Yeah, it does not show up as an available device in XOA or XCP-ng Center. Just listed when running lspci
J
Offline
Posts
-
RE: Ghost PCI device - how to remove?
-
Ghost PCI device - how to remove?
At one point there was a 10GbE NIC in one of my servers, but has since been removed. A GPU has been installed, but the system is showing the old nic still sitting at 07:00.0 which is also the GPU.
What would be the best way to get rid of this ghost nic from the system so that I can effectively get this GPU assigned?
Thanks!
-
OPNsense in VM - VIF discrepancies
I've got my OPNsense (FreeBSD) router running in a VM on XCP, and it does have the xe-guest-utilities installed. I'm trying to figure out an issue on one of the interfaces, and I noticed a weird discrepancy in XO with this VM. The MAC addresses and such for the interfaces being used by the VM are all off.
It seems that VIF #0 is the only one coming up correctly.
Unfortunately, I don't think the FreeBSD or OPNsense teams have a maintainer for the xe-guest-utilities package, and so what they distribute is showing as 6.2.1-76888 in XO.
I don't know if this is what is causing my network issue, but I thought it strange.
-
RE: Networking disparity between guest OS and XO
I tried a full shutdown. I let it go full "red" before clicking the start icon. XO is still reporting very different MAC and IP assignments from what the guest OS has configured. Is it perhaps due to the tools that OPNsense packages?
-
Networking disparity between guest OS and XO
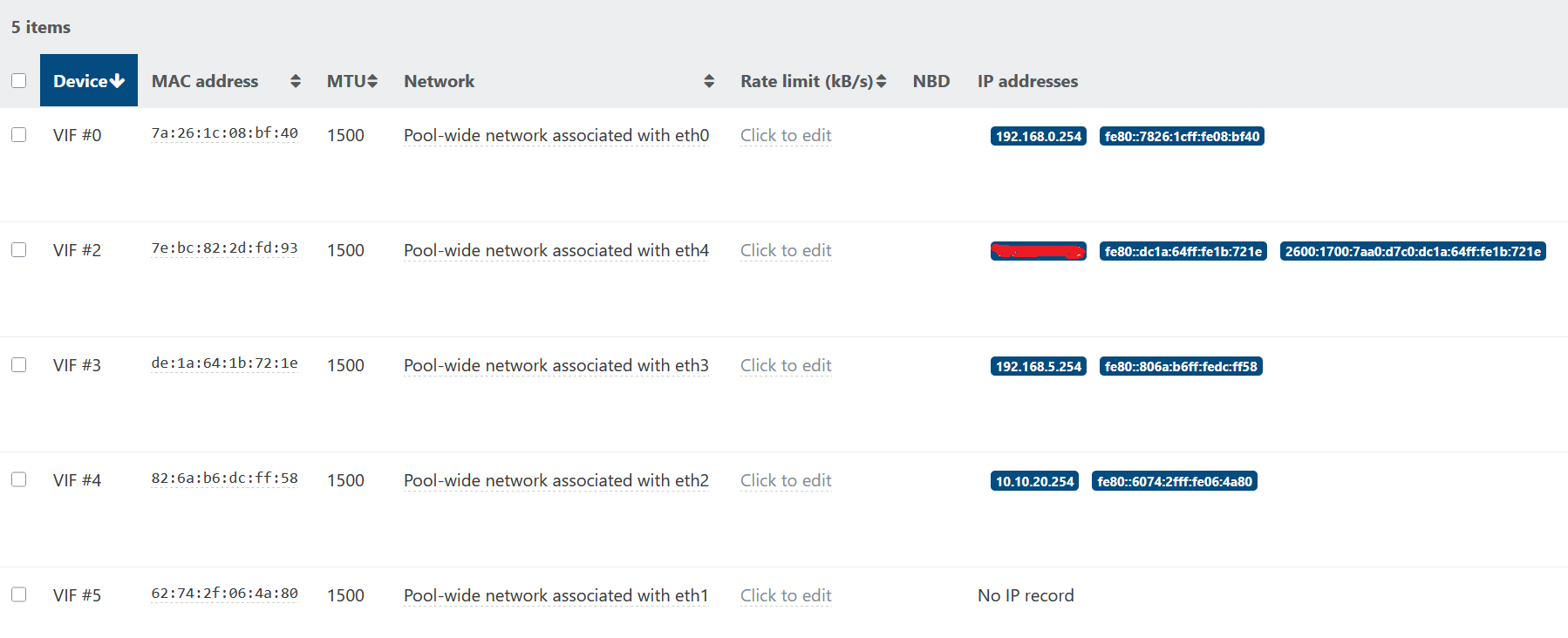
I have my router (OPNsense) running in a VM on XCP 8.2 and there seems to be a disparity between what XO is reporting from the guest utils and what the guest OS itself is saying.
