep kernel kernel.x86_64 4.19.19-7.0.9.1.xcpng8.2 @xcp-ng-updates kernel-alt.x86_64 4.19.142-1.xcpng8.2 @xcp-ng-basememory graph so far:
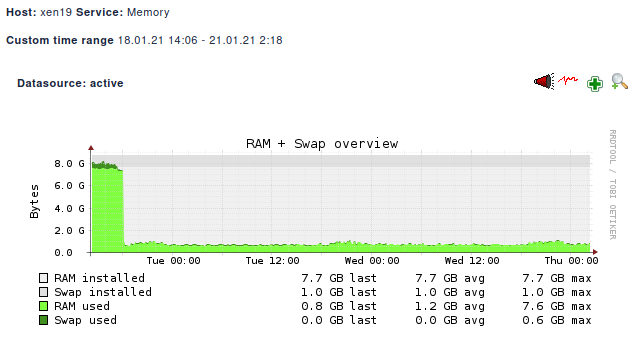
looking very good!!!
-
@borzel Thanks. That rules out the my suspicion on those patches. We are still working on reproducing this issue without success. We would really appreciate if you or someone from community can arrange a test hosts which shows this problem. Reason for test host is because we will have to replace the kernel multiple times to observe change.
Another test users can do is to remove iscsi from equation. Run some workloads on local disks (with backups) and verify control domain memory usage.
-
Good morning.
Long time lurker, first time commenter.
Just wanted to add my 2c worth to this conversation, that may assist.We are running 37 XCP-ng servers, most on Xen 8.0, mixture of Dell R630/640 and some odd Supermicro servers, and we have been experiencing this issue on some of them where DOM0 runs out of memory (free -m like the first post shows very little RAM left).
We see a performance impact (but the VMS still run) with DOM0 - just trying to SSH to DOM0 / using xsconsole is slow, and then eventually DOM0's network fails and whatever we try doesn't restart the networking. When DOM0's network fails all the vms also loose network connectivity. The only resolution is to manually stop each vm via command line and then reboot the xen host.
With one exception, all Xen servers that have experienced this issue generally has an uptime of at least 200 days, but the thing I find interesting is the servers that also have issues has a kubernetes data node on them.
I assume something that kubernetes does is causing the issue. The boxes that do not have kubernetes on them (with 1 exception) never has had this issue.
I have a spare Dell R640 that I'm currently doing some testing on to see if I can create lots of VM and do a heap of CPU/Memory/IO on it to see if I can replicate the issue and if I can try the alternative kernel to see if that makes any difference.
I'll provide feedback on what I find.
Gary
-
Thanks! feedback is vital to help us
")
-
FWIW, no kubernetes in our environment with this issue.
-
Some feedback on some testing that I have done.
I have spun up some vms and done some stress testing on them, with a combination of stress-ng, s-tui and iperf and though slow, I can see a drop over time of DOM0 free memory- 26.1.2021 -- 662 MB used -- 6307 MB free (initial)
- 27.1.2021 -- 726 MB used -- 6270 MB free
- 28.1.2021 11:36 AM -- 840 MB used -- 6123 MB free
- 28.1.2021 12:23 AM -- 866 MB used -- 6191 MB free
- 28.1.2021 3:59 PM -- 877 MB used -- 6056 MB free
- 28.1.2021 4:35 PM -- 883 MB used -- 6048 MB free
- 29.1.2021 7:32 AM -- 897 MB used -- 6004 MB free
This is my setup - XCP-ng 18.0 standard kernel
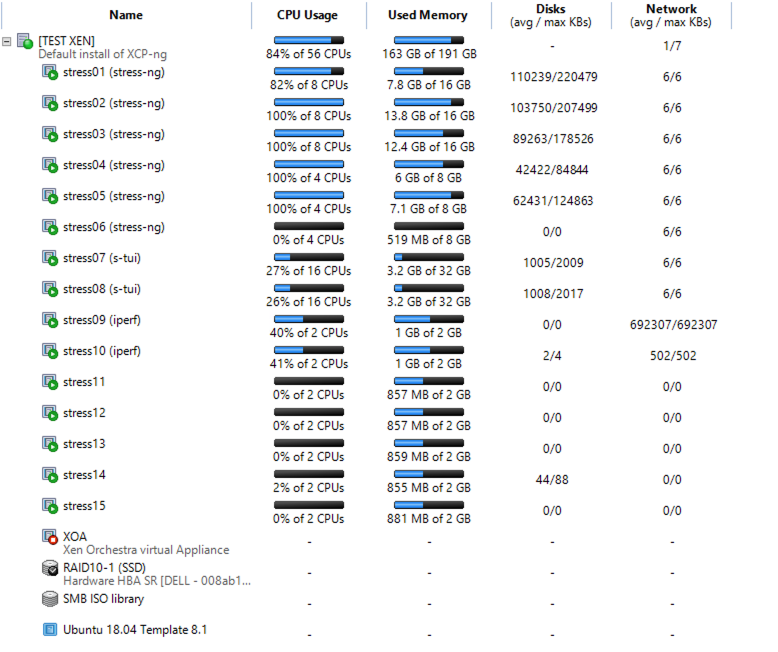
Below are some notes on what I did to do this test.
