This issue appears to have been resolved by a recent change.
J
Offline
Posts
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
-
RE: Timestamp lost in Continuous Replication
I observed similar behaviour.
Two pools. Pool A composed of two hosts. Pool B is single-host. B runs a VM with XO from source. Two VMs on host A1 (on local SR), one VM on host
B1A2 (on local SR).Host A2 has a second local SR (separate physical disc) used as the target for a CR job.
CR job would back up all four VMs to the second local SR on host A2.
The behaviour observed was that, although the VM on B would be backed up (as expected) as a single VM with multiple snapshots (up to the 'replication retention'), the three other VMs on the same pool as the target SR would see a new full VM created for each run of the CR job. That rather quickly filled up the target SR.
I noticed the situation was corrected by a commit on or about the same date reported by @ph7.
Incidentally, whatever broke this, and subsequently corrected it, appears to have corrected another issue I reported here. I never got a satisfactory answer regarding that question. Questions were raised about the stability of my test environment, even though I could easily reproduce it with a completely fresh install.
Thanks for the work!
edit: Correction
B1A2 -
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
There are no other jobs.
I've now spun up a completely separate, fresh install of XCP-ng 8.3 to test the symptoms mentioned in the OP.
Steps taken
- Installed XCP-ng 8.3
- Text console over SSH
-
xe host-disable
-
xe host-evacuate(not needed yet of course since it's a brand-new install)
-
yum update
-
- Reboot
- Text console over SSH again
-
- Created local ISO SR
-
-
xe sr-create name-label="Local ISO" type=iso device-config:location=/opt/var/iso_repository device-config:legacy_mode=true content-type=iso
-
-
-
cd /opt/var/iso_repository
-
-
-
wget # ISO for Ubuntu Server
-
-
-
xe sr-scan uuid=07dcbf24-761d-1332-9cd3-d7d67de1aa22
-
- XO Lite
-
- New VM
-
- Booted from ISO, installed Server
- Text console to VM over SSH
-
- apt update/upgrade
-
- installed xe-guest-utilities
-
- Installed XO from source (ronivay script)
- XO
-
- Import ISO for Ubuntu Mate
-
- New VM
-
-
- Booted from ISO, installed Mate
-
-
-
- apt update/upgrade
-
-
-
- xe-guest-utilities
-
-
- New CR backup job
-
-
- Nightly
-
-
-
- VMs: 1 (Mate)
-
-
-
- Retention: 15
-
-
-
- Full: every 7
-
Exact same behaviour. After first (full) CR job run, additional (incremental) CR job runs results in one more 'unhealthy VDI'.
I've engaged in no other shenanigans. Plain vanilla XCP-ng and XO. There are only two VMs on this host, the XO from source VM, and a desktop OS VM which is the only target of the CR job. There are zero exceptions in SMlog.
What do you need to see?
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
@olivierlambert said in Every VM in a CR backup job creates an "Unhealthy VDI":
So why it fails on your specific case? I would first make things clean in the first place, remove corrupted VHD, check all chains are clear everywhere and start a CR job again. I bet on a environment issue, causing a specific bug, but there's no many factors that's it's really hard to answer.
How about this specific case?:

Completely different test environment. Completely different host (single-host pool), completely different local SR, completely different VMs, NO exceptions in SMlog, similar CR job. Same result. Persistent unhealthy VDI reported in Dashboard->Health, one for each incremental of each VM in the CR job (currently only one, the XO VM).
Since nobody seems to think this should be happening, are there any thoughts on what I'm missing? Is there some secret incantation required on job setup?:

-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
I can answer the question: not on a different pool, but coalesce for the whole pool with a shared SR yes (a broken VHD will break coalesce on the entire SR it resides on, not on the others).
There are no shared SR in my test environment, except for a CIFS ISO SR.