In the guest OS, interface with MAC ending in 72:1e is my WAN interface, getting a DHCP address from my ISP. In XO, that interface is a static IP.
Here are two example interface assignments in the guest OS:

Here is how each of those is configured:
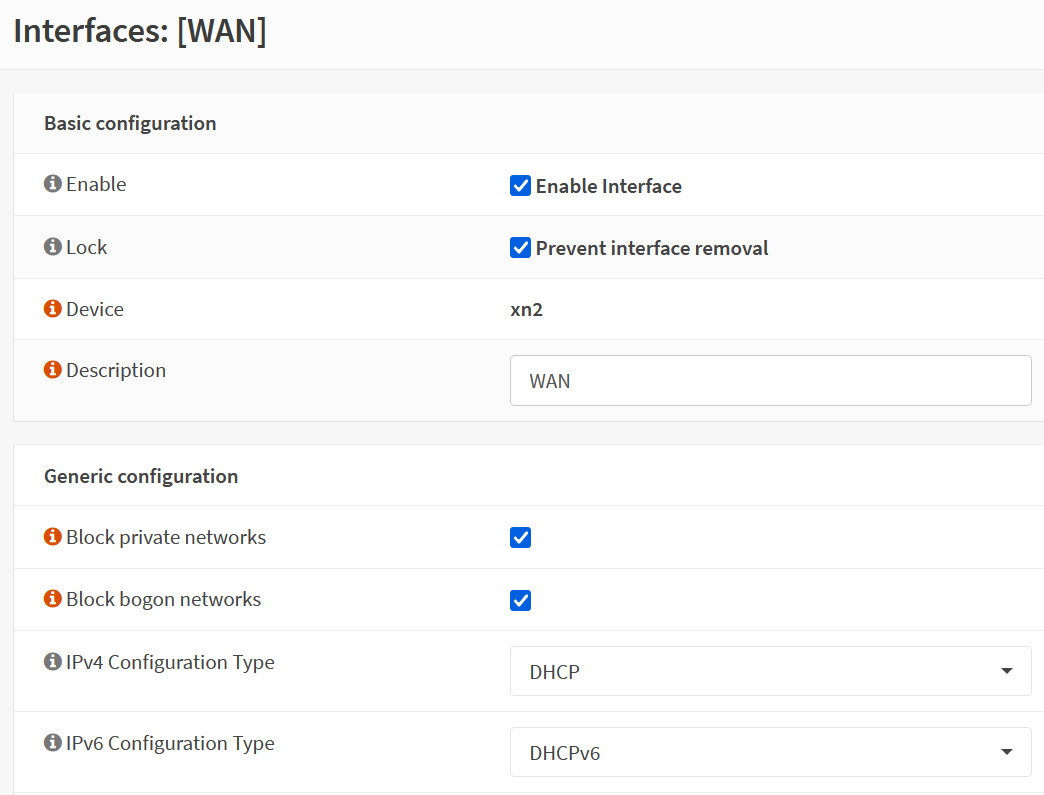
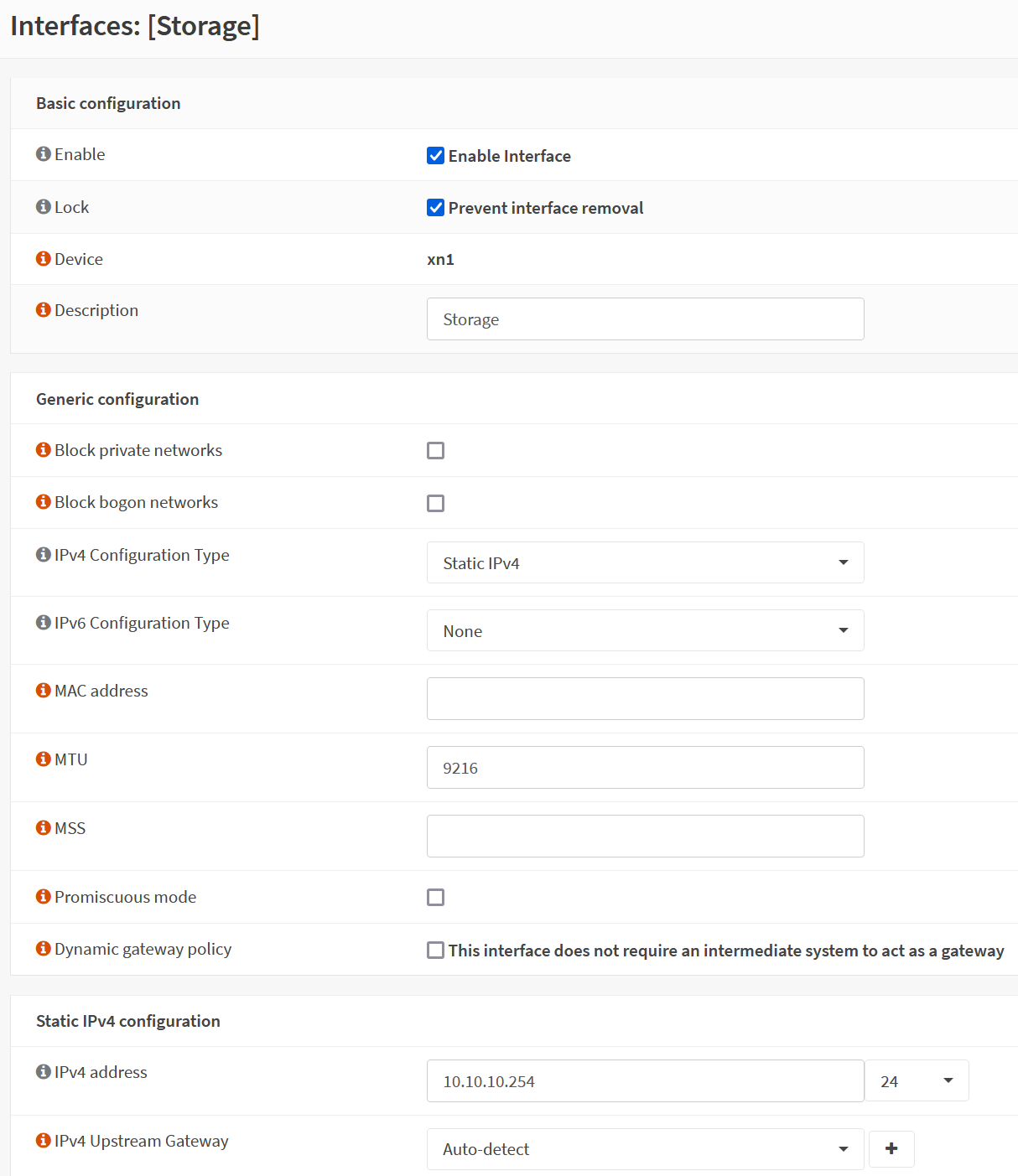
Here is how XO is reporting them:

That interface with the Jumbo Frames configured should be a 10.10.10.X address, per the OS config. That 192.168.5.X is on a completely different interface in the OS, and the MAC X:X:X:X:72:1e should be having the address currently shown on X:X:X:X:fd:93
Any suggestions? Because resolving networking issues when I can't get the information sources to align is problematic.
Thanks!
-
Restore missing network to host
I have a couple of networks created for VLAN tagging purposes. These networks show on the Pool networking tab. They also appear on the two hosts that aren't the master. They are missing from the master node's network tab. Now, I can't migrate any VMs that have interfaces on these networks to the master host.
Is there a way to recreate those networks on just the one host? Being the master that is missing them, I'm afraid they'll disappear altogether at some point and those VMs will have issues.
