@Danp Unfortunately, there is only one user account. Might be quickest to stand up another instance. The only annoyance will be that I would lose the backup jobs.
Posts
-
RE: Remove/Reset TOTP 2FA
-
Remove/Reset TOTP 2FA
Long story short, the only key for one of my installs was inadvertently destroyed. Is there a quick way to disable TOTP temporarily from the command line?
-
RE: SENDING Special keys to guest via xo-web
@olivierlambert buttons like the existing ctrl+alt+del to switch consoles on Linux would be awesome! (ctrl+alt+F2, etc.)
-
RE: Testing S3 Remotes (I can sort of break it!)
@akurzawa Well, it does say beta. I was trying different use cases and posting my results in case it's being actively worked on.
It does work very reliably on my minio instance on my NAS so long as it's doing only one disk.
-
RE: Testing S3 Remotes (I can sort of break it!)
By the way, this testing was on xo-server 5.80.0 and xo-web 5.84.0. My initial tests were on earlier versions.
I just tried on Backblaze B2 as well, and I am coming up with errors while testing the remote.
Error Error calling AWS.S3.putObject: Non-whitespace before first tag. Line: 0 Column: 1 Char: B Test step writeInitially I had an issue creating the remote, because Backblaze allows uppercase characters in bucket names, and XO would not allow that input.
-
Testing S3 Remotes (I can sort of break it!)
Apologies if some of this doesn't make sense, as I have been running on very little sleep.
I have been testing the S3 remote for use in conjunction with delta backups. I have a host running Minio on TrueNAS to expose an S3 compatible bucket. It appears to die in a certain case. I have several single disk VMs which back up to it consistently with zero failures, but I have one other on the same host and storage, with the only real difference between those successful backed up is the failure VM has two disks. It is failing 100% of the time. Each time I run it, the backup job creates the snapshot with no issues, then when it reaches the transfer phase, disk 0 shows up in the task list with 4% progress right away, but disk 1 hangs at 0%. This goes for about 8 minutes and times out, giving me "Error Calling AWS.S3.upload: http connection timed out" in the logs. If I test the remote immediately after the job fails, it tests OK. I think the two disks uploading at the same time breaks the connection to the remote for some reason. I am curious to try this with a real AWS S3 bucket, and also a backblaze B2, but I haven't tried that yet.
TL;DR I suppose this testing makes my findings a bit of a feature request: Is there a way to set backups to serialize tasks instead of running what appears to be two in parallel? I think that would solve my issue found in testing, and I have had other use cases for backup jobs running tasks one at a time, such as a low bandwidth connection in order to increase the chance of success. I suppose it could go the other way as well in some edge cases: Perhaps a very high-performance setup may wish to do eight tasks in parallel in order to complete backup jobs as quickly as possible.
I just thought I would share my experience and am interested to hear others' experiences with the S3 remotes beta.
-
WORM / immutable backups
Hello,
I am wondering if there is a ready way to use a WORM (write once, read many) type file share as a remote backup target. I am putting some of my backups on a NAS which has this feature available. I have done some experimenting in a test environment where I tested XO backing up to a share like this using the Delta Backup method. My understanding of the way the target works is the remote share's files become read-only after five minutes of inactivity once the file is written. On a fresh target with no previous backups of a particular VM, in my environment it was able to complete an initial full backup successfully. I subsequently attempted to start the backup again after five minutes had passed and the initial backup (and I am assuming some catalog information) had become read only, and the backup job fails, as it seems trying to delete or write to an existing file somewhere. I didn't fully track down what was happening, as I had a good assumption that it was trying to delete or modify an existing file. (The error may have eluded to such.) Like I said, this was just an experiment.
I am already utilizing snapshots on my regular target to somewhat mitigate mutability. I was hoping for something more immediate though.
With the rise in advanced ransomware attacks where attackers are going after backups before encrypting, it would be great if there were a way to back up to a completely immutable destination easily. I understand some of the limitations, such as 100% retention filling the target and inability to do synthetic or real full backups to free disk space. That could be potentially solved during a maintenance window on the remote's end where backups are manually archived or deleted and the remote's entire folder structure could be cleared to start the process all over again. This is just an idea I'm trying to figure out as the datasets I manage aren't growing much, and affordable disks are getting much larger and are outpacing usage.