This is a thumbnail sketch:
Pool X: - Host A - Local SR A1 - Running VMs: - VM 1 (part of CR job) - VM 2 (part of CR job) - VM 3 - Halted VMs: - Several - Host B - Local SR B1 - Running VMs: - VM 4 (part of CR job) - VM 5 - VM 6 - Halted VMs: - Several - Local SR B2 - Destination SR for CR job - No other VMs, halted or running Pool Y: - Host C (single-host pool) - Local SR C' - Running VMs: - VM 7 (part of CR job) (also, instance of XO managing the CR job) - Halted VMs: - SeveralThere are other pools/hosts, but they're not implicated in any of this.
All of the unhealthy VDIs are on local SR B2, the destination for the CR job. How can an issue with coalescing a VDI on local SR A1 cause that? How can a VM's VDI on pool Y, host C, local SR C1, replicated to pool X, host B, local SR B2, be affected by a coalesce issue on with a VDI on pool X, host A, local SR A1?
Regarding shared SR, I'm somewhat gobsmacked by your assertion that a bad VDI can basically break an entire shared SR. Brittle doesn't quite capture it. I honestly don't think I could recommend XCP-ng to anyone if that were really true. At least for now, I can say that assertion is demonstrably false when it comes to local SR. As I've mentioned previously, I can create and destroy snapshots on any VM/host/SR in my test environment, and they coalesce quickly and without a fuss, >>including<< snapshots against the VMs which are suffering exceptions as detailed above.
By the way, the CR ran again this evening. Four more unhealthy VDIs.
Tomorrow I will purge all CR VMs and snapshots, and start over. The first incremental will be Saturday night. We'll see.
I've also spun up a new single host pool, new XO instance, and a new CR job to see if it does the same thing, or if it behaves as everyone seems to say it should behave. I'm more interested in learning why my test environment >>doesn't<<.
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
Are you sure? Because that doesn't appear to be true. Coalescing works just fine on every other VM and VDI I have in my test environment. I can create and later delete snapshots on any VM and they coalesce in short order.
If you're suggesting that an issue with coalescing one VDI chain could adversely affect or even halt coalescing on completely unrelated VDI chains on the same host, on a different host in the same pool, and in a completely different pool, I have to say I can't fathom how that could be so. If the SR framework were so brittle, I'd have to reconsider XCP-ng as a virtualisation platform.
If someone can explain how I'm wrong, I am more than willing to listen and be humbled.
As I've tried to explain, the two VDI that don't coalesce are not related to the CR job. They amount to a base copy and the very first snapshot that was taken before the first boot of the VM. The SMlog error mentions 'vhd not created by xen; resize not supported'. I deleted that snapshot a long time ago. The delete 'worked', but the coalesce never happens as a result of the 'not created by xen' error.
I can even create snapshots in this very VM (the one with the persistent base copy and successfully-deleted-snapshots VDIs). Later I can delete those snapshots, and they coalesce happily and quickly. They all coalesce into that first snapshot VDI deleted long ago. It is that VDI which is not coalescing into the base copy.
The other exception is on a VDI belonging to a VM which is not part of the CR job.
I'd like to return to the OP. Why does every incremental CR leave behind a persistent unhealthy VDI. This cannot be related to a failed coalesce on one VM on one host in one pool. All my pools, hosts, and VMs are affected.
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
Thank you. I've had a look at your logs in that post, and they don't bear much resemblance to mine. Your VDI is qcow2, mine are vhd. The specific errors you see in your logs:
Child process exited with errorCouldn't coalesce onlineThe request is missing the serverpath parameter... don't appear in my logs, so at least on first blush it doesn't appear to be related to either of the two exceptions in my own logs... and >>mine<< don't appear to belated to the subject of my OP.
@joeymorin said:
These fixes, would they stop the accumulation of unhealthy VDIs for existing CR chains already manifesting them? Or should I purge all of the CR VMs and snapshots?Anyone have any thoughts on this? I can let another incremental run tonight with these latest fixes already applied. If I get find round of unhealthy VDIs added to the pile, I could try removing all trace of the existing CR chains and their snapshots, and the let the CR job try again from an empty slate...
