S
Offline
Posts
-
RE: Problems with existing pool, problems migrating to new pool
OK, just a follow-up.
- Tried removing the host using XO, and that failed because it wasn't online.
- Tried removing from the command line using the a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8 uuid but that wasn't recognized.
- Removed it from the command line using the uuid that came up in the xe host-list command.
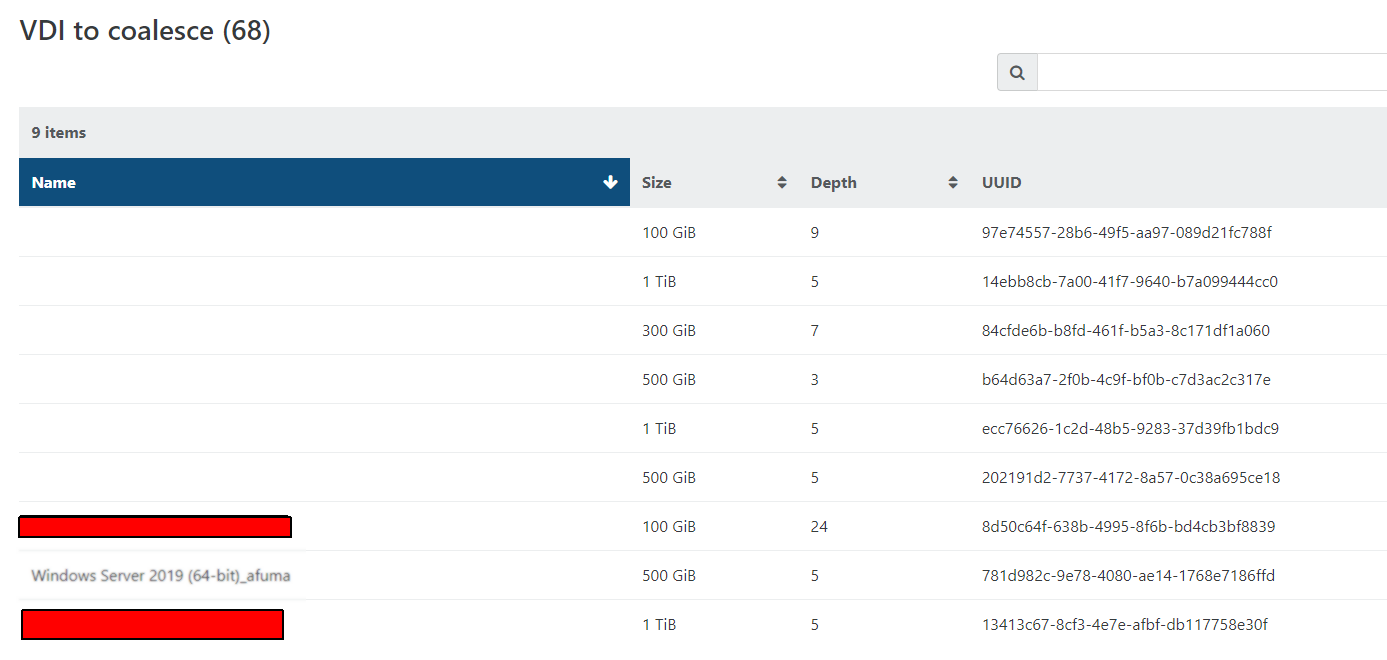
- Now I see metrics on the pool picking up, and the number of VDIs to coalesce has already moved from 68 to 66.
For someone who runs across this in the future...(Don't ask me about that load average.)
