@marvine I dont know if that is true or not.. I am using 8.3 RC1 with GPU pass-through to NVidia Tesla cards with no problems (aside from the NVidia drivers being a pain in the backside to install under Linux).
Posts
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
@pierre-c I dont use iSCSI in my lab anymore, but yesterday when I did a "yum update" of 8.3 Beta, I got a script error when yum was running through all the updates. The script that failed was part of the sm update.
To be honest, I didnt bother doing anything with the error as everything seemed to work OK for me after, so I just ignored it. But.. Maybe I should have said something.. Sorry guys..
-
RE: CBT: the thread to centralize your feedback
For those that may be stuck, like I was, I finally have un-done the coaless nightmare the previous CBT did.
For note: I am using XCP-ng 8.3 Beta fully patched.
- What I had to do was shutdown every VM and delete every snapshot
- Find every VDI that had CBT enabled and disable it. I did this in a simple bash command (not the best, I know)
for i in `xe vdi-list cbt-enabled=true | grep "^uuid ( RO)" | cut -d " " -f 20` do echo $i xe vdi-disable-cbt uuid=$i done- Reboot the server
- Create a snapshot on any VM and immidately delete it. (If you just do a rescan, it says that the GC is running when it is not but for whatever reason, deleting a shapshot seems to kick in the GC regardless)
- Keep an eye on the SMLog and look for exceptions... I tend to do something like: (It will sleep for 5 minutes - so dont get anxious)
tail -f /var/log/SMLog | grep SMGC- When it finishes, check XO to see if there are any remaining uncoalessed disk and repeat from step 4.
It took about 5 iterations of the above to finally clean up all the stuck coalessed leafs but it eventually did it. The key, for me, was making sure the VM's were not running and turning CBT off.
-
RE: CBT: the thread to centralize your feedback
I think I may have a bit of a similar problem here. About a week ago, I did an update to the broken version of XO and it threw the same error as is in the subject line here. I reverted and everything was OK, but then I started to get unhealthy VDI warnings on my backups.
I tried to rescan the SR and I would see in the SMLog that it believed another GC was running, so it would abort. Rebooting the host was the only way to force the coalesce to complete; however as soon as the next inc-backup ran, it would go into the same problem (the GC thinking another is running and would no do any work).
I then did a full power off of the host, reboot and let all the VM's sit in a "powered off" state, rescanned the SR and let it coalesce. Once everything was idle, I then deleted all snapshots and waited for the coalesce to finish. Only then did I restart the VM's. Now a few VM's immediately have come up as 'unhealthy' and once again the GC will not run, thinking there is another GC working..
I'm kind of running out of idea's 8-) Does anyone know what might be stuck or what I need to look for to find out?
Just a side note here. I noticed that all the VM's that I am having problems with have CBT enabled.
I have a VM that is a snapshot only VM and even when the coalesces is stuck, I can delete snapshots off this non-cbt VM and the coalesces process runs (then gives an exception when it gets to the VM's that have CBT enabled)
Is there a way to disable CBT?
-
RE: starting getting again: ⚠️ Retry the VM backup due to an error Error: VDI must be free or attached to exactly one VM
Just a side note here. I noticed that all the VM's that I am having problems with have CBT enabled.
I have a VM that is a snapshot only VM and even when the coalesces is stuck, I can delete snapshots off this non-cbt VM and the coalesces process runs (then gives an exception when it gets to the VM's that have CBT enabled)
Is there a way to disable CBT?
-
RE: starting getting again: ⚠️ Retry the VM backup due to an error Error: VDI must be free or attached to exactly one VM
I think I may have a bit of a similar problem here. About a week ago, I did an update to the broken version of XO and it threw the same error as is in the subject line here. I reverted and everything was OK, but then I started to get unhealthy VDI warnings on my backups.
I tried to rescan the SR and I would see in the SMLog that it believed another GC was running, so it would abort. Rebooting the host was the only way to force the coalesce to complete; however as soon as the next inc-backup ran, it would go into the same problem (the GC thinking another is running and would no do any work).
I then did a full power off of the host, reboot and let all the VM's sit in a "powered off" state, rescanned the SR and let it coalesce. Once everything was idle, I then deleted all snapshots and waited for the coalesce to finish. Only then did I restart the VM's. Now a few VM's immediately have come up as 'unhealthy' and once again the GC will not run, thinking there is another GC working..