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
[09:24 farmer ~]# zcat /var/log/SMlog.{31..2}.gz | cat - /var/log/SMlog.1 /var/log/SMlog | grep -i "nov 12 21" | grep -i -e exception -e e.x.c.e.p.t.i.o.nNov 12 21:12:51 farmer SMGC: [17592] * E X C E P T I O N * Nov 12 21:12:51 farmer SMGC: [17592] coalesce: EXCEPTION <class 'util.CommandException'>, Invalid argument Nov 12 21:12:51 farmer SMGC: [17592] raise CommandException(rc, str(cmdlist), stderr.strip()) Nov 12 21:16:52 farmer SMGC: [17592] * E X C E P T I O N * Nov 12 21:16:52 farmer SMGC: [17592] leaf-coalesce: EXCEPTION <class 'util.SMException'>, VHD *6c411334(8.002G/468.930M) corrupted Nov 12 21:16:52 farmer SMGC: [17592] raise util.SMException("VHD %s corrupted" % self) Nov 12 21:16:54 farmer SMGC: [17592] * E X C E P T I O N * Nov 12 21:16:54 farmer SMGC: [17592] coalesce: EXCEPTION <class 'util.SMException'>, VHD *6c411334(8.002G/468.930M) corrupted Nov 12 21:16:54 farmer SMGC: [17592] raise util.SMException("VHD %s corrupted" % self)None relevant to the CR job. The one at 21:12:51 local time is related to the 'resize not supported' issue I mention above. The two at 21:16:52 and 21:16:54 are related to a fifth VM not in the CR job (the test VM I don't care about, but may continue to investigate).
The other two hosts' SMlog are clean.
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
Three separate hosts are involved. HR-FS and zuul are on one, maryjane on the second, exocomp on the third.
Total, over 17,000 lines in SMlog for the hour during the CR job. No errors, no corruptions, no exceptions.
Actually, there are some reported exceptions and corruptions on farmer, but none that involve these VMs or this CR job. A fifth VM not part of the job has a corruption that I'm still investigating, but it's on a test VM I don't care about. The VM HR-FS does have a long-standing coalesce issue where two .vhd files always remain, the logs showing:
FAILED in util.pread: (rc 22) stdout: '/var/run/sr-mount/7bc12cff- ... -ce096c635e66.vhd not created by xen; resize not supported... but this long predates the CR job, and seems related to the manner in which the original .vhd file was created on the host. It doesn't seem relevant, since three other VMs with no history of exceptions/errors in SMlog are showing the same unhealthy VDI behaviour, and two of those aren't even on the same host. One is on a separate pool.
SMlog is thick and somewhat inscrutable to me. Is there a specific message I should be looking for?
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
I rebuild XO nightly at 11:25 UTC.
These fixes, would they stop the accumulation of unhealthy VDIs for existing CR chains already manifesting them? Or should I purge all of the CR VMs and snapshots?
As I type, I'm on 2d066, which is the latest. The CR job runs at 02:00 UTC, so had just run when I posted my OP. All of the unhealthy VDIs reported then are still reported now.
-
RE: Every VM in a CR backup job creates an "Unhealthy VDI"
@Andrew, they do not clear up. Please read my OP carefully and look at the screenshot. They remain forever. They accumulate, one for each VM for every incremental. Nightly CR, four VMs, four more unhealthy VDIs. Tomorrow night, four more, etc.
-
Every VM in a CR backup job creates an "Unhealthy VDI"
Greetings,
I'm experimenting with CR backups in a test environment. I have a nightly CR backup job, currently for 4 VMs, all going to the same SR, '4TB on antoni'. On the first incremental (second backup after the initial full) an unhealthy VDI is reported under dashboard/health... one for every VM in the job. A subsequent incremental result in an additional reported unhealthy VDI, again one for each VM.
For example:

The following VMs each currently have the initial full, and three subsequent incrementals in the CR chain:- HR-FS
- maryjane
- zuul
Note that there are three reported unhealthy VDIs for each.
