@Forza Sorry, you were correct, I just mixed in another new issue. NFS is currently used only for backups. All my SRs are in local storage. It just happened that I now have backups failing not just because of the NFS issue but because of the VDI issue but I think it's a side-effect of the NFS problem causing the backup to get interrupted so now the VDI is stuck attached to dom0. I should have made that more clear or never mentioned the VDI issue at all.
C
Offline
Best posts made by CodeMercenary
-
RE: All NFS remotes started to timeout during backup but worked fine a few days agoposted in Backup
-
RE: All NFS remotes started to timeout during backup but worked fine a few days agoposted in Backup
@Forza Seems you are correct about
showmount. On UNRAID running v4showmountsays there are no clients connected. I previously assumed that meant XO only connected during the backup. When I look at/proc/fs/nfsd/clientsI see the connections.On Synology, running v3,
showmountdoes show the XO IP connected. Synology is supposed to support v4 and I have the share set to allow v4 but XO had trouble connecting that way. Synology is pretty limited in what options it lets me set for NFS shares.
Synology doesn't have
rcpdebugavailable. I'll see if I can figure out how to get more logging info about NFS. -
RE: One VM backup was stuck, now backups for that VM are failing with "parent VHD is missing"posted in Backup
@olivierlambert Well, last night the backup completed just fine despite me taking no action.
I updated the XO to the latest commit when I got in this morning so hopefully the issue I had back in June don't come back.
-
RE: Possible to use "xo-cli vm.set blockedOperarations=<object>"?posted in Management
@julien-f Thank you, that's super helpful and even easier than I thought it would be.
-
RE: Import from ESXi 6 double importing vmdk file?posted in Migrate to XCP-ng
@florent Yeah, it's a lot of data, thankfully my other VMs are not nearly as large. I'm still not sure why it failed when none of the virtual drives are 2TB. The largest ones are configured with a 1.82TB max so even the capacity of the drive is less than the max.
I'm moving ahead with a file level sync attempt to see if that works.
To be clear, this post was as much or more about helping you figure out what's wrong so other people don't have the same issue, than it is about making this import work for my VM. With the flood you are getting from VMware refugees, I figure I'm not the only person with large drives to import. In other words, if there's something I can do to help you figure out why it fails then I'm willing to help.
-
RE: NVIDIA Tesla M40 for AI work in Ubuntu VM - is it a good idea?posted in Hardware
@gskger Yeah, looks like it would be too tight. Ouch, those T4s are an order of magnitude more expensive. I'm definitely not interested in going that route.

-
RE: Seeking advice on debugging unexplained change in server fan speedposted in Off topic
@DustinB Nothing useful yet. I rebooted the servers and explored a bit in the BIOS to see if there were any settings, or to at least tweak some things to see if it would reset whatever went wrong in the reboot in mid December. While doing that I found that one of the two impacted servers was a version behind for the BIOS as well as for the iDRAC so I updated both of them. Unfortunately, that made no change to the fan speeds.
I've been out sick all of this week, so far, but I'll be looking into this more when I get back to the office. I've read about ways to manually control the fans but I'd rather not have to depend on a script running somewhere that makes those kinds of decisions, I'd much rather have iDRAC, or whatever normally controls it, handle it like it used to.
-
RE: Help: Clean shutdown of Host, now no network or VMs are detectedposted in Compute
@olivierlambert It was DR. I was testing DR a while ago and after running it once I disabled the backup job so these backups have just been sitting on the server. I don't think I've rebooted that server since running that backup.
Latest posts made by CodeMercenary
-
RE: Common Virtualization Tasks in XCP-ngposted in Compute
A powershell SDK? Oh, you just made me a rather happy guy.
-
Long delays at 46% when creating or starting a new VMposted in Management
I've been trying to create a new Ubuntu 24.04 VM today and it's behaving very weird. All my hosts have local storage. I've tried creating VMs on two of my hosts, one with a 500GB drive (thin) on SSD and one with a 50GB drive (thin) on HDD. I attached the ubuntu boot disk to the VM.
When I tell XO (from source) to create the VM, the creation process hangs at 46% for 15 or 20 minutes. It normally completes within a matter of seconds.
They were both set to autostart but neither started. Once the creation task finally finished, I tried to start them. Again, they hung at 46% for 15 or 20 minutes and then didn't start.
I realized my XO was last updated on Monday and there were more updates so I updated it and it did not change the behavior.