Thanks!
-
RE: Not a real issue, just looking for some knowledge ...
@olivierlambert Fair enough. I will bring the disk for this VM onto the local SR for patching and rebooting my file server that hosts the NFS SR, just to be on the safe side.
I was hoping I could minimize the downtime by live-migrating the disk onto the host running it, but get the same error about PCI hardware as if I were trying to migrate the whole VM to another host.
But as far as you know, there is no technical reason for why it wouldn't work, like there is for live-migrating between hosts with passed-through hardware.
-
Not a real issue, just looking for some knowledge ...
I have a VM that has a GPU assigned via PCIe passthrough, with its disk on an NFS SR. I understand why I can't live migrate a VM that utilizes PCIe passthrough.
But what is it that prevents migrating just the virtual disk to the local SR on the host running that VM?
-
RE: Transport-email and Google SMTP
@Darkbeldin I wasn't sure about turning on two-factor. I went through that process and generated the "app password" and it seems to be working.
Thanks for the info!
-
Transport-email and Google SMTP
With Google essentially shutting off "less secure app access" in May, is there anything on the horizon for the email plugin to still function with Google's SMTP? I noticed my alerts stopped working, and when I checked my Google dashboard for the account that sends the alerts, Google had shut off the "less secure 3rd party apps access" automatically, and turning it back on was accompanied by a warning that it was being turned off permanently on May 20, 2022.
-
RE: Applied recent patches ... Now getting CPU errors
@Danp No, but I seem to have figured it out. Its a weird one, considering the platform.
These are HP DL360s, with fully licensed iLOs. But ... the CPU errors are gone if I physically connect a keyboard to the server. If I reboot just monitoring via remote console in the iLO, I get the errors. If I go to the machines and connect a USB keyboard before the reboot, then go back to my workstation and do it all through XO and watch via remote console, they come up fine. My post earlier about two coming up fine, I remembered that coincidentally, I'd switched the KVM to them.
So just an FYI to anyone who might have the same problem, plug in a keyboard.
-
RE: Applied recent patches ... Now getting CPU errors
@stormi Yeah, I spoke too soon. Two of my hosts came right up fine after the patches. The third has been in a boot loop with CPU panics and fatal page faults.
-
RE: Applied recent patches ... Now getting CPU errors
Just as an FYI, the latest patches - 20190314-2.xcp - seem to not have an issue. The system patched and booted up just fine with no issues bringing up CPUs or anything like that.
-
RE: Applied recent patches ... Now getting CPU errors
@stormi I'll try that. If I update via CLI, I think I can use "yum update --exclude=microcode_ctl*" and see what happens. If I remember correctly, it was stating 22 patches missing when I started this process with the patches released last week. Now the fresh install is stating 43 missing patches.
-
RE: Applied recent patches ... Now getting CPU errors
@stormi I got a new master, and recovered the other slave. I did a fresh reinstall of the 8.2.0 ISO and the host came up just fine. So there's definitely something in the new code that breaks these machines.
-
RE: Applied recent patches ... Now getting CPU errors
@stormi I guess I don't know how to do that. Using the console "Resource Pool Configuration" -> "Designate a new pool master" results in a "This host is not a Pool member" message for both nodes.
Edit: I found an older post with the xe commands for emergency transition.
-
RE: Applied recent patches ... Now getting CPU errors
@stormi Even using the old kernel, I get issues booting. I'll try using my original install media to see if it will boot from USB. The problem I am having is that this is my master node, and I can't get another node to become master and get control of my VMs. Another node isn't becoming the new master for the remaining two nodes.
Update: Booting to the 8.2.0 install ISO, it booted into the installer just fine.
-
RE: Applied recent patches ... Now getting CPU errors
The problem is, the system won't boot. It gets to that error and immediately just reboots. I got a screenshot only via the iLO remote console and having my finger on the printscreen key ready to grab before it went back to POST.
-
RE: Applied recent patches ... Now getting CPU errors
I am at the latest I have access to, which is P71 05/24/2019 ... and near as I can tell searching HPE Support, that is the latest available. If there's a later one, I can't find it.