The remaining VM, exocomp, currently has only 1 incremental after the initial full, and there is one reported unhealthy VDI for that VM.
Is this normal? If not, what details can I provide that might help get to the bottom of this?
-
RE: Building from source fails with commit cb96de6
@Andrew many thanks. As do I. See my OP.
A failed build doesn't break XO. It leaves the previous successful build in place.
My post wasn't to ask how to fix my problem, but to point out the issue to others who might care to know (see my last post).
Cheers.
-
RE: Building from source fails with commit cb96de6
@Andrew For the record, that didn't fix it for me.
To be specific, it >>did<< fix the error regarding bigint in QcowDisk.mts, but a new error popped up later in the build:
yarn run v1.22.22 $ TURBO_TELEMETRY_DISABLED=1 turbo run build --filter xo-server --filter xo-server-'*' --filter xo-web turbo 2.5.8 • Packages in scope: xo-server, xo-server-audit, xo-server-auth-github, xo-server-auth-google, xo-server-auth-ldap, xo-server-auth-oidc, xo-server-auth-saml, xo-server-backup-reports, xo-server-load-balancer, xo-server-netbox, xo-server-perf-alert, xo-server-sdn-controller, xo-server-test-plugin, xo-server-transport-email, xo-server-transport-icinga2, xo-server-transport-nagios, xo-server-transport-slack, xo-server-transport-xmpp, xo-server-usage-report, xo-server-web-hooks, xo-web • Running build in 21 packages • Remote caching disabled x Internal errors encountered: external process killed a task error Command failed with exit code 1. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command. + rm -rf /opt/xo/xo-builds/xen-orchestra-202510281354That was with commit 740fc03, the latest at the time of my build at 2025-10-28 17:54 UTC.
It's unclear to me why the build failed exactly. Except that "Internal errors encountered: external process killed a task". I don't know know what that external process was. Unfortunately the 3rd party build script doesn't seem to preserve failed builds, only a slender log file.
I tried again a little later, with commit 87471d9. That succeeded, but it's unclear to me why. Neither commit explains either the failure, nor the success. The only other difference is that with the success, nodejs was updated (automatically, as part of the 3rd party build script) from 22.20.0-1nodesource1 to 22.21.1-1nodesource1, whereas for the failed build it was still 22.20.0-1nodesource1.