[23:29 xcp-ng-1 ~]# w 23:43:09 up 80 days, 5:33, 2 users, load average: 551.01, 550.52, 549.49 USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT root pts/3 192.168.9.151 17:47 1.00s 0.25s 0.23s -bash root pts/0 14:28 9:14m 0.05s 0.05s -bash [23:43 xcp-ng-1 ~]# xe host-forget uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8 The uuid you supplied was invalid. type: host uuid: a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8 [23:43 xcp-ng-1 ~]# xe host-lits Unknown command: host-lits For usage run: 'xe help' [23:43 xcp-ng-1 ~]# xe host-list uuid ( RO) : 78913a9f-e36e-419e-9e84-9fc43127558f name-label ( RW): xcp-ng-1 name-description ( RW): Default install uuid ( RO) : 0840e7a3-e82a-4f48-803b-08c3a082af88 name-label ( RW): xcp-ng-3 name-description ( RW): Default install uuid ( RO) : 7a49f91f-4701-4a95-b73c-be8235878ecf name-label ( RW): xcp-ng-2 name-description ( RW): Default install [23:44 xcp-ng-1 ~]# xe host-forget uuid=0840e7a3-e82a-4f48-803b-08c3a082af88 WARNING: A host should only be forgotten if it is physically unrecoverable; WARNING: if possible, Hosts should be 'ejected' from the Pool instead. WARNING: Once a host has been forgotten it will have to be re-installed. WARNING: This operation is irreversible. Type 'yes' to continue yes [23:44 xcp-ng-1 ~]# xe sr-scan uuid=1d1eea3e-95e7-a0fa-958e-7ddb2e557401 [23:46 xcp-ng-1 ~]# xe task-list [23:46 xcp-ng-1 ~]# xe task-list [23:49 xcp-ng-1 ~]# xe task-list uuid ( RO) : 2af0df13-89ce-5ea2-5e8e-2902f8fa0b1c name-label ( RO): Async.SR.update name-description ( RO): status ( RO): success progress ( RO): 1.000 uuid ( RO) : 48dbf4bd-09f1-10f6-5db1-4dac86c375cf name-label ( RO): Async.SR.update name-description ( RO): status ( RO): success progress ( RO): 1.000 [00:01 xcp-ng-1 ~]# -
RE: Problems with existing pool, problems migrating to new pool
@Danp said in Problems with existing pool, problems migrating to new pool:
a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
That pulled it up. Apparently that's associated with the host that's down, though it's not the uuid produced when typing xe host-list.

Which brings up a question: what is the best way to remove this host from the pool?
Do I do it from XO? From the command line? Using this a60 uuid, or the one that xe host-list produces?
-
RE: Problems with existing pool, problems migrating to new pool
That doesn't map to a host or a vm as far as I can tell:
[18:17 xcp-ng-1 ~]# xe vm-list | grep a60
[18:17 xcp-ng-1 ~]# xe host-list
uuid ( RO) : 78913a9f-e36e-419e-9e84-9fc43127558f
name-label ( RW): xcp-ng-1
name-description ( RW): Default installuuid ( RO) : 0840e7a3-e82a-4f48-803b-08c3a082af88
name-label ( RW): xcp-ng-3
name-description ( RW): Default installuuid ( RO) : 7a49f91f-4701-4a95-b73c-be8235878ecf
name-label ( RW): xcp-ng-2
name-description ( RW): Default installI went through all the output of the xe vm-list and nothing there matched, so I have no idea what that might be referencing.
And you're correct: xe task-list just comes up empty when I run the command, so no coalesce ongoing.
So all I need to do is run:
xe host-forget uuid=0840e7a3-e82a-4f48-803b-08c3a082af88 ? Then run the sr-scan again?
(Because the host named xcp-ng-3 is the one that's offline)
Editing for Clarification on that uuid
Where else might I look?
[18:23 xcp-ng-1 ~]# xe host-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:23 xcp-ng-1 ~]# xe vm-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe sr-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe vdi-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe network-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe pif-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe vif-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:24 xcp-ng-1 ~]# xe pbd-list uuid=a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8
[18:25 xcp-ng-1 ~]# -
RE: Problems with existing pool, problems migrating to new pool
Thanks. I triggered it from the command line as you suggested, and didn't see any changes.