DOM0 Memory issue.txtI'll try now with different kernels / upgrading to XCP-ng 8.2 (both standard and alternative kernels) and see if I can continue to replicate the issue.
Re: kubernetes - not sure 100% if that is causing it, it just seems to be a common factor but based on the stress testing, lots of cpu/memory/io seems to be causing DOM0 memory usage to increase.
-
@fasterfourier
Can I ask what version of XCP-ng that you are running along with the OS version / Kubernetes version you are running? Still trying to work out what may be causing this. -
@garyabrahams What about alt kernel?
-
@olivierlambert
I installed that this morning and running my tests for a few hours (so only a short period of time)
So far I have seen this on dom0 (via free -m)
I'm running XCP-ng 8.0- 29.1.2021 9:07 AM -- 749 used - 6688 free (initial with all vms running, but no programs)
- 29.1.2021 9:15 AM -- 767 used - 6673 free (vms running, all tests running)
- 29.1.2021 9:46 AM -- 778 used - 6654 free
- 29.1.2021 10:51 AM -- 793 used - 6630 free
Linux cpt-dc-xen02 4.19.68 #1 SMP Fri Sep 27 10:14:57 CEST 2019 x86_64 x86_64 x86_64 GNU/Linux
-
So is it better than before?
-
Still checking. Going to run for another day and see.
Should the memory usage in DOM0 be dropping as part of normal use?
I understand ram usage going up and down just like a normal OS, but a constant increase in memory usage doesn't seem right to me or am I misunderstanding how this work?
Gary
-
"Depends". But you shouldn't have invisible RAM used.
-
Sorry I was unclear, but we are not running Kubernetes in our environment. We are running Citrix Hypervisor 8.2 LTSR.
-
I have another observation to throw in the thread here. In working with Citrix support on our dom0 memory exhaustion issue in CH8.2LTSR, they are focusing on several of our VMs that had dynamic memory control enabled, which is deprecated in CH8.x. They believe this is related to the control domain memory exhaustion.
I have disabled this on all VMs that I can find with the feature enabled and will continue to monitor. I don't have much hope that this is the underlying issue, since we are seeing the memory issue on our pool master, which could only have hosted a VM with DMA enabled for very brief periods of time while other VMs were shuffled around for maintenance.
Does this track with anyone else here?
-
This is... Surprising. I thought
xl topwould allow to rule that out very fast (and it did earlier in this thread when I suspected something related to dom0 memory ballooning). Unless Xen leaks the memory in some way that would not be visible to itself. I don't know if that is even possible and I don't see how that would relate at all with the memory used by dom0, even if there was such a leak related to domU DMC. -
I am also suspicious of this diagnosis, and I think this is likely related to checking off the "misalignments" in our configuration before escalating the case to the next level of troubleshooting support. That said, I figured I'd run it by the group here to see if there's any correlation between users with dynamic memory on their VMs and this issue.
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login