Alert: Control Domain Memory Usage
-
It is a Dell PowerEdge R440 Version 2.6.3 with an LACP Bond and we use an NFS Storage.
-
That doesn't answer all my questions
")
-
NIC:
Intel(R) Ethernet 10G 2P X550-t Adapterdriver: ixgbe version: 5.5.2 firmware-version: 0x80000f32, 19.5.12RAID Controller:
Product Name : PERC H740P Adapter Serial No : 04B00V9 FW Package Build: 50.9.4-3025 Mfg. Data ================ Mfg. Date : 04/18/20 Rework Date : 04/18/20 Revision No : A03 Battery FRU : N/A Image Versions in Flash: ================ Boot Block Version : 7.02.00.00-0021 BIOS Version : 7.09.02.1_0x07090301 FW Version : 5.093.00-2856 NVDATA Version : 5.0900.06-0034I know our hardware is not fully up to date, but for an update we need a timeframe, which can not be arranged that quickly.
Maybe someone knows a temporary fix to reduce the usage of the dom0 memory until the updates can be made. -
Thanks.
If it's a kernel leak, there's nothing to do in user space.
-
Hi everyone.
So, let's not give up, and let's try to find that hidden kernel leak and fix it!
Let me summarize what we currently know. Correctly me if one of the statements is wrong for you:
- It all started with XCP-ng 8.0 and still happens in XCP-ng 8.1
- Memory is not used by user space processes. It's a kernel leak
- We have fixed a rsyslog memory leak through updates, but it was a different issue. By the way, if you have memory that is eaten by a user space process, please open a new thread so that we stay focused on the kernel leak here.
- Our alternate kernel,
kernel-alt, is apparently not affected. - Most (all?) affected hosts have 10Gb interfaces
- Many affected hosts are using iSCSI, though the last report (from @rblvlvl) is on a host with NFS storage
- Some reports suggest that the more network intensive the load is, the quicker the memory usage grows.
- Hosts with more VMs seem to see memory usage grow faster (may be related to the previous points)
- At some point we thought that reverting to a previous kernel (without some security patches) had solved the issue, but after some time memory usage started to grow again
kmemleakdid not detect obvious culprits, though @r1 has a lead regardingiscsi-related functions and we should still keep trying- Disabling the specific device drivers in favour of the built-in drivers in the kernel did not stop the leak
Things that we don't know (tests welcome):
- Is it affecting XCP-ng 8.2 too?
- Is it affecting Citrix Hypervisor? It should since we use the same kernel and drivers (mostly), but this doesn't seem to be a known issue to them.
Now, how to move on:
- Getting our hands on an affected test server and being authorized to reboot it, change the kernel, etc., would help a lot, since we can't reproduce internally (@dave maybe? At some point you said you might provide one)
- Reach out to kernel developers for advice?
- If someone manages to reproduce on Citrix Hypervisor, raise the issue on their bugtracker too.
- Check the kernel 4.19 history for memory leak fixes, especially those related to networking.
Any other idea to move on is welcome, of course.
-
Before I realized that not every affected host was using the
ixgbedriver, contrarily to what I initially thought, I built an alternate driver from the latest sources from Intel.So, even if there's little hope that it will fix anything, here's how to install it (on XCP-ng 8.1 or 8.2):
yum install intel-ixgbe-alt --enablerepo=xcp-ng-testing reboot -
Do we asked to provide also
lsmod? That might be interesting to overlap different results and see common ones. -
@olivierlambert Yes, various users have shared their
lsmod. -
The latest report was on a NFS storage, however
lsmoddisplays various iSCSI modules loaded. So it doesn't mean it's not an iSCSI module issue:scsi_mod 253952 13 fcoe,scsi_dh_emc,sd_mod,dm_multipath,scsi_dh_alua,scsi_transport_fc,libfc,bnx2fc,megaraid_sas,sg,scsi_dh_rdac,scsi_dh_hp_swedit: what about
bnx2fc? Is it common to other reports?edit 2: nope, might be
megaraid_sasinstead. -
Is there a way to provide alternate/up to date modules for the most suspicious ones? At some point, we'll find the culprit!
-
It depends how self-contained the modules are. For device drivers, it's usually feasible. For more core parts of the kernel, I think we should rather try to identify patches that look like they could fix the issue and rebuild the kernel with them.
We could also opt for a dichotomy approach between the main kernel and the alternate kernel, but since it takes days before one can be sure that there's no leak, it's not really doable, unless we find a way to reproduce the issue way faster (which is another thing in which users may help: try to provoke the memleak on purpose. High network load seems to be a lead.).
-
@olivierlambert said in Alert: Control Domain Memory Usage:
The latest report was on a NFS storage, however
lsmoddisplays various iSCSI modules loaded. So it doesn't mean it's not an iSCSI module issue:Isn't it SCSI rather than iSCSI here? However, maybe the leak is in SCSI layers indeed...