The only log entry that seems like it might be related is:
vm.start { "id": "4921a56a-c099-92d9-4ee4-939d8bc1adcf", "bypassMacAddressesCheck": false, "force": false } { "name": "HeadersTimeoutError", "code": "UND_ERR_HEADERS_TIMEOUT", "message": "Headers Timeout Error", "call": { "duration": 300806, "method": "VM.start", "params": [ "* session id *", "OpaqueRef:b66b9e3e-ac91-47d9-81ce-383de2ed326f", false, false ] }, "stack": "HeadersTimeoutError: Headers Timeout Error at FastTimer.onParserTimeout [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502270017/node_modules/undici/lib/dispatcher/client-h1.js:642:28) at Timeout.onTick [as _onTimeout] (/opt/xo/xo-builds/xen-orchestra-202502270017/node_modules/undici/lib/util/timers.js:162:13) at listOnTimeout (node:internal/timers:581:17) at processTimers (node:internal/timers:519:7)" }There was also this but I didn't cancel anything around when this happened:
vm.start { "id": "4921a56a-c099-92d9-4ee4-939d8bc1adcf", "bypassMacAddressesCheck": false, "force": false, "host": "f23f627d-007e-499e-97cf-678574566429" } { "message": "task canceled" }How do I go about investigating this?
Update: I figured it out. A few weeks ago I changed the IP addresses in XO for backups and SMB ISO storage so they would use the 10Gbe network adapter in that server. I've had no trouble with backups since then, however, it appears the SMB ISO storage is no longer accessible from XO/XCP. I added a new NFS ISO storage to the same location and it works. Now the VMs will boot.
I think I'll leave this here in case someone else runs into the same issue. If you have an ISO image attached to the VM and the server can't get to it, it will get stuck during boot and will kick out that timeout error without indicating that it timed out on connecting to the ISO storage.
-
RE: What's the recommended way to reboot after applying XCP-ng patches?posted in Management
@kagbasi-ngc Oh, that's quite interesting. I have less than a dozen VMs that I consider production so it's not a big deal to start them manually. I've thought about putting the host into maintenance mode while doing this but my main XO instance is on one of those hosts. I do have an XO instance running in a VM on my UNRAID host just so I have a way to recover if one of the XCP hosted instances don't run.
I'll have to try the smart reboot, that's a great tip, thank you.
I've thought about offering to help our church with computer stuff but there's already a guy that handles it and I don't know if I want to go down that rabbit hole. He seems to do a good job but I don't think he's as technical as I am and I doubt he has server experience.
-
RE: What's the recommended way to reboot after applying XCP-ng patches?posted in Management
@Danp So it sounds like there isn't much of a way to do this cleaner than I currently do. Patching doesn't happen very often so it's not a big deal to me if it's annoying, I just wanted to make sure I wasn't missing something that would make it easier. Would be nice not to have to manually disable autostart but I could always automate turning it off and back on using the cli and a tag if that's what I need to do.
Yesterday I did use
Install Pool Patcheswhich was quite nice and worked beautifully.I guess the question is, if I tell a host to reboot and it has running VMs and there is no shared storage, what does it do with the VMs? Will it try to manually migrate them by copying hundreds of GB to another host? Will it shut them down cleanly if they have the management tools installed? Will it poke the VM's virtual power button to shut itself down if the VM doesn't have management tools installed?
In other words, can I just
Install Pool Patchesand then reboot the hosts starting with the master if I don't care if the VMs are shut down? Our office is small and we don't have any VMs that must run 24/7 with absolutely no downtime so I don't mind having the VM down during a reboot if it's outside office hours. -
What's the recommended way to reboot after applying XCP-ng patches?posted in Management
Seems like every time there are patches I mess something up in some way.
The first time I installed patches, I shut down all the VMs just to get ready for the reboot. Then when I installed the patches, it restarted the toolstack which restarted all my VMs.
The second time there were patches I can't exactly remember what went wrong but I know it didn't go smoothly. I think in that case I rebooted all three servers at the same time and the ones that aren't the pool master weren't able to find the master, maybe because they booted slightly faster, so they had to be rebooted again.
This evening I wasn't going to make those mistakes so I installed all the patches to the whole pool then I shut down the VMs on the pool master and rebooted it. While it was rebooting I shut down almost all the VMs on the other two servers in the pool. I'm sure a bunch of you see what's coming... When the master rebooted, it started all those auto-start VMs on the other two servers too. I shut all those VMs down and rebooted and rebooted the second of the three servers. When it came back up, all the auto-start VMs on the third, still un-rebooted, server. Now I have to shut all those VMs down again so I can reboot that server.