About 5 minutes later, taking a tail of /var/log/SMlog I found the following, which suggests a host being offline is causing the delay here:
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] Found 2 orphaned vdis
Jun 10 17:53:24 xcp-ng-1 SM: [31273] lock: tried lock /var/lock/sm/1d1eea3e-95e7-a0fa-958e-7ddb2e557401/sr, acquired: True (exists: True)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] Found 2 VDIs for deletion:
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] 562be49d(300.000G/607.790M)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] c2be12c4(100.000G/1.634G)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] Deleting unlinked VDI 562be49d(300.000G/607.790M)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] Checking with slave: ('OpaqueRef:a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8', 'nfs-on-slave', 'check', {'path': '/var/run/sr-mount/1d1eea3e-95e7-a0fa-958e-7ddb2e557401/562be49d-2210-4ea1-a936-4415e5981fcd.vhd'})
Jun 10 17:53:24 xcp-ng-1 SM: [31273] lock: released /var/lock/sm/1d1eea3e-95e7-a0fa-958e-7ddb2e557401/sr
Jun 10 17:53:24 xcp-ng-1 SM: [31273] lock: released /var/lock/sm/1d1eea3e-95e7-a0fa-958e-7ddb2e557401/running
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] GC process exiting, no work left
Jun 10 17:53:24 xcp-ng-1 SM: [31273] lock: released /var/lock/sm/1d1eea3e-95e7-a0fa-958e-7ddb2e557401/gc_active
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] In cleanup
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] SR 1d1e ('TrueNas1VM') (370 VDIs in 16 VHD trees): no changes
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] ~~~~~~~~~~~~~~~~~~~~
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] ***********************
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] * E X C E P T I O N *
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] ***********************
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] gc: EXCEPTION <class 'XenAPI.Failure'>, ['HOST_OFFLINE', 'OpaqueRef:a60d10b4-b4d0-4bae-a5ab-f8f6b9c03ca8']
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2961, in gc
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] _gc(None, srUuid, dryRun)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2846, in _gc
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] _gcLoop(sr, dryRun)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2813, in _gcLoop
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] sr.garbageCollect(dryRun)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 1651, in garbageCollect
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] self.deleteVDIs(vdiList)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2225, in deleteVDIs
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] SR.deleteVDIs(self, vdiList)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 1665, in deleteVDIs
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] self.deleteVDI(vdi)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2320, in deleteVDI
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] self._checkSlaves(vdi)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2333, in _checkSlaves
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] self._checkSlave(hostRef, vdi)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/opt/xensource/sm/cleanup.py", line 2342, in _checkSlave
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] text = _host.call_plugin(call)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 264, in call
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] return self.__send(self.__name, args)
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 160, in xenapi_request
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] result = _parse_result(getattr(self, methodname)(full_params))
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] File "/usr/lib/python2.7/site-packages/XenAPI.py", line 238, in _parse_result
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] raise Failure(result['ErrorDescription'])
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273]
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] ~~~~~~~~~~~~~~~~~~~~*
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273] * * * * * SR 1d1eea3e-95e7-a0fa-958e-7ddb2e557401: ERROR
Jun 10 17:53:24 xcp-ng-1 SMGC: [31273]
[17:54 xcp-ng-1 ~]#If that's the case - that only 2 of the 3 members of the pool are online so the coalesce won't occur, does it make the most sense to just remove the host that's forgotten its network settings from the pool, and rescan?
-
Problems with existing pool, problems migrating to new pool
I'm not quite sure where to put this, so mods please move as appropriate:
Background
- Existing pool running 8.1.0 with three hosts.
- Host #3 went offline about 10 days ago or so. Spent an hour diagnosing, and it turns out the problem was a bad network cable. Or so it seemed.
- Brought the host back online, got my VMs that had been locked to start on new hosts. Host #3 remained empty because I didn't trust it.
Decided now is the time to migrate to new hardware, and so I ordered a couple of boxes and set up a new pool, on a separate TrueNAS host, and tried to migrate.
Current Problem Set
- I've got host #3 offline on the origin pool, and when I log into its console it tells me there's no management interface installed. In fact, none of its NICs are configured, so I've got localhost up and that's it.
- I can't migrate my VMs running on the old hosts easily, because when I try and trigger a backup to the new storage it tells me the snapshot chain is too long. And it, because I'm a bit of an idiot and I've got too many snapshots (because waaaaaaay back when I thought rolling snapshots were the correct way to backup XCP-ng, and a couple of months back I accidentally turned on the old XO VM that I should have deleted and it went back to trying rolling snapshots again.)