-
I am seeing similar behavior with Citrix Hypervisor 8.2LTSR after upgrading from 7.1CU2, which was not affected. We have a pool with 5 Poweredge R730 hosts and 2 R720 hosts. All have Intel 10G and 1G NICs (ixgbe and igb drivers) and we use iSCSI storage. I have had two hosts use up all their control domain memory, requiring an evacuate/reboot of the host. One host was the pool master, which runs only one VM (xen orchestra appliance) but is generally busy with various iSCSI tasks due to snapshot coalesce after daily backups. The other host has ~20 VMs that are pretty busy with network activity. No userspace processes that seem to be using an abnormal amount of memory.
-
Thanks, this is good to have confirmation of what we thought about CH 8.2 but couldn't prove!
-
@stormi I've just opened a Citrix case on the issue, but I wouldn't expect much help there, and definitely wouldn't expect anything quickly.
-
@fasterfourier Well, we've also tried to make the issue known to Citrix before so maybe your confirmation that it does not only happen in XCP-ng will be enough to trigger some movement about it. A memory leak that makes the host unusable is not a small issue.
-
@stormi The ID for the case I just opened is 80240347. If you have a bugtracker issue open, you may want to mention that ticket. I just now opened the ticket, though, so it will be a while before it makes its way out of tier 1, etc.
EDIT: Had the wrong case number at first. Updated case number.
-
We also have an issue with growing control domain memory:
- XCP-ng 8.2
- NFS shared storage
- the poolmaster (xen19 is one of them) are more affected than pool members
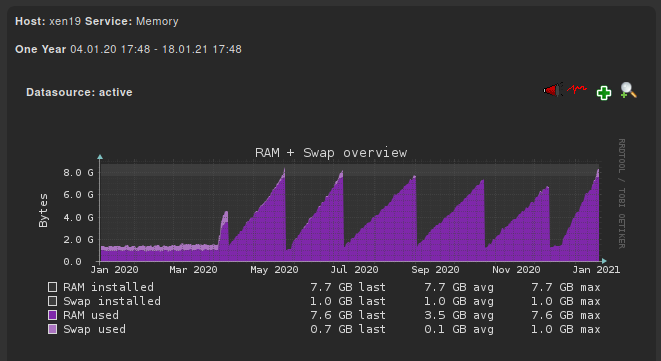
Today I install the alternate kernel on one of our poolmaster to see if that resolves our issue.
-
I noticed in my monitoring graphs, that since we have this issue, the SWAP is not used like before the issue:
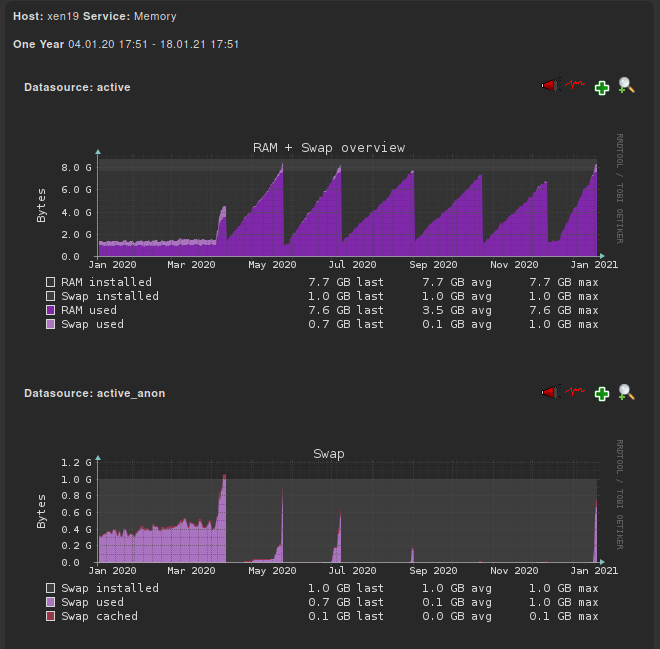
-
looked in my yum.log on this server (xen19):
our problems startet exactly since "Apr 10 18:10:29 Installed: kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64"
yum.log.4.gz:Oct 03 17:35:54 Installed: kernel-4.4.52-4.0.7.1.x86_64 yum.log.4.gz:Nov 20 18:29:29 Updated: kernel-4.4.52-4.0.12.x86_64 yum.log.2.gz:Oct 10 20:19:31 Updated: kernel-4.4.52-4.0.13.x86_64 yum.log.1:Apr 10 18:10:29 Installed: kernel-4.19.19-6.0.10.1.xcpng8.1.x86_64 yum.log.1:Jul 07 17:46:34 Updated: kernel-4.19.19-6.0.11.1.xcpng8.1.x86_64 yum.log.1:Dec 10 17:59:07 Updated: kernel-4.19.19-6.0.12.1.xcpng8.1.x86_64 yum.log.1:Dec 19 13:53:39 Updated: kernel-4.19.19-6.0.13.1.xcpng8.1.x86_64 yum.log.1:Dec 19 13:55:20 Updated: kernel-4.19.19-7.0.9.1.xcpng8.2.x86_64 yum.log:Jan 18 17:35:07 Installed: kernel-alt-4.19.142-1.xcpng8.2.x86_64