I'm kind of running out of idea's 8-) Does anyone know what might be stuck or what I need to look for to find out?
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
Actually, another cool feature I just noticed is that I am now able to take snapshots of my Windows 11 VM's with vTPM attached.. So.. The day is just getting better and better..
I havent tried doing a backup / export yet.. I think that if it worked, I would be overwhelmed with to0 much good news for a single day and faint
") LOL
LOL -
RE: XCP-ng 8.3 betas and RCs feedback 🚀
OMG! I have just noticed that on the latest beta of 8.3 the Garge Collector gives a percentage of completion in XO(a) "Tasks" and estimation of time to completion!
THANK YOU!! THANK YOU!! THANK YOU!!!
-
RE: backups started failing: Error: VDI must be free or attached to exactly one VM
Oh.. Just a side note here: I went into the backup history and "restarted" the backups on the failed VM's and both VM's backed up successfully. Huh...
-
RE: backups started failing: Error: VDI must be free or attached to exactly one VM
Hi Guys, Just chimeing in that I am seeing the same problem


-
CleanVm incorrect backup size in metadata
Hi all,
I keep seeing this weird error in the logs when my incremental backups run every night. It dosent appear to be causing a problem, but it is beginning to drive me a bit mental.
The backups complete without error, but the below is in my logs when I look through them.
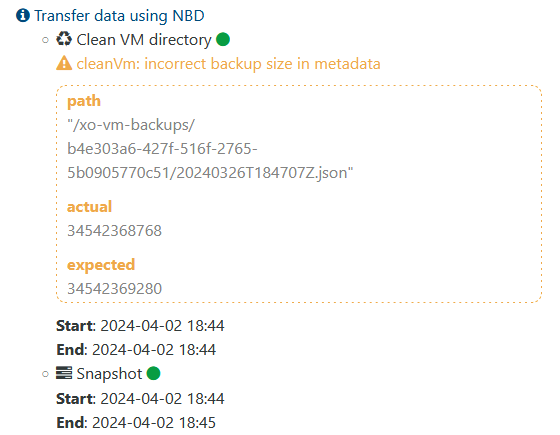
I am using:

Any idea what this might be or how can I clear them. I have about 40 VM's that are showing this problem LOL
-
RE: Mellanox ConnectX-3 - Card not working
@Pyroteq I have seen others mention that its a lack of physical resources being allocated to the card.
As far as the firmware.. I think fw-ConnectX3-rel-2_42 is the latest for that series of card.
-
RE: Mellanox ConnectX-3 - Card not working
@Pyroteq Just as a point of reference, I use Mellanox ConnectX-3 cards all the time in my home lab for 40G Ethernet connection to my SAN. No problems with them at all. But as everyone has mentioned before, be careful of the firmware and model.. Some of the cards will only work in IB mode and others can work in IB or ETH mode.
[09:43 xcp-ng-GHF4 ~]# lsmod | grep mlx mlx4_en 135168 0 mlx4_core 352256 1 mlx4_en devlink 77824 2 mlx4_core,mlx4_en [09:44 xcp-ng-GHF4 ~]#[09:44 xcp-ng-GHF4 ~]# dmesg | grep mlx [ 16.566265] mlx4_core: Mellanox ConnectX core driver v4.0-0 [ 16.566299] mlx4_core: Initializing 0000:03:00.0 [ 22.903721] mlx4_core 0000:03:00.0: DMFS high rate steer mode is: disabled performance optimized steering [ 22.910404] mlx4_core 0000:03:00.0: 63.008 Gb/s available PCIe bandwidth (8 GT/s x8 link) [ 23.122348] mlx4_en: Mellanox ConnectX HCA Ethernet driver v4.0-0 [ 23.122566] mlx4_en 0000:03:00.0: Activating port:1 [ 23.127040] mlx4_en: 0000:03:00.0: Port 1: Using 16 TX rings [ 23.127042] mlx4_en: 0000:03:00.0: Port 1: Using 16 RX rings [ 23.127454] mlx4_en: 0000:03:00.0: Port 1: Initializing port [ 23.128547] mlx4_en 0000:03:00.0: registered PHC clock [ 23.128902] mlx4_en 0000:03:00.0: Activating port:2 [ 23.131517] mlx4_en: 0000:03:00.0: Port 2: Using 16 TX rings [ 23.131518] mlx4_en: 0000:03:00.0: Port 2: Using 16 RX rings [ 23.131678] mlx4_en: 0000:03:00.0: Port 2: Initializing port [ 27.210288] mlx4_core 0000:03:00.0 side-9894-eth2: renamed from eth2 [ 27.244783] mlx4_core 0000:03:00.0 side-701-eth3: renamed from eth3 [ 35.418878] mlx4_core 0000:03:00.0 eth0: renamed from side-9894-eth2 [ 35.582138] mlx4_core 0000:03:00.0 eth4: renamed from side-701-eth3 [ 38.171360] mlx4_en: eth4: Steering Mode 1 [ 38.189737] mlx4_en: eth4: Link Up [ 38.726934] mlx4_en: eth0: Steering Mode 1 [ 38.744587] mlx4_en: eth0: Link Up [ 41.586228] mlx4_en: eth4: Steering Mode 1 [ 41.756191] mlx4_en: eth0: Steering Mode 1 -
