Timestamp lost in Continuous Replication

-
we had as many "VMs with a timestamp in the name" as number of REPLICAs, and multiple snapshot on source VM
now we have "one Replica VM with multiple snapshots" ? Veeam-replica-style...we didn't look at veeam , but it's reassuring to see that we converge toward the solutions used elsewhere
it shouldn't change anything on the source
I am currently doing more test to see if we missed somethingedit: as an additional beenfits it should use less space on target it you have a retention > 1 since we will only have one active disk
-
Hello everyone,
I’m not sure if my information is useful, but I’m experiencing the same problem. I am using continuous replication between two servers with a retention of 4.
Previously, four VM replicas were created, each with a timestamp in the name. With the current version, four VMs are created with identical names.My environment:
XO: from source commit 598ab
xcp-ng: 8.3.0 with the latest patchesMy backup job:
Name of backup job: replicate_to_srv002
Source server: srv003
Target server: srv002
VM name: privat
Retention: 4Result on the target server:
4 VMs with the name "[XO Backup replicate_to_srv002] privat - replicate_to_srv002", where only the newest one contains a snapshot named: "privat - replicate_to_srv002 - (20260318T083542Z)"Additionally, full backups are created on every run of the backup job, and no deltas are being used.
If I can help with any additional information, I’d be happy to do so.
Best regards,
Simon -
-
@Pilow
actually it looks like this: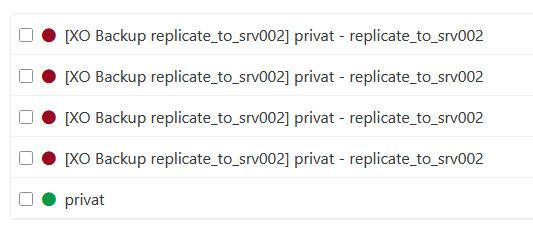
edit:
Log of last run:
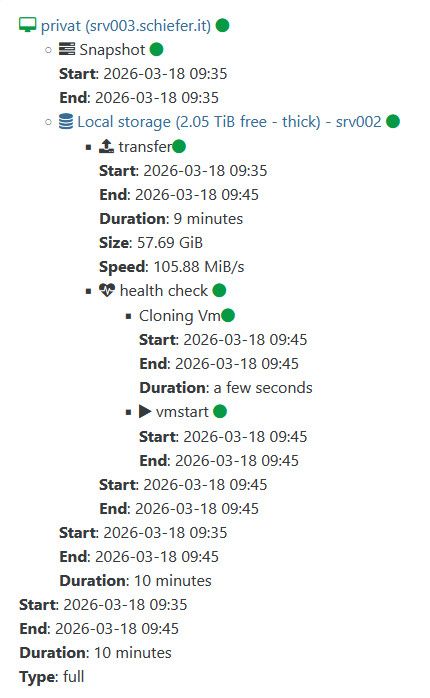
{ "data": { "mode": "delta", "reportWhen": "failure" }, "id": "1773822934377", "jobId": "a95ac100-0e20-49c5-9270-c0306ee2852f", "jobName": "replicate_to_srv002", "message": "backup", "scheduleId": "1014584a-228c-4049-8912-51ab1b24925a", "start": 1773822934377, "status": "success", "infos": [ { "data": { "vms": [ "224a73db-9bc6-13d6-cc8e-0bf22dbede73" ] }, "message": "vms" } ], "tasks": [ { "data": { "type": "VM", "id": "224a73db-9bc6-13d6-cc8e-0bf22dbede73", "name_label": "privat" }, "id": "1773822936247", "message": "backup VM", "start": 1773822936247, "status": "success", "tasks": [ { "id": "1773822937378", "message": "snapshot", "start": 1773822937378, "status": "success", "end": 1773822940361, "result": "d0ba1483-f5ae-ce72-fb4f-dbd9eafbf272" }, { "data": { "id": "8205e6c4-4d8f-69d9-6315-9ee89af8e307", "isFull": true, "name_label": "Local storage", "type": "SR" }, "id": "1773822940361:0", "message": "export", "start": 1773822940361, "status": "success", "tasks": [ { "id": "1773822942354", "message": "transfer", "start": 1773822942354, "status": "success", "tasks": [ { "id": "1773823497635", "message": "target snapshot", "start": 1773823497635, "status": "success", "end": 1773823500290, "result": "OpaqueRef:53bceb07-a69c-504d-e824-28f5384cb763" } ], "end": 1773823500290, "result": { "size": 61941481472 } }, { "id": "1773823501512", "message": "health check", "start": 1773823501512, "status": "success", "tasks": [ { "id": "1773823501515", "message": "cloning-vm", "start": 1773823501515, "status": "success", "end": 1773823504720, "result": "OpaqueRef:43e9644f-fc99-963a-4a54-da3b845e823b" }, { "id": "1773823504722", "message": "vmstart", "start": 1773823504722, "status": "success", "end": 1773823545662 } ], "end": 1773823549312 } ], "end": 1773823549312 } ], "end": 1773823549319 } ], "end": 1773823549319 } -
-
@florent
Yes, that is absolutely correct. I have a pool with two members without shared storage. Some VMs run on the master, and some on the second pool member. I replicate between the pool members so that, if necessary, I can start the VMs on the other member. This may not be best practice. -
@kratos you probably heard the sound of my head hitting my desk when I found the cause
the fix is in review, you will be able to use it in a few hours -
@florent
I’m a developer myself, so I can totally relate—just when you think everything is working perfectly, someone like me comes along
I’m really glad I could help contribute to finding a solution, and I’ll report back once I’ve tested the new commit. Thanks a lot for your work.However, this does raise the question for me: is my use case for continuous replication really that unusual?