Note, I don't have any shared storage. I was shutting VMs down because I didn't want to risk having the servers spend the next six hours migrating VMs to another host only to spend six hours migrating them back after the reboot. Maybe they wouldn't do that but I wasn't sure so it seemed safer to shut down all VMs on the host before the reboot so it would be clear that nothing should migrate.
So, what's the right way to do this?
Do I leave the VMs alone, install the patches and then reboot the servers starting with the master but just let the host reboot handle shutting down the VMs? It seems I need to stop trying to help it do its job.
-
RE: Seeking advice on debugging unexplained change in server fan speedposted in Off topic
@DustinB I forgot to mention that I did look for firmware for the fans and I see nothing on Dell's downloads for the R630 that indicate that there is any fan related firmware at all. That's why I started trying to tweak the settings in the BIOS and iDRAC related to power and cooling, to see if I could get it to go back to the way it was.
-
RE: Seeking advice on debugging unexplained change in server fan speedposted in Off topic
@DustinB Nothing useful yet. I rebooted the servers and explored a bit in the BIOS to see if there were any settings, or to at least tweak some things to see if it would reset whatever went wrong in the reboot in mid December. While doing that I found that one of the two impacted servers was a version behind for the BIOS as well as for the iDRAC so I updated both of them. Unfortunately, that made no change to the fan speeds.
I've been out sick all of this week, so far, but I'll be looking into this more when I get back to the office. I've read about ways to manually control the fans but I'd rather not have to depend on a script running somewhere that makes those kinds of decisions, I'd much rather have iDRAC, or whatever normally controls it, handle it like it used to.
-
RE: Seeking advice on debugging unexplained change in server fan speedposted in Off topic
@DustinB I wish I had asked the question here earlier. I asked it a little while ago on ServerFault.com, figuring that was the best place for this question since it has nothing to do with XCP-ng. Nobody has answered and one person even downvoted it without saying why.
If you use ServerFault and you answer over there, I'll mark it as an answer if this works, so you can get some internet points.
https://serverfault.com/questions/1169753/what-might-cause-server-fans-to-double-in-rpm-after-a-simple-reboot -
RE: Seeking advice on debugging unexplained change in server fan speedposted in Off topic
@DustinB Interesting, I'll see if there's fan firmware I can update. It's so strange that they were fine and a reboot make them do this. One of the systems is running the fans at full speed which makes them have a high-pitched whine, it's rather annoying, also not great for the fans I imagine.
-
Seeking advice on debugging unexplained change in server fan speedposted in Off topic
Back in mid-December I came into the office on a weekend to test my power-outage handling via NUT. I unplugged the UPSs, monitored all the VMs getting shut down and then the servers shut down. I never allowed the UPSs to totally lose power, just kept them unplugged long enough to trigger the server shutdown.
I have two PowerEdge R630 and one R730. When I rebooted the servers, the R630s seemed louder than normal. That's typical on startup but they continued to be louder once booted. The R730 did not seem any different.
I have LibreNMS set up to monitor the servers and the graphs of fan speed confirmed my feelings of them being louder. The fan speeds have doubled on one server and increased by four times on the other but the CPU workload has not changed at all.
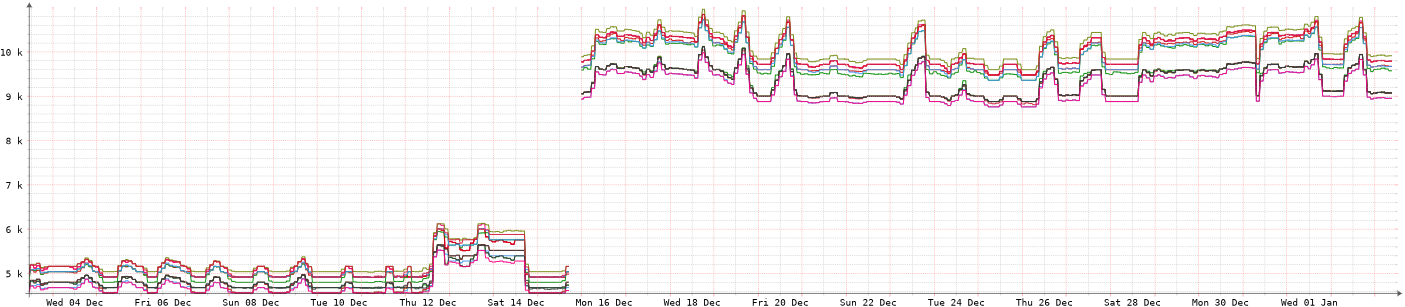
The other server is even more dramatic and it is the more lightly loaded of the servers.