-
Some thank-yous, feedback, and hints for those trying to get current builds of XO community edition running
TL;DR: Debian 10.2 Netinstall iso, then use Jarli01 install script from Github.
(Current info as of xo-server 5.56.1 with xo-web 5.56.2)Hello everyone! I have been running XCP-ng since right around the time of the release of 7.6, thanks to @flipsidecreations videos about it. I was only somewhat familiar with Xenserver at the time. My company was a VMWare partner at the time, but I was looking for a change, as most potential clients in the area are priced out of VMWare, and it didn't make business sense to pay them the partner fees every year. After seeing some YouTube videos from Tom, I migrated my company's infrastructure to it after playing with it for a while. I'm now on version 8, and have been running really smoothly. Some of my VMs were direct exports from vCenter and imported into XCP-ng with no issues whatsoever.
I have also started getting some of my clients moved to it as we migrate them to new hardware and retiring old Windows Server versions. Today I was having some trouble with throwing together some temporary backups at one client. I was attempting to set up a remote to a SMB share on a PC on the network and use it as a backup target. Using AD domain credentials, I had no issues at all getting the remote connected, but backups were failing at what seemed like random times. something quick like a metadata backup was fine, and I could see the files at the target, but anything that took some time seemed to fail, stating the task was interrupted, same error as if I had aborted the backup task in the task list. I was quick to assume that the network or the target was to blame, as I have had such good luck with everything so far other than a couple of dopey mistakes I made long ago. (Don't look up my previous posts, LOL!) I have been messing with this all evening here, and this is what I found:
Background: my XO instances were set up using a fresh Debian 9 Netinstall media to a VM with more resources provisioned to them than what was probably necessary. I used the install script from @ronivay for my initial installs and updates. That script to build XO from sources wouldn't work when I upgraded to Debian 10, so I stuck with 9. My backups of my own infrastructure were directly to local storage on a separate XCP-ng host, and I haven't had much of an issue with that other than some occasional hangups which would seem to remedy themselves if I rebooted the XO server. I had mixed results trying backups to a SMB share set up as a target. It seemed like intermittently I would get failures. Now at this customer site, I could not get a full backup of even a small machine with a bare install of Windows Server 2019 before failure. I also noticed something weird happening where the on the console tab for a VM the console window would drop and disappear, and some sort of dropped connection error message would pop up and the entire XO site would lock up. This correlated with the failing backups as well. I gave up on the whole XO VM and started from scratch.
What I did successfully: I spun up a new VM, again with too much RAM and processor cores, installed Debian 10.2 netinstall, and again tried a new download of @ronivay's install script. He has it checking OS version, and it failed out on me and aborted because it says it requires Debian 8/9. I think his most recent work is using that on current builds of Ubuntu. I wanted Debian if at all possible, and tried the @DustinB (Jarli01) install script as a last resort before manually doing it myself. My initial Delta Backup of all the VMs on this host (Currently 288GB) to a Windows SMB share remote just completed successfully as I am writing this. Unfortunately, I don't know what the problem's root cause was, but this current setup seems stable.
Thanks again to the Vates team for spearheading what I think is blazing the pathway to the future for the Xen Project and also the community members supporting and helping people with the builds from source. I will surely get clients hooked up with Vates support offerings as soon as I get the opportunity to upgrade a client where it's economically feasible for them to have the support offering. I'd love to work with some paid XOA instances!
-
RE: Monitoring disk usage of thin provisioned disks
Oh boy, this can be complicated. I think I opened up a can of worms!

 I'm really not sure what is most useful until I can see it in action. Another example of where I would use this is to determine if migrating the VM to another SR is possible because of disk space constraints on the target. Again in this case, I would first probably get rid of any snapshots before moving, so really the size of whatever would be moved, possibly including metadata for the VM itself, though that amount is trivial compared to base and active disks.
