unhealthy VDI chain
-
Have you checked your log files to see why the VDIs aren't coalescing? In XO, you can check under
Dashboard > Healthto observe the VDIs pending coalesce . -
You might have simply a SR coalescing not fast enough for your backup

-
@Danp was a something here before, but now it empty.
i'll wait few more days to be sure is it still broken or not. -
@olivierlambert looks like XO got a bad cache with that storage.
on same physical storage i have 2 shares connected to pool. All vm is usualy at 1st.
So i moved broken VDI to 2nd, made few backups, everything works fine. Then moved VDI back to 1st, got this error again.
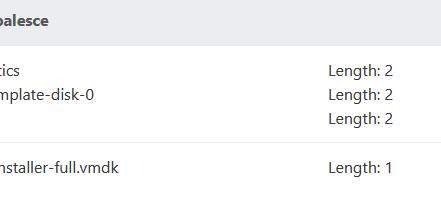
Any options how to fix that without migrating all VMs and removing this storage?
-
problem still exist even for new VMs.
-
You need to understand why it doesn't coalesce
")
/var/log/SMlogis your friend. -
@olivierlambert nothing about failed VMs at SMlog for this period.
backup task started at 1:00. since 1:03 to 1:06 few backups was failed. log looks likeJun 14 01:00:35 name SM: [17853] pread SUCCESS Jun 14 01:00:35 name SM: [17853] lock: released /var/lock/sm/.nil/lvm Jun 14 01:00:35 name SM: [17853] lock: acquired /var/lock/sm/.nil/lvm Jun 14 01:00:36 name SM: [17853] lock: released /var/lock/sm/.nil/lvm Jun 14 01:00:36 name SM: [17853] Calling tap unpause with minor 8 Jun 14 01:00:36 name SM: [17853] ['/usr/sbin/tap-ctl', 'unpause', '-p', '28995', '-m', '8', '-a', 'vhd:/dev/VG_XenStorage-f1a514f3-2ef9-5705-7a7e-c8c23483122c/V HD-236b3cc3-80f7-40ff-9862-f8d4c2f69225'] Jun 14 01:00:36 name SM: [17853] = 0 Jun 14 01:00:36 name SM: [17853] lock: released /var/lock/sm/236b3cc3-80f7-40ff-9862-f8d4c2f69225/vdi Jun 14 01:06:02 name SM: [19600] on-slave.multi: {'vgName': 'VG_XenStorage-f1a514f3-2ef9-5705-7a7e-c8c23483122c', 'lvName1': 'VHD-1fa9eb66-49fe-4e93-b64d-fbb2c3 bb8745', 'action1': 'deactivateNoRefcount', 'action2': 'cleanupLockAndRefcount', 'uuid2': '1fa9eb66-49fe-4e93-b64d-fbb2c3bb8745', 'ns2': 'lvm-f1a514f3-2ef9-5705-7a7e-c8c2 3483122c'} Jun 14 01:06:02 name SM: [19600] LVMCache created for VG_XenStorage-f1a514f3-2ef9-5705-7a7e-c8c23483122c Jun 14 01:06:02 name SM: [19600] on-slave.action 1: deactivateNoRefcount Jun 14 01:06:02 name SM: [19600] LVMCache: will initialize now Jun 14 01:06:02 name SM: [19600] LVMCache: refreshing Jun 14 01:06:02 name SM: [19600] lock: opening lock file /var/lock/sm/.nil/lvm Jun 14 01:06:02 name SM: [19600] lock: acquired /var/lock/sm/.nil/lvm Jun 14 01:06:02 name SM: [19600] ['/sbin/lvs', '--noheadings', '--units', 'b', '-o', '+lv_tags', '/dev/VG_XenStorage-f1a514f3-2ef9-5705-7a7e-c8c23483122c'] Jun 14 01:06:03 name SM: [19600] pread SUCCESSno any info for 6 min.
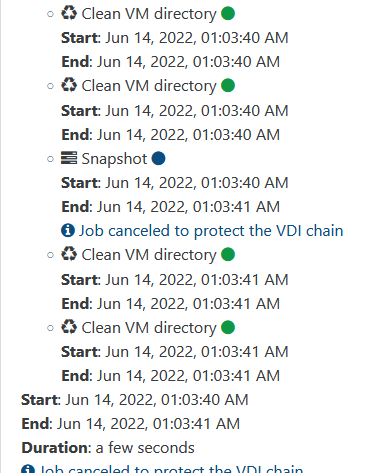
-
This XO message is not a failure. It's a protection.
Your problem isn't in XO but in your storage that either doesn't coalesce (at all) or coalesce slower than you create new snapshots (ie when a new backup starts).
So you have to check on storage side if you have coalesce issues.
-
@olivierlambert but backup works fine on another share at same storage. I think it easier to recreate this one.
-
In your XO, SR detailed view, Advanced, you should see the disks to coalesce.
If you backup a VM having a disk not coalesced yet, XO will prevent the creation of a new snapshot.
You can disable all jobs and see if you end with zero VDI to coalesce. If it works, then it means some disks are backup faster than your SR can coalesce.
-
@olivierlambert thanks, i will try.
-
solved problem.
Storage was in weird state, can't dismount it from pool with bunch on unknown errors. Need a pool reboot to detach it. After reattach it works normally. -
Good news then