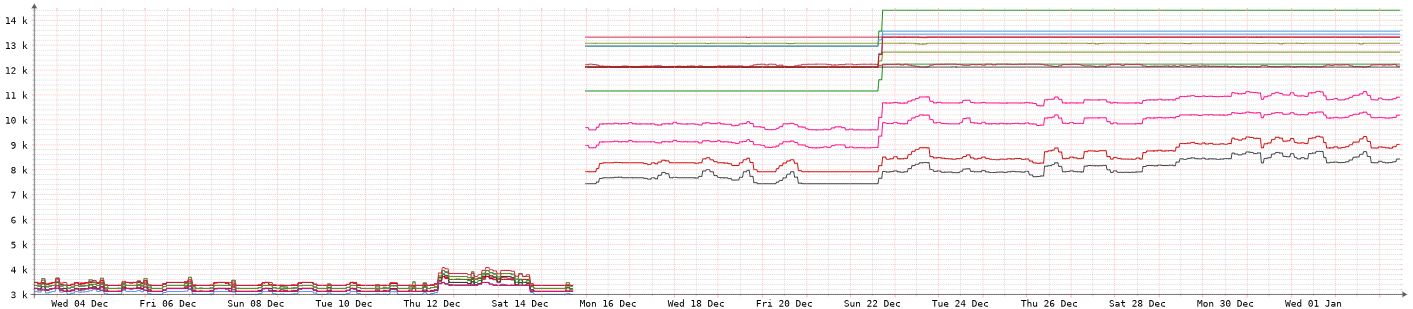
As you can see, the fan speeds have remained high ever since the reboot.Over this last weekend we had a power outage so the servers shut down. After rebooting the fans are still running fast so it wasn't just a simple reboot needed to fix this.
LibreNMS isn't capturing CPU usage for some reason but here's the CPU usage from XO. It has not changed significantly in months.
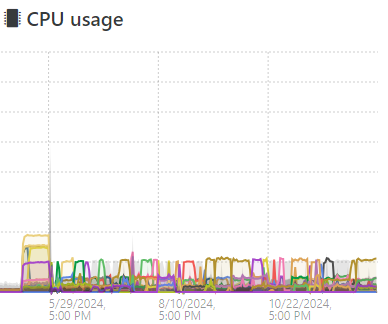
The system board and CPU temps dropped at the same time of course, with all that extra airflow. Note, those temps are in F, not C.
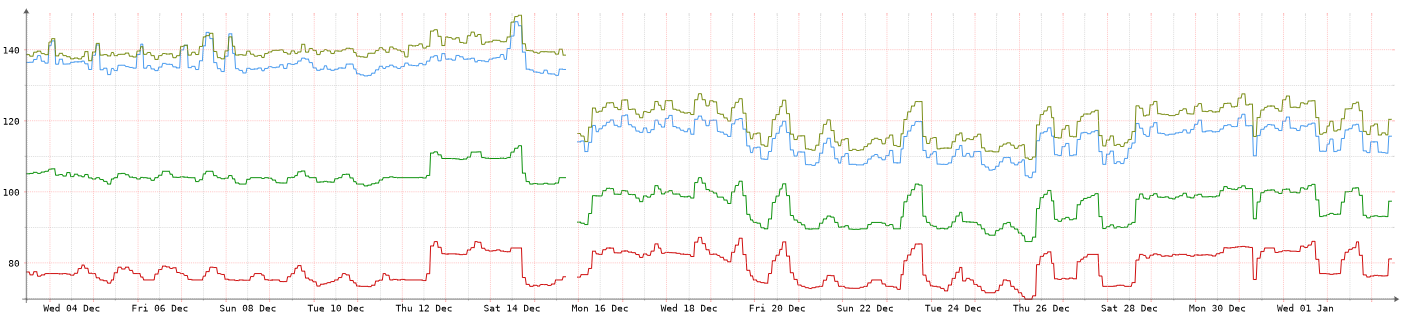
Any ideas of things to look for in the BIOS, iDRAC and/or LibreNMS that might indicate why this would have changed? There were no updates of the BIOS or anything associated with that reboot in December and another reboot has not changed it back. Are there possibly BIOS settings that would tell the server to run fans full speed and maybe those settings randomly changed?
Our servers are near our offices so this significant increase in sound output annoys people. I don't mind when servers are loud because they need to be loud but doubling the noise without any reason is quite annoying.