I'm really not sure what is most useful until I can see it in action. Another example of where I would use this is to determine if migrating the VM to another SR is possible because of disk space constraints on the target. Again in this case, I would first probably get rid of any snapshots before moving, so really the size of whatever would be moved, possibly including metadata for the VM itself, though that amount is trivial compared to base and active disks. -
RE: Monitoring disk usage of thin provisioned disks
What you said so well was my basic understanding, so to use your terminology, adding the active disk plus others in the chain if there are more snapshots, plus the base copy would be what I would think of as current disk usage.
I suspected that to calculate the snapshot size, the coalesce would have to be computed, so that sounds like too much of a strain on the system to implement. I think simply adding up the total size of the chain from the active disk back to the base image and putting that somewhere would be most helpful with the least impact on the systems performance.
-
RE: Monitoring disk usage of thin provisioned disks
I was kind of thinking about that as far as snapshots are concerned. I don't know how to calculate it, but ultimately I would want to know how much disk space would be freed if I deleted a particular snapshot. I understand that could be difficult (impossible?) to determine.
I think the seeing snapshot disk usage is less important than seeing the total SR disk usage of the VM. Typically the first thing I would do when trying to free up disk space would be to just remove unnecessary snapshots first, not really worrying about exactly what size they are.
So in my opinion, the most important thing to see would be the current actual disk usage on the SR for the VM's disks, which I think would be adding up the base vhd size plus the size of all snapshots in the chain and showing that total on the SR disks tab and/or the VM disks tab.
-
RE: Monitoring disk usage of thin provisioned disks
@olivierlambert Yes, I understand this would only be useful for thin provisioned SR. In the past on other hypervisors I had to deal with disk space issues on an SR which was overprovisioned, and it is helpful to quickly determine which VMs are bloating their storage usage to be able to make a decision to delete snapshots or move a VM to a different storage or host. My thought was to see it on the disks listing in the SR in order to see an overview of how that particular SR is being utilized.
I made an example of how it could look based on a screenshot from XO:
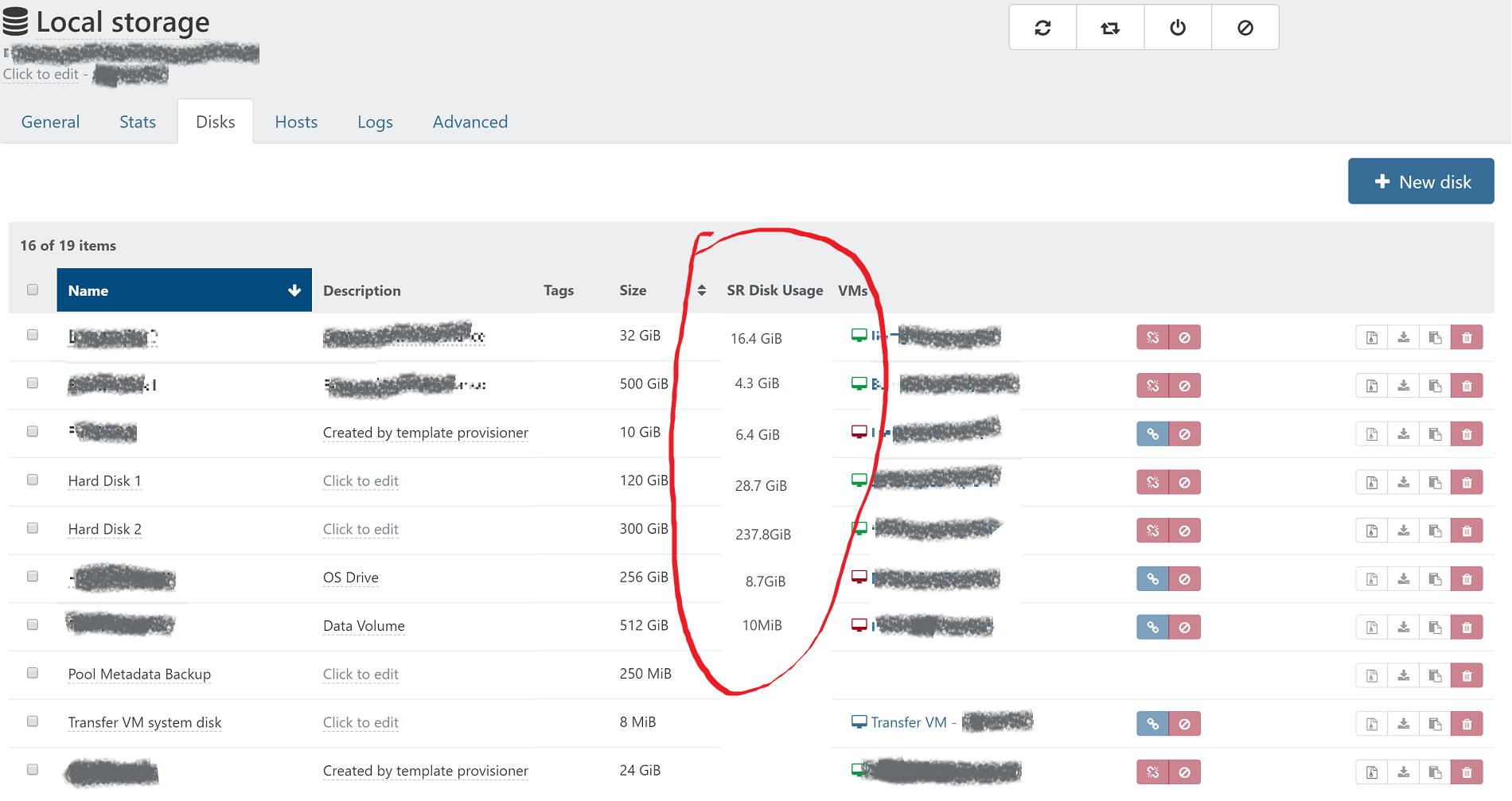
