Hello,
I'm a new developer on XCP-ng, I'll work on the Xen side to improve performance.
I'm a newly graduated of University of Versailles Saint-Quentin with a specialty in parallel computing and HPC, I have a big interest in operating systems.
Hello,
I'm a new developer on XCP-ng, I'll work on the Xen side to improve performance.
I'm a newly graduated of University of Versailles Saint-Quentin with a specialty in parallel computing and HPC, I have a big interest in operating systems.
Hello,
As some of you may know, there is currently a problem with disks with blocksize of 4KiB not being compatible to be a SR disk.
It is an error with the vhd-util utilities that is not easily fixed.
As such, we quickly developed a SMAPI driver using losetup ability to emulate another sector size to be able to workaround the problem for the moment.
The real solution will involve SMAPIv3, which the first driver is available to test: https://xcp-ng.org/blog/2024/04/19/first-smapiv3-driver-is-available-in-preview/
To go back to the LargeBlock driver, it is available in 8.3 in sm 3.0.12-12.2.
To set it up, it is as simple as creating a EXT SR with xe CLI but with type=largeblock.
xe sr-create host-uuid=<host UUID> type=largeblock name-label="LargeBlock SR" device-config:device=/dev/nvme0n1
It does not support using multiple devices because of quirks with LVM and the EXT SR driver.
It automatically creates a loop device with a sector size of 512b on top of the 4KiB device and then creates a EXT SR on top of this emulated device.
This driver is a workaround, we have automated tests but they can't catch all things.
If you have any feedbacks or problems, don't hesitate to share here ")
@ph7 It's only enabled for the two yum command with the --enablerepo explicitly used.
It's disabled in the config otherwise.
No need to do anything
For people testing the QCOW2 preview, please be informed that you need to update with the QCOW2 repo enabled, if you install the new non QCOW2 version, you risk QCOW2 VDI being dropped from XAPI database until you have installed it and re-scanned the SR.
Dropping from XAPI means losing name-label, description and worse, the links to a VM for these VDI.
There should be a blktap, sm and sm-fairlock update of the same version as above in the QCOW2 repo.
If you have correctly added the QCOW2 repo linked here: https://xcp-ng.org/forum/post/90287
You can update like this:
yum clean metadata --enablerepo=xcp-ng-testing,xcp-ng-qcow2
yum update --enablerepo=xcp-ng-testing,xcp-ng-qcow2
reboot
blktap: 3.55.4-1.1.0.qcow2.1.xcpng8.3sm: 3.2.12-3.1.0.qcow2.1.xcpng8.3@jhansen
Hello,
I created a thread about the NBD issue where VBD are left connected to Dom0.
I added what I already know about the situation on my side.
Anyone observing the error can help us by sharing what they observed in the thread.
https://xcp-ng.org/forum/topic/9864/vdi-staying-connected-to-dom0-when-using-nbd-backups
Thanks
Hello again,
It is now available in 8.2.1 with the testing packages, you can install them by enabling the testing repository and updating.
Available in sm 2.30.8-10.2.
yum update --enablerepo=xcp-ng-testing sm xapi-core xapi-xe xapi-doc
You then need to restart the toolstack.
Afterwards, you can create SR with the command in the above post.
@olivierlambert @S-Pam Indeed, it's normal, Dom0 doesn't see the NUMA information and the hypervisor handle the compute and memory allocation. You can see the wiki about manipulating VM allocation with the NUMA architecture if you want. But in normal use-cases it's not worth the effort.
Hello
So, you can of course makes some config by hand to alleviate some of the cost of the architecture on virtualization.
But like you can imagine, the scheduler will move the vCPU around and sometimes break the L3 locality if it move it to a remote core.
I asked to someone more informed than me about that and he said that running a vCPU is always better than trying to make it run locally so it's only useful under specific condition (having enough resources).
You can use the cpupool functionality to isolate VM on a specific NUMA node.
But it's only interesting if you really want more performance since it's a manual process, and can be cumbersome.
You can also pin vCPU on a specific physical core to keep L3 locality, but it would only work if you have little amount of VM running on that particular core. So yes, it might be a little gain (or even a loss).
There is multiple ways to make the core pinned, most with xl but if you want it to stick between VM reboot you need to use xe. Especially since if you want to pin a VM to a node and need it's memory being allocated on that node, since it can only be done at boot time. Pinning vCPU after boot using xl can create problem if you pin it on a node and the VM memory is allocated on a another node.