I don't know enough about the build process to untangle what happened... but I don't really need to. I can remain ignorant
")
By the way, if my initial post was closer to static noise than useful feedback, please forgive, and please let me know. It was really just an FYI to those who may be both listening and desiring to know. I see things move fast with the repo, with ten or more commits some days, so maybe flooding the forums with 'my build failed!' posts isn't helpful.
-
Building from source fails with commit cb96de6
Greetings all,
Subject pretty much says it. Build output goes sideways starting with:
@xen-orchestra/qcow2:build: src/disk/QcowDisk.mts(94,52): error TS2365: Operator '&' cannot be applied to types 'bigint' and 'number'.Looking at github, the errant commit is cb96de6:
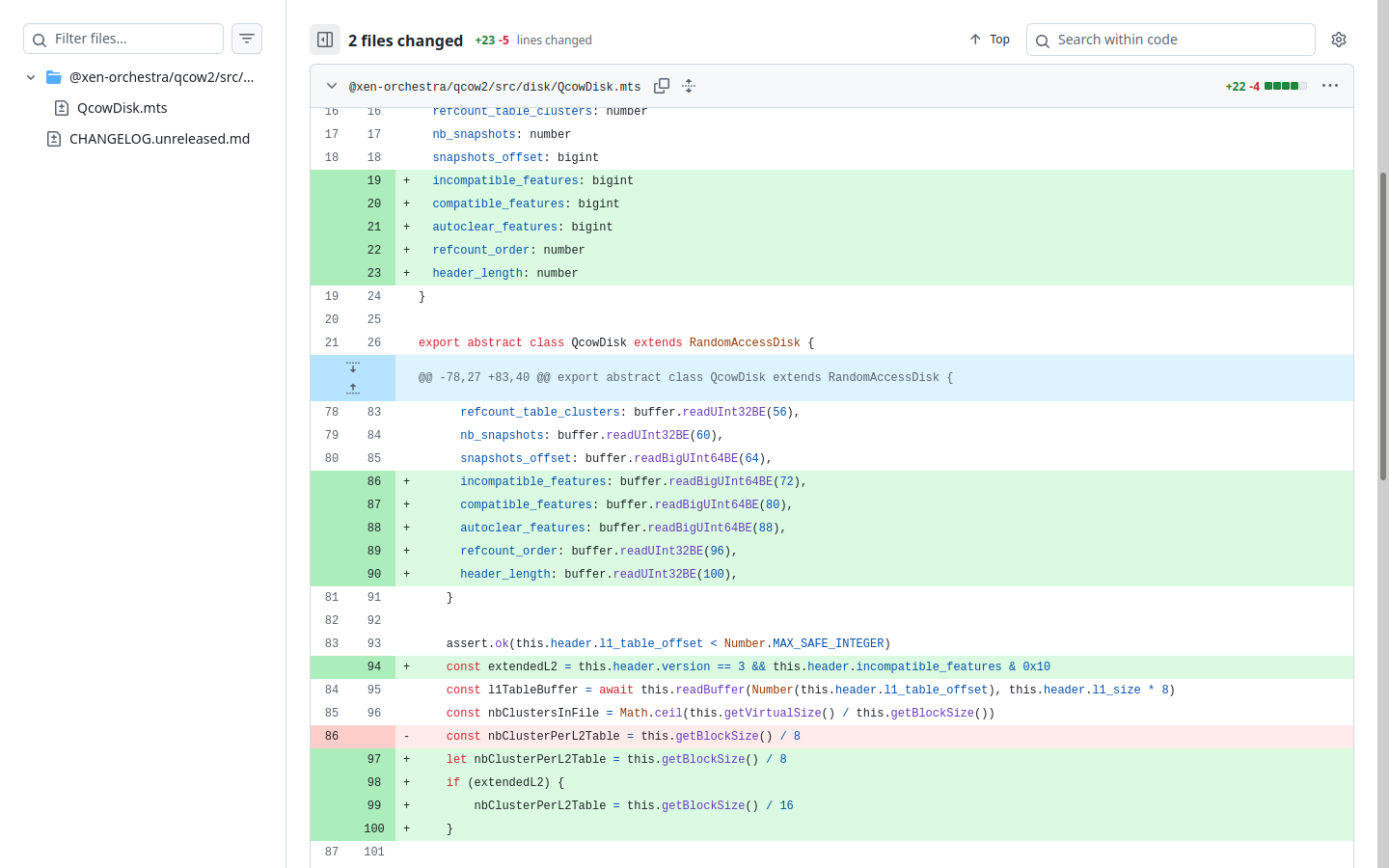
As of this post, latest commit is bf705, with two additional commits in between, none of which address this issue.
My build environment is Ubuntu Server 24.04 LTS, with all updates applied, building with ronivay's install script. While I'm aware of the caveat:
This script is not supported or endorsed by Xen Orchestra. Any issue you may have, please report it first to this repository.... the issue doesn't appear to be related to the script, but the source code. If I'm mistaken, please forgive the intrusion.
Any immediate thoughts on whether this is a proper bug? Or, is it instead an issue with my build environment?
Cheers.
-
RE: qemu-img formats
Late to the game, but this might help someone...
I don't recommend this in a production environment, but it would be fine for e.g. a home lab.
I built qemu from source on another host (in my case, on a laptop running Ubuntu Mate):
./configure --static make... and then sftp'd the generated qemu-img executable to the XCP-ng host (I didn't care about any other outputs from the build process, some of which failed anyway likely due to the ancient version of Ubuntu Mate running on my laptop).
Building with --static avoided any issues with missing libraries on the XCP-ng host, at least for qemu-img.