I think it would also be helpful to list the actual disk usage on the disks and snapshots pages for each individual VM. I think the total of base vhd and snapshots on the disks tab, and each individual snapshot size on the snapshots page. Here is how that could look:
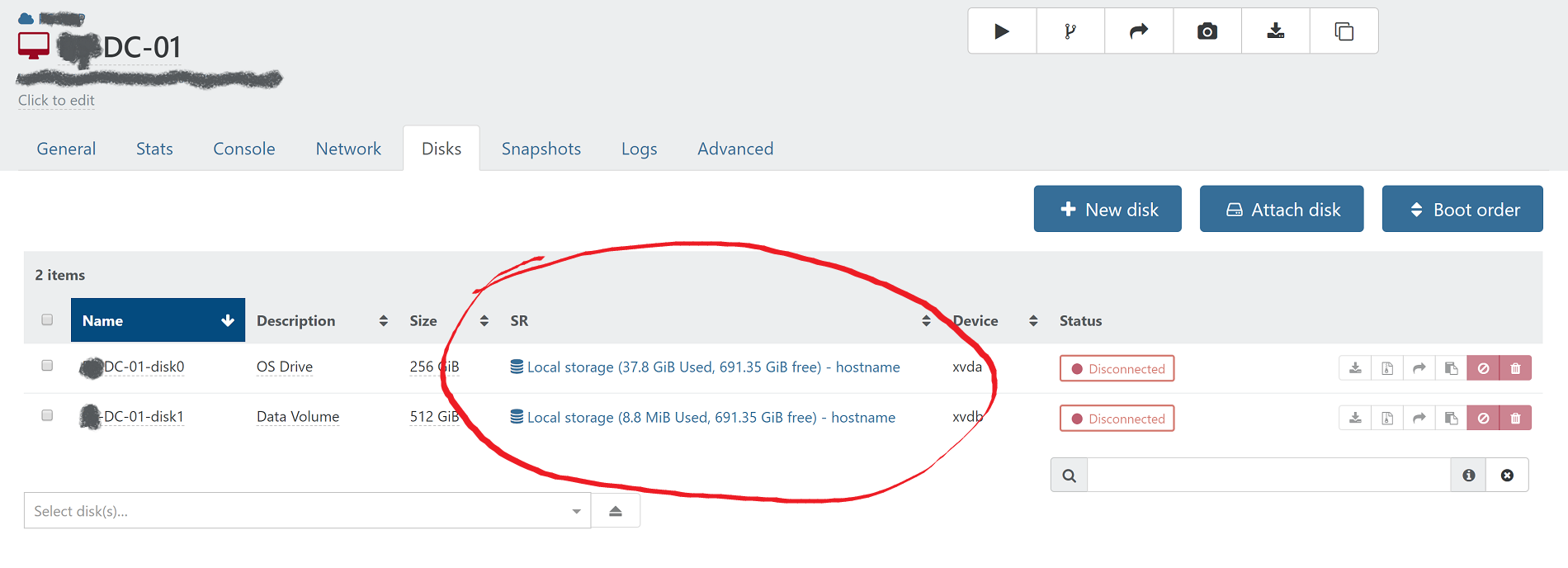
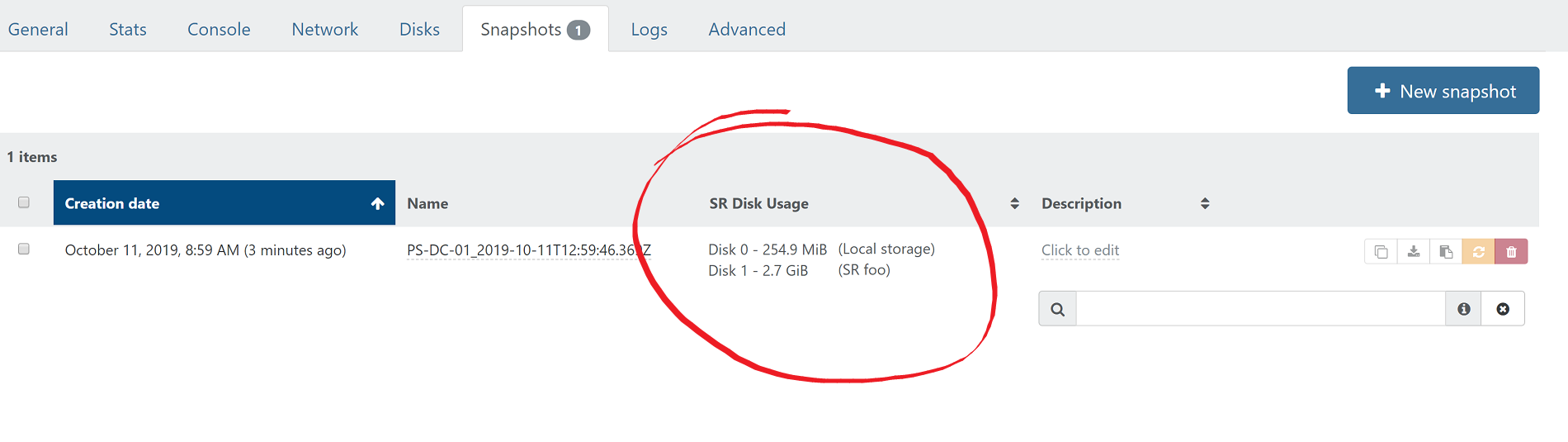
-
RE: Monitoring disk usage of thin provisioned disks
I had trouble with the bash script, as syntax didn't translate well from the website and appears to have sourced another unpublished script which would have to be recreated. also should mention that I am running XCP-ng 8.0.0 on all hosts.
-
Monitoring disk usage of thin provisioned disks
Hello,
I have several hosts in production with thin provisioned disks on Ext3 SRs. I'm looking for a way to see the actual disk usage of each VHD or at least each virtual machine, but I am not seeing this anywhere. I can see total disk usage of the SR and how much I have overprovisioned, but I am not seeing actual disk usage of each VHD and/or snapshots. (I don't currently have any snapshots, as I generally run a full replication to my second site before major changes to VMs.)
I found this thread where someone wrote a bash script I have yet to try, but I would much rather see this on a web interface as opposed to getting a console on dom0 and running a script against individual VMs. Am I missing it somewhere? (entirely possible)
Thanks for all you do, Olivier and team!