-
@kratos no, it's not that rare. I even saw in the wild replication on the same storage (wouldn't recommend it , though )
the cross pool replication is a little harder since the objects are each split on their own xen api, so the calls must be routed to the right one
We tested the harder part, not the mono xapi case -
-
updated to
f5468and it seems to work fine in my home lab lab
I will update my homelab "production" laterI have retention of 2
In XO I only see 1 VM and I think this is intended
I get 2 snaps and I can restore 2 different VMs from themI think You nailed it
edit: And delta is back
-
@ph7 that is a good news
thank you for your patience and help -
P ph7 referenced this topic on
-
I observed similar behaviour.
Two pools. Pool A composed of two hosts. Pool B is single-host. B runs a VM with XO from source. Two VMs on host A1 (on local SR), one VM on host
B1A2 (on local SR).Host A2 has a second local SR (separate physical disc) used as the target for a CR job.
CR job would back up all four VMs to the second local SR on host A2.
The behaviour observed was that, although the VM on B would be backed up (as expected) as a single VM with multiple snapshots (up to the 'replication retention'), the three other VMs on the same pool as the target SR would see a new full VM created for each run of the CR job. That rather quickly filled up the target SR.
I noticed the situation was corrected by a commit on or about the same date reported by @ph7.
Incidentally, whatever broke this, and subsequently corrected it, appears to have corrected another issue I reported here. I never got a satisfactory answer regarding that question. Questions were raised about the stability of my test environment, even though I could easily reproduce it with a completely fresh install.
Thanks for the work!
edit: Correction
B1A2 -
I observed similar behaviour.
Two pools. Pool A composed of two hosts. Pool B is single-host. B runs a VM with XO from source. Two VMs on host A1 (on local SR), one VM on host
B1A2 (on local SR).Host A2 has a second local SR (separate physical disc) used as the target for a CR job.
CR job would back up all four VMs to the second local SR on host A2.
The behaviour observed was that, although the VM on B would be backed up (as expected) as a single VM with multiple snapshots (up to the 'replication retention'), the three other VMs on the same pool as the target SR would see a new full VM created for each run of the CR job. That rather quickly filled up the target SR.
I noticed the situation was corrected by a commit on or about the same date reported by @ph7.
Incidentally, whatever broke this, and subsequently corrected it, appears to have corrected another issue I reported here. I never got a satisfactory answer regarding that question. Questions were raised about the stability of my test environment, even though I could easily reproduce it with a completely fresh install.
Thanks for the work!
edit: Correction
B1A2sometimes it's hard to find a n complete explanation without connecting to the hosts and xo, and going through a lot of logs , which is out of the scope of community support
I am glad the continuous improvement of the code base fixed the issue . We will release today a new patch, because migrating from 6.2.2 to 6.3 for a full replication ( source user that updated to the intermediate version are not affected )
-
P ph7 referenced this topic on
-
Please excuse my late reply - I was on a fishing trip in Spain in the meantime. However, I did have time to test extensively and could no longer identify any issues.
Thank you for all your work.
P.S.:
@Pilow Thanks for the explanation — I’ll give this some more thought. -
Thank you for your feedback @kratos !
-
 O olivierlambert marked this topic as a question on
O olivierlambert marked this topic as a question on
-
O olivierlambert has marked this topic as solved on
")
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login