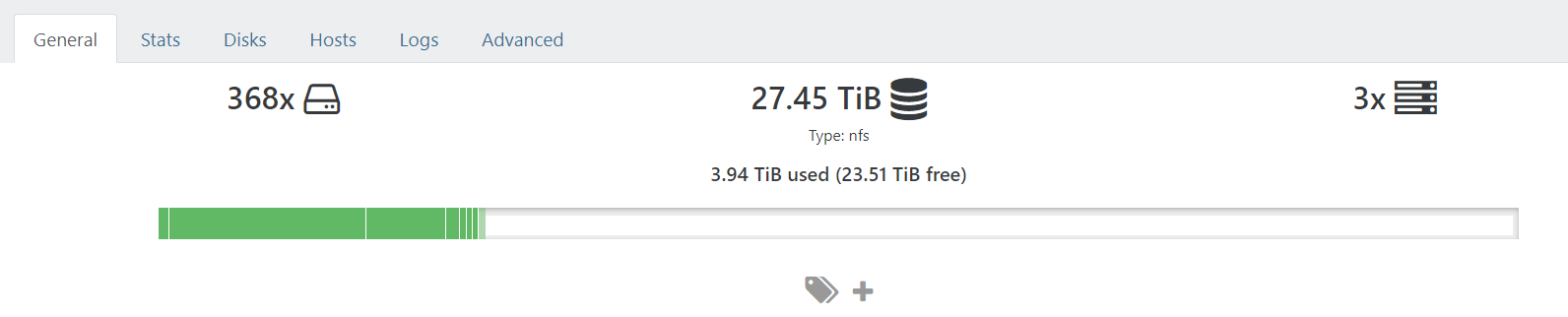
- So I deleted a lot of snapshots. All from one VM, 5 from another. And now when I check the advanced tab on the storage repository for the old pool, it shows 68 VDIs waiting to coalesce. But I see no real coalescing activity on the storage - it's mostly idle, just running my VMs happily.
TL/DR So I've got an old pool (8.1.0) with one host offline, attached to NAS storage with lots of 100GB to 1TB VDIs to coalesce which isn't coalescing, and the snapshot chains are too long to perform a simple migration/backup to my new cluster. Oh, and there's not enough memory on a single of my remaining hosts to run all my VMs.
So, what's the best path forward with the migration?
- If I remove the non-responsive pool member is the pool more likely to start coalescing?
- If I bring down a VM, then upgrade the pool, will the move to 8.2 help with coalescing?
- Should I ditch all these fancy ideas and do something basic like shut down a VM, download it to a separate machine, then manually import that to the new cluster?
- Maybe reconfiguring the non-responsive host from the old pool makes sense, either reconfiguring the management interface from the command line, or ejecting/re-imaging it and reconnecting it to the pool?
I don't know. Mostly, I want to move off the old hardware and get into the new pool, and I feel like I keep walking into invisible walls in the process.
-
Best way to migrate VMs from old pool to new?
I have an old pool running XCP-ng 8.1.0, and as the hardware is getting long of tooth I've got a couple of new hosts configured that I'm trying to migrate to, running XCP-ng 8.2.1. These are plugged into a gigabit switch for management and the DMZ the VMs are on, and a pair of 10G switches are used for the storage network, with VM storage being provided by TrueNAS. Probably pretty straightforward.
I run a couple of forums on this cluster, and I'd like to avoid down-time as I migrate to avoid user complaints. So I'm looking at the best way to do that.
I've used the warm migration tool before and this would be a wonderful way to move the VMs, but it looks like 8.1.0 is just too old to support warm migration.
So the question: how to transfer the VMs with the least down-time possible?
Right now I've got 2 ideas:
-
Get a trial of XOA and let it update the pool to 8.2.1, then warm migrate. I've been on the fence here as far as paying for XOA anyway, but haven't because it's essentially a hobby cluster. Can XOA perform an update of the XCP-ng hosts, or will I be setting up an FTP server and updating this the way I did with Xenserver a decade ago?
-
Create a new VM on my new cluster, with access to the 10G network, and figure out hardware pass-through so I can plug in a USB SSD drive large enough to hold the VMs I'm migrating, and just download the virtual machines then upload them to the new server. I've never done this but I think it should probably work.
Maybe there's a third option I haven't figured out yet.
What would you do?
-
-
Stupid question on deleting old snapshots.
So, originally I was running XO on my cluster, and I ran into some problems after a power failure, and as part of the solution I spun up a newer version of XO.
As part of that I've got lots of snapshots tied to an old (and overly complicated) backup job that I'm not using any more. As I'm trying to simplify the backup routine (with the old XO not running, because why run two?) I'm getting errors that some VMs have too many snapshots. I'm looking at one VM with 22 snapshots stored.
Now, what I want to do is simply go to the VM listing in XO, move to the snapshots tab, and delete everything other than the last few that are the most recent. Then create my new backup job.
For some reason I'm not feeling very confident, though. Is there any reason not to do this?