You can see the VM NUMA memory information with the command xl debug-key u; xl dmesg.
With xl:
Pin a CPU:
xl vcpu-pin <Domain> <vcpu id> <cpu id>
e.g. : xl vcpu-pin 1 all 2-5 to pin all the vCPU of the VM 1 to core 2 to 5.
With CPUPool:
xl cpupool-numa-split # Will create a cpupool by NUMA node
xl cpupool-migrate <VM> <Pool>
(CPUPool only works for guest, not dom0)
And with xe:
xe vm-param-set uuid=<UUID> VCPUs-params:mask=<mask> #To add a pinning
xe vm-param-remove uuid=<UUID> param-name=VCPUs-params param-key=mask #To remove pinning
The mask above is CPU id separated with comma e.g. 0,1,2,3
Hope I could be useful, I will add that to the XCP-ng documentation soon
@lotusdew Your second PCI address is wrong. You have a dot instead of a colon: 0000:03.00.1 -> 0000:03:00.1.
For people testing the QCOW2 preview, please be informed that you need to update with the QCOW2 repo enabled, if you install the new non QCOW2 version, you risk QCOW2 VDI being dropped from XAPI database until you have installed it and re-scanned the SR.
Dropping from XAPI means losing name-label, description and worse, the links to a VM for these VDI.
There should be a blktap, sm and sm-fairlock update of the same version as above in the QCOW2 repo.
If you have correctly added the QCOW2 repo linked here: https://xcp-ng.org/forum/post/90287
You can update like this:
yum clean metadata --enablerepo=xcp-ng-testing,xcp-ng-qcow2
yum update --enablerepo=xcp-ng-testing,xcp-ng-qcow2
reboot
blktap: 3.55.4-1.1.0.qcow2.1.xcpng8.3sm: 3.2.12-3.1.0.qcow2.1.xcpng8.3Hi, this XAPI plugin multi is called on another host but is failing with IOError.
It's doing a few things on a host related to LVM handling.
It's failing on one of them, you should look into the one having the error to have the full error in SMlog of the host.
The plugin itself is located in /etc/xapi.d/plugins/on-slave, it's the function named multi.
@ph7 It's only enabled for the two yum command with the --enablerepo explicitly used.
It's disabled in the config otherwise.
No need to do anything
@elsif2 I'm not too sure but I think it's the on-boot parameter on the VDI, it can have two values: persist and reset.
Maybe setting to reset would be enough.
I have not tried to use it though.
You can set it like this:
xe vdi-param-set uuid=<VDI UUID> on-boot=reset
The VM of which the VDI is connected to needs to be offline.
@buldamoosh Oh yeah, you can't disable CBT on a snapshot. It is inherited from the VDI it is the snapshot of.
You can vdi-destroy the snapshot instead of forgetting them
But yeah, it is "normal" that the snapshot are not removed by the migration.
CBT will be enabled by XO if you have the NBD+CBT enabled on your backup job.
@buldamoosh You just need to disable CBT on the VDI you want to move.
Do you not use XO to migrate VDI? it should be doing itself from what I understood.
Otherwise, you can just disable CBT on the VDI with : xe vdi-disable-cbt uuid=<VDI UUID> before migrating the VDI.
@Greg_E No, it's because CBT is special, you don't need to remove backup because they will be collected by the GC either way.
CBT need to be disabled before moving a VDI (and if needed re-enabled on the new VDI following migration).
CBT Metadata VDI won't be automatically removed though.
I think XO automatically disable CBT before moving a VDI, but it does not automatically remove the CBT Metadata VDI when not needed anymore.
@McHenry Base copies are not copy per say but a base of a VDI chain.
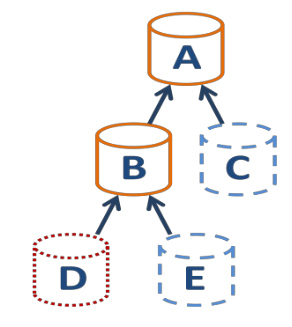
Here you can see that A and B are base copies for the snapshots C and E while D is the active VDI.
You can find more info on this page: https://docs.xcp-ng.org/storage/#-coalesce
@jhansen
Hello,
I created a thread about the NBD issue where VBD are left connected to Dom0.
I added what I already know about the situation on my side.
Anyone observing the error can help us by sharing what they observed in the thread.
https://xcp-ng.org/forum/topic/9864/vdi-staying-connected-to-dom0-when-using-nbd-backups
Thanks