Delta backup fails for specific vm with VDI chain error
-
We have an option to force it, but this is a protection and that just display in plain sight your issue with this SR.
I still don't know the root cause, I think it will be hard to know more without accessing the host myself remotely and do a lot of digging.
-
I now have migrated the VM's disk to NFS.
xapi-explore-sr looks like this (--full not working most of the time):
NASa-sr (3 VDIs) └─┬ customer server 2017 0 - 6d1b49d2-51e1-4ad4-9a3b-95012e356aa3 - 500.94 Gi └─┬ customer server 2017 0 - f2def08c-cf2e-4a85-bed8-f90bd11dd585 - 43.05 Gi └── customer server 2017 0 - 9ad7e1c4-b7cb-4a1b-bb74-6395444da2b7 - 43.04 Gi
On the NFS it looks like this:
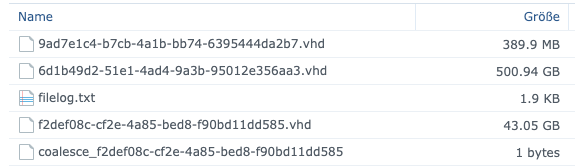
I'll wait a second for a coalesce job that is currently in progress...
OK, the job has finished. No VDIs to coalesce in the advanced tab.
NFS looks like this:
xapi-explore-sr --full says:
NASa-sr (1 VDIs) └── Customer server 2017 0 - 9ad7e1c4-b7cb-4a1b-bb74-6395444da2b7 - 43.04 Gi -
So coalesce is working as expected on the NFS SR. For some reason, your original LVM SR can't make a proper coalesce.
-
But only for this vm, all the others are running (and backupping) fine.
How are my chances that coalesce will work fine again if I migrate the disk back to local lvm sr? -
Try again now you got a clean chain
")
-
@olivierlambert Could this patch be the solution?
It would validate if this would really fix the problem.[XSO-887](https://bugs.xenserver.org/browse/XSO-887?focusedCommentId=17173&page=com.atlassian.jira.plugin.system.issuetabpanels%3Acomment-tabpanel) -
This patch then:
--- /opt/xensource/sm/cleanup.py.orig 2018-08-17 17:19:16.947351689 +0200 +++ /opt/xensource/sm/cleanup.py 2018-10-05 09:30:15.689685864 +0200 @@ -1173,16 +1173,24 @@ def _doCoalesce(self): """LVHD parents must first be activated, inflated, and made writable""" + self.sr.lock() + acquired = True try: self._activateChain() self.sr.lvmCache.setReadonly(self.parent.fileName, False) self.parent.validate() + self.sr.unlock() + acquired = False self.inflateParentForCoalesce() VDI._doCoalesce(self) finally: + if acquired: + self.sr.unlock() self.parent._loadInfoSizeVHD() self.parent.deflate() + self.sr.lock() self.sr.lvmCache.setReadonly(self.parent.fileName, True) + self.sr.unlock() def _setParent(self, parent): self._activate() @@ -1724,33 +1732,41 @@ # need to finish relinking and/or refreshing the children Util.log("==> Coalesce apparently already done: skipping") else: - # JRN_COALESCE is used to check which VDI is being coalesced in - # order to decide whether to abort the coalesce. We remove the - # journal as soon as the VHD coalesce step is done, because we - # don't expect the rest of the process to take long - self.journaler.create(vdi.JRN_COALESCE, vdi.uuid, "1") - vdi._doCoalesce() - self.journaler.remove(vdi.JRN_COALESCE, vdi.uuid) + self.lock() + try: + # JRN_COALESCE is used to check which VDI is being coalesced in + # order to decide whether to abort the coalesce. We remove the + # journal as soon as the VHD coalesce step is done, because we + # don't expect the rest of the process to take long + self.journaler.create(vdi.JRN_COALESCE, vdi.uuid, "1") + finally: + self.unlock() - util.fistpoint.activate("LVHDRT_before_create_relink_journal",self.uuid) + vdi._doCoalesce() - # we now need to relink the children: lock the SR to prevent ops - # like SM.clone from manipulating the VDIs we'll be relinking and - # rescan the SR first in case the children changed since the last - # scan - self.journaler.create(vdi.JRN_RELINK, vdi.uuid, "1") + self.lock() + try: + self.journaler.remove(vdi.JRN_COALESCE, vdi.uuid) + util.fistpoint.activate("LVHDRT_before_create_relink_journal",self.uuid) + # we now need to relink the children: lock the SR to prevent ops + # like SM.clone from manipulating the VDIs we'll be relinking and + # rescan the SR first in case the children changed since the last + # scan + self.journaler.create(vdi.JRN_RELINK, vdi.uuid, "1") + finally: + self.unlock() self.lock() try: self.scan() vdi._relinkSkip() + + vdi.parent._reloadChildren(vdi) + self.journaler.remove(vdi.JRN_RELINK, vdi.uuid) + self.deleteVDI(vdi) finally: self.unlock() - vdi.parent._reloadChildren(vdi) - self.journaler.remove(vdi.JRN_RELINK, vdi.uuid) - self.deleteVDI(vdi) - def _coalesceLeaf(self, vdi): """Leaf-coalesce VDI vdi. Return true if we succeed, false if we cannot complete due to external changes, namely vdi_delete and vdi_snapshotWell, I haven't read it in details, you can try to see if it's easy to apply and then restart toolstack.