RE: XCP-ng 8.3 betas and RCs feedback 🚀
So I got a weird one. I have installed the latest XCP 8.3 updates and rebooted my server. All the VM's I had on my test server worked perfectly fine except for a single Debian 9 VM that would start booting and then "power off" just as the kernel started to spit stuff on the display.
I banged around with it for a while and what I found is its a kernel crash somewhere when SMP is initialized. If I only give a single vProc to the VM, it boots normally and all works fine.
At this point, its not causing me any more problems because I jsut rebuilt the VM on something more modern (Rocky 9)
I have perserved this VM if the dev's would like to get more debugging information or wish to try anything. I can also capture the logs if its of interest.
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
@ravenet This worries me because I use the Connectx-3 cards in my setup. I wonder if I am going to run into the same problem or is it only a Connectx-4 problem.
-
RE: EOL: XCP-ng Center has come to an end (New Maintainer!)
@michael-manley Lovely! If you need beta testers, let me know... I use XCP-ng Center quite a bit and would not like to see it die either.
-
RE: XCP-ng 8.3 betas and RCs feedback 🚀
Hi All,
Let me first say that I am using 8.3 Beta in my home lab and I quite like it. Seems stable and all is good in the world so far..
But I was wondering something. If 8.3 is not going to be a LTR, is there any point in upgrading my production stacks to it or should I just wait for 8.4 (I presume that is what will be the LTR).
I am assuming that if you needed some latest and greatest bleeding feature (maybe TPM?) then you should go 8.3?
I just dont want to go through the trouble of upgrading everything to 8.3 and then 6 months later having to do it again for 8.4
Kind Regards,
Peg -
Any reason to not use NBD?
Hi Everyone,
I was wondering if anyone could offer some insight or advice. I have recently turned on "Use NBD Protocol" option for my local backups and CR backups between various DC's.
I must say that I am very impressed with this option. Using a concurrency of 1, the conventional backups give me a 300Mb/s throughput between Data Centres and with NBD enabled, I get roughly 790Mb/s (over a 1Gb line). So.. YEA!!
I have also noticed that if I re-dimension a VDI, it dosent trash the entire backup, but seems to understand that the VDI had expanded and writes the new data in the current backup, so again.. YEA!!
But I was wondering.. Is there any reason to not use NBD? Having the option to enable or disable almost makes me feel as if there could be a potential downside that I am unaware of.
Thanks in advance,
~Peg -
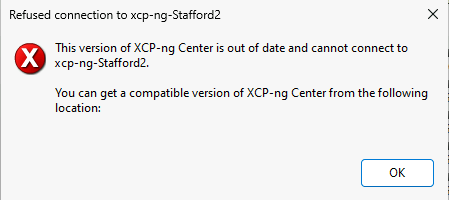
RE: XCP-ng Center and XCP-ng 8.3 beta
@borzel WooHoo! Success!! Thank you...
All my pools were able to be attached now
-
RE: XCP-ng Center and XCP-ng 8.3 beta
@borzel Thanks for that.. It works great on my 8.3 test server, but the 8.2 pools it truely hates! LOL