-
I migrated the disk back to the local lvm sr.
Guess what...

rigel: sr (25 VDIs) ├─┬ customer server 2017 0 - 972ef16c-8d47-43f9-866e-138a6a7693a8 - 500.98 Gi │ └─┬ customer server 2017 0 - 4e61f49f-6598-4ef8-8ffa-e496f2532d0f - 0.33 Gi │ └── customer server 2017 0 - 66ab0cf5-ff10-4a3d-9f87-62b1e7be7f91 - 500.98 Gi -
Are you able to delete/recreate this SR?
-
@olivierlambert Do you think both hosts' sr could suffer from the same bug?
-
I did a vm copy today (to have at least some sort of current backup) and while it was copying I was able to also run the delta backup job. Afterwards I found a vdi coalesce chain of 1 and when I checked after a while there were no coalesce jobs queued.
At this moment the weekly full backup job is running, so I expect to have some "regular" backups of the vm today and will monitor what happens on the coalescing side. I'm not getting my hopes too high, though")
-
After the backups were done, I saw the usual problem, but this time the system was able to correctly coalesce it seems. The nightly delta backup finished okay and until now the problem hasn't reappeared.
-
@mbt so what changed since the situation in your initial problem?
-
@olivierlambert said in Delta backup fails for specific vm with VDI chain error:
@mbt so what changed since the situation in your initial problem?
Nothing. No system reboot, no patch installations, no hardware reconfiguration, no XCP-ng server reconfoguration, ..
I just
- triggered the vm full copy in xo to the other host
- while the data was transferrred coalescing of the vm picked up until there were no outstanding jobs
- while the full backup was still running I started a backup-ng full backup job for the vm which worked
- I also manually started the delta backup job which also worked
- afterwards there was a short period of time where there were outstanding coalesce jobs for the dvi (depth 2) and I thought "here we go again.."
- but the system got it done and now everything seems to be okay for the moment.
I wish I had an explanation.
-
After the weekend the vm's problem reappeared.
So I'm almost certain it has something to do with the backup jobs, because the problem appears now fr the third time in a row after a weekend where everything was okay.Mo-Fr a delta backup job is running at 11pm, on Sun 00:01am a full backup job is running. Both jobs backup all of the pool's vms, except xo and metadata which are fully backuped daily.
The last delta on Friday and the last full backup on Sunday finished i.O.
-
Can you recap the kind of backup you are doing? Delta? Have you change concurrency? What's the SR type you are using?
-
@mbt ,
Thankfully the problem that I was having (very similar to your) has not returned. I was able to unwind all the VM by DR copying them to a new SR and then deleting the originals.
I am really interested in knowing what has caused yours to return because it has the possibility on my stack as well.
Only thing I can tell you about my setup is that I am doing incremental backups every night on about 200 VM's. Some of the VM's I replicate XSite, but I only do that on the weekend and I make sure that neither job can run at the same time.
What I have not done is a full backup on the VM's as a separate job. I have my full backup interval set to 30, so roughly once a month it will cause a full backup vrs incremental. I also know that some of the VM's have already done this and the problem did not return.
~Peg
-
- job 1 - type: delta - all VMs except xo - Mo-Fr 11:01 pm - concurrency: 1 - target: NFS repo on NAS1
- job 2 - type: full zstd - all VMs except xo - Sun 00:01 am - concurrency 1 - target: NFS repo on NAS2
- job 3 - type: full zstd - xo only - xo VM only - daily 10:00 pm - concurrency 1 - target: NFS repo on NAS1
- job 4 - type: pool metadata - daily 10:01 pm - target: NFS repo on NAS1
-
P.S.:
I gave my latest "trick" another run:
Did a full copy of the VM within xo to the other host. While that job ran, I started the delta backup that finished OK. After the copy was done I deleted the copy and saw - as last time - that the host was coalescing. After finishing the sr's advanced tab is empty again and stayed empty. -
Hi ! We are experiencing these kind of problems because we activated Continous Replication and frequency was way too low.
Now I want to eliminate all those files in the chain, can I do it manually from XCP-NG Center or XOA ?
Thanks !!!
Hello! It looks like you're interested in this conversation, but you don't have an account yet.
Getting fed up of having to scroll through the same posts each visit? When you register for an account, you'll always come back to exactly where you were before, and choose to be notified of new replies (either via email, or push notification). You'll also be able to save bookmarks and upvote posts to show your appreciation to other community members.
With your input, this post could be even